1 前言
本篇文章主要来说明下代码模块的设计。像我们这种菜鸟级别,只有平时多读读源码,多研究和探讨其中的设计才可能提升自己,写出高质量的代码。
没有最好的设计,只有更好的设计,所以在发表我自己的愚见的同时,希望小伙伴们相互探讨更好的设计,有探讨才有更大的进步。
2 题目及分析
我们维护了一个数据中心,对外提供查询API,如何能让用户随意的添加查询条件,而不用修改后台的查询代码呢?用户如何配置查询条件,从而达到如下的sql效果呢?:
a.name='lg' or b.age>12
b.id in (12,34,45)
c.updateTime>'2015-3-28' and (b.id=2 or d.age<23)
e.age>f.age
2.1 查询参数的传递方式
我们作为API设计者,该如何让用户方便的传递他们任意的查询需求呢?这是我们要思考的地方。
目前来看比较好的方式莫过于:用户通过json来表达他们的查询需求。
2.2 查询的本质分析
从上面的查询来看,我们可以总结出来查询条件无非就是某个字段满足什么样的条件。这里有三个对象:
- 查询的字段 如 b.age
- 条件值 如 12
- 怎样满足条件值 如 >
2.3 查询的配置分析
这样我们就可以清晰明了了,一个查询条件无非就是三个内容,所以可以如下配置:
{
"columns":"b.age",
"oper":">",
"value":12
}
很显然,上面的确很麻烦,我们无非是要表达这三个内容,所以就要简化配置:
{
"b.age":12,
"oper":">"
}
还是不够简化,如何把操作符 > 也放置进去呢?如下
{
"b.age@>":12
}
这样我们就可以把三个对象表达清楚了,将查询的字段和操作符合并起来作为key,并使用分隔符@分割两者,条件值作为value。这样就做到了,非常简化的查询配置。
接下来又面临一个问题,如何表达查询条件之间的and or 关系呢?即如何表达下面的内容呢?
c.age>14 and (b.id=2 or d.age<23)
借鉴mongodb的查询方案,可以如下配置:
{
"c.age@>":14,
"$or":{
"b.id@=":2,
"d.age@<":23
}
}
通过配置一个$or作为key表明里面的几个查询条件是or的关系,如果是$and表明里面的查询条件之间是and的关系,外层默认是and的关系。
同时我们再回顾下,mongodb所作出的查询设计,也是通过用户配置json形式来表达查询意图,但是我们来看下它是如何查询
a.age>12 对应的mongodb的查询方式为:
{
a.age : {
$gt : 22
}
}
我们的查询方式是
{
"a.age@>":22
}
虽然看似我们的更加简单,mongodb的更加繁琐,主要是mongodb认为对于一个字段,可以有多个查询条件的,为了支持更加复杂的查询,如下:
{
a.age : {
$lt :24,
$gt : 17
}
}
然而我们也可以对此进行拆分,如下,同样满足:
{
"a.age@>":17,
"a.age@<":24,
}
各有各的好处和缺点,我就是我,颜色不一样的烟火。哈哈。。。
3 代码设计与实现
3.1 解析器接口的设计
对题目进行分析完了之后,就要考虑如何实现这样的json配置到sql的转化。实现起来不难,最重要的是如何做出一个高扩展性的实现?
再来看下下面的例子:
{
"a.name@=":"lg",
"b.age@>":12,
"c.id@in":[12,13,14],
"d.time@time>":"2015-3-1"
}
其实就是针对每个自定义的操作符进行相应的处理,所以就有了解析器接口:
public interface SqlParamsParser {
//这里表示该解析器是否支持对应的操作符
public boolean support(String oper);
public String getParams(String key,Object value,String oper);
public SqlParamsParseItemResult getParamsResult(String key,Object value,String oper);
}
其中SqlParamsParseItemResult,则是把解析后的结果分别存储起来,而不是直接拼接成一个字符串,主要为了直接拼接字符串式的sql注入,它的内容如下:
public class SqlParamsParseItemResult {
private String key;
private String oper;
private Object value;
}
上面的key oper value 则是解析后的内容。下面举例说明
以"b.age@>“:12 为例,其中getParams方法中的 key就是b.age, value就是12, oper就是> 而这个方法的返回的字符串结果为:
b.age>12
返回的SqlParamsParseItemResult存储的内容为分别为 key=b.age ; oper=> ; value=12
以"c.id@in”:[12,13,14]为例,其中getParams方法中的 key就是c.id,value就是一个List集合,oper就是in ,这个方法的返回结果为:
c.id in (12,13,14)
返回的SqlParamsParseItemResult存储的内容为分别为 key=c.id ; oper=in ; value=(12,13,14)
以"d.time@time>“:“2015-3-1"为例,其中getParams方法中的 key就是c.id,value就是一个List集合,oper就是in,这个方法的返回结果为:
unix_timestamp(d.time) > 1425139200 (2015-3-1对应的秒数)
返回的SqlParamsParseItemResult存储的内容为分别为 key=unix_timestamp(d.time) ; oper=> ; value=1425139200
3.2 解析器接口的抽象类
解析器有很多相同的地方,这就需要我们进行抽象,抽出共性部分,留给子类去实现不同的部分。所以有了抽象类AbstractSqlParamsParser
有哪些共性部分和非共性部分呢?
- 共性部分: 就是support方法。每个解析器支持某几种操作符,所以判断该解析器是否支持当前的操作符的逻辑是共同的,所以如下:
public abstract class AbstractSqlParamsParser implements SqlParamsParser{ private String[] opers; private boolean ignoreCase=true; protected void setOpers(String[] opers){ this.opers=opers; } protected void setIgnoreCase(boolean ignoreCase){ this.ignoreCase=ignoreCase; } @Override public boolean support(String oper) { if(opers!=null && oper!=null){ for(String operItem:opers){ if(ignoreCase){ operItem=operItem.toLowerCase(); oper=oper.toLowerCase(); } if(operItem.equals(oper)){ return true; } } } return false; } }opers属性表示当前解析器所支持的所有操作符。ignoreCase表示在匹配操作符的时候是否忽略大小写。这两个属性都设置成private,然后对子类开放了protected类型的set方法,用于子类来设置这两个属性。
- 非共性部分:留出了doParams方法供子类来具体实现
@Override public SqlParamsParseItemResult getParamsResult(String key, Object value, String oper) { return doParams(key, processStringValue(value), oper); } protected abstract SqlParamsParseItemResult doParams(String key, Object value, String oper);
3.3 解析器接口的实现类
目前内置了几个常用的解析器实现,类图如下: 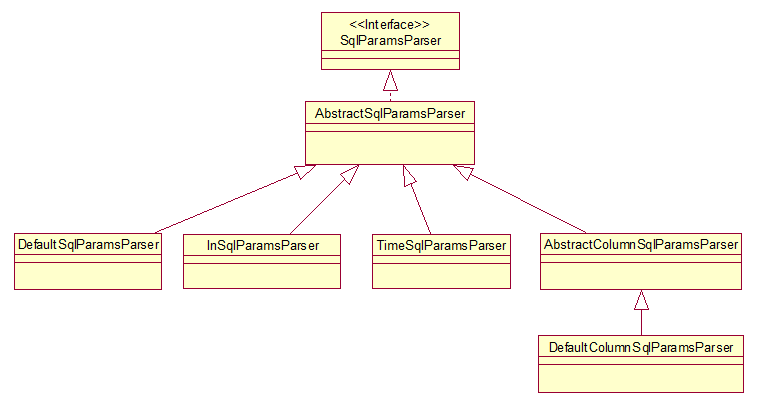
以TimeSqlParamsParser为例来简单说明下:
它主要是用于解析如下形式的:
{
"d.time@time>":"2015-3-1"
}
最终想达到的效果是:
unix_timestamp(d.time) > 1425139200
它的解析过程如下:
/**
* 以d.time@time>'2015-3-1'为例
* 初始参数 key=d.time; value='2015-3-1'; oper=time>
* 解析后的key=unix_timestamp(d.time); value=1425139200('2015-3-1'对应的秒数); oper=>
*/
@Override
protected SqlParamsParseItemResult doParams(String key, Object value, String oper) {
String timeKey="unix_timestamp("+key+")";
String realOper=oper.substring(4+fullTimeFlag.length());
if(value instanceof String){
String tmp=(String)value;
Assert.isLarger(tmp.length(),2,"时间参数不合法");
//默认进行了字符串处理,即加上了'',现在要去掉,然后解析成时间的秒数
value=tmp.substring(1,tmp.length()-1);
try {
SimpleDateFormat format=new SimpleDateFormat(timeFormat);
Date date=format.parse((String)value);
value=date.getTime()/1000;
} catch (ParseException e) {
e.printStackTrace();
throw new IllegalArgumentException("timeFormat为"+timeFormat+";value="+value+";出现了解析异常");
}
}else{
Assert.isInstanceof(value,Number.class,"时间参数必须为时间的秒数");
}
return new SqlParamsParseItemResult(timeKey,realOper,value);
}
解析过程其实就是对key value oper 进行了不同程度的转换。
同时TimeSqlParamsParser还支持其他时间形式的解析,如"2015-3-1 12:23:12”,只需如下方式创建一个解析器:
new TimeSqlParamsParser("yyyy-MM-dd HH:mm:ss","full_")
然后他就能够解析下面的形式:
{
"d.time@full_time>":"2015-3-1 12:23:12"
}
同时又能保留原有的形式,两者互不干扰。
4 DefaultSqlParamsHandler使用解析器
有了解析器的一系列实现,下面就需要一个综合的类来使用这些解析器。这就是DefaultSqlParamsHandler:
4.1 注册使用解析器
public class DefaultSqlParamsHandler {
private List<SqlParamsParser> sqlParamsParsers;
public DefaultSqlParamsHandler(){
sqlParamsParsers=new ArrayList<SqlParamsParser>();
sqlParamsParsers.add(new DefaultSqlParamsParser());
sqlParamsParsers.add(new InSqlParamsParser());
sqlParamsParsers.add(new TimeSqlParamsParser());
sqlParamsParsers.add(new TimeSqlParamsParser("yyyy-MM-dd HH:mm:ss","full_"));
sqlParamsParsers.add(new DefaultColumnSqlParamsParser());
}
内部已经注册了几个解析器。同时需要对外留出注册自定义解析器的方法:
public void registerSqlParamsHandler(SqlParamsParser sqlParamsParser){
if(sqlParamsParser!=null){
sqlParamsParsers.add(sqlParamsParser);
}
}
public void registerSqlParamsHandler(List<SqlParamsParser> sqlParamsParsers){
if(sqlParamsParsers!=null){
for(SqlParamsParser sqlParamsParser:sqlParamsParsers){
registerSqlParamsHandler(sqlParamsParser);
}
}
}
4.2 解析过程
这个过程不仅需要使用已经注册的解析器来解析,还包含对解析条件之间的and or 关系的递归处理。代码如下,不再详细说明:
private SqlParamsParseResult getSqlWhereParamsResultByAndOr(Map<String,Object> params,String andOr,
boolean isPlaceHolder,SqlParamsParseResult sqlParamsParseResult){
if(params!=null){
String andOrDelititer=" "+andOr+" ";
for(String key:params.keySet()){
Object value=params.get(key);
if(value instanceof Map){
//这里需要进行递归处理嵌套的查询条件
SqlParamsParseResult SqlParamsParseResultModel=null;
if(key.equals(andKey)){
SqlParamsParseResultModel=processModelSqlWhereParams((Map<String,Object>)value,AND,isPlaceHolder);
}else if(key.equals(orKey)){
SqlParamsParseResultModel=processModelSqlWhereParams((Map<String,Object>)value,OR,isPlaceHolder);
}
if(SqlParamsParseResultModel!=null && StringUtils.isNotEmpty(SqlParamsParseResultModel.getBaseWhereSql())){
sqlParamsParseResult.addSqlModel(andOrDelititer);
sqlParamsParseResult.addSqlModel("("+SqlParamsParseResultModel.getBaseWhereSql()+")");
sqlParamsParseResult.addArguments(SqlParamsParseResultModel.getArguments());
}
}else{
//这里才是使用已经注册的解析器进行解析
SqlParamsParseItemResult sqlParamsParseItemResult=processNormalSqlWhereParams(key,value,isPlaceHolder);
if(sqlParamsParseItemResult!=null){
sqlParamsParseResult.addSqlModel(andOrDelititer);
sqlParamsParseResult.addSqlModel(sqlParamsParseItemResult.getSqlModel(isPlaceHolder,PLACE_HOLDER));
sqlParamsParseResult.addArgument(sqlParamsParseItemResult.getValue());
}
}
}
StringBuilder baseWhereSql=sqlParamsParseResult.getBaseWhereSql();
if(StringUtils.isNotEmpty(baseWhereSql)){
sqlParamsParseResult.setBaseWhereSql(new StringBuilder(baseWhereSql.substring(andOrDelititer.length())));
}
}
return sqlParamsParseResult;
}
这里进行了递归调用,主要用于处理 $and $or 的嵌套查询,getSqlWhereParamsResultByAndOr可能内部调用了processModelSqlWhereParams,processModelSqlWhereParams内部又调用了getSqlWhereParamsResultByAndOr
private SqlParamsParseResult processModelSqlWhereParams(Map<String,Object> params,String andOr,boolean isPlaceHolder){
return getSqlWhereParamsResultByAndOr(params,andOr,isPlaceHolder,new SqlParamsParseResult());
}
这里就是使用解析器进行解析的过程,先遍历每个解析器是否支持当前的操作符,如果支持则进行相应的解析
private SqlParamsParseItemResult processNormalSqlWhereParams(String key,Object value,boolean isPlaceHolder) {
SqlParamsParseItemResult sqlParamsParseItemResult=null;
String[] parts=key.split(separatorFlag);
if(parts.length==2){
for(SqlParamsParser sqlParamsParser:sqlParamsParsers){
if(sqlParamsParser.support(parts[1])){
sqlParamsParseItemResult=sqlParamsParser.getParamsResult(parts[0],value,parts[1]);
break;
}
}
}else{
sqlParamsParseItemResult=new SqlParamsParseItemResult(key,"=",SqlStringUtils.processString(value));
}
return sqlParamsParseItemResult;
}
4.3 对外留出的扩展
{
"c.age@>":14,
"$or":{
"b.id@=":2,
"d.age@<":23
}
}
这里面的@ $or 以及 $and 都是可以自己设定的,默认值是上述形式。
5 工程项目
这个小项目已经发布到osc上,见 osc的search-sqlparams项目