在eBay,我们运转着多个由几千个节点构成的Hadoop集群,提供给成千上万的人使用。在这些Hadoop集群中我们存储了几千PB的数据。我们在本文探讨了如何基于数据使用频率来优化大数据存储。实验表明该方法有效降低了经济成本。
Hadoop 及其承诺
众所周知,商用硬件可以组装起来创建拥有大数据存储和计算能力的Hadoop集群。将数据拆分成多个部分,分别存储在每个单独的机器上,数据处理逻辑也在同样的机器上执行。

例如:一个1000个节点组成的Hadoop集群,单节点容量有20TB,最多可以存储20PB的数据。因此,所有的这些机器拥有足够的计算能力来履行Hadoop的口号:“take compute to data”。
数据的温度
集群中通常存储着各种不同类型的数据集,不同的团队通过该集群可以共享地处理他们不同类型的工作任务。通过数据管道,每个数据集每时每刻都会得到增长。
数 据集有一个共同特点就是初始的使用量会很大。在此期间,数据集被认为是“热(HOT)”的。我们通过分析发现,随着时间的推移,使用率会有一定程度的下 降,存储的数据每周仅仅就被访问几次,逐渐就变为“温(WARM)”数据。在此后90天中,当数据使用率跌至一个月几次时,它就被定义为“冷 (COLD)”数据。
因此数据在最初几天被认为是“热”的,此后第一个月仍然保持为“温”的。在这期间,任务或应用会使用几次该数据。随着 数据的使用率下降得更多,它就变“冷”了,在此后90天内或许只被使用寥寥几次。最终,当数据一年只有一两次使用频率、极少用到时,它的“温度”就是“冰 冻”的了。
|
Data Age |
Usage Frequency |
Temperature |
|
Age < 7 days |
20 times a day |
HOT |
|
7 days > Age < 1 month |
5 times a week |
WARM |
|
1 month < Age < 3 months |
5 times a month |
COLD |
|
3 months < Age < 3 years |
2 times a year |
FROZEN |
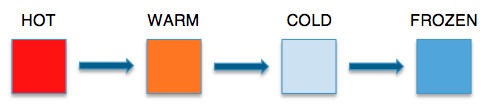
一般来讲,温度与每个数据集都紧密相关。在这个例子中,温度是与数据的年龄成反比的。一个特定数据集的温度也受其他因素影响的。你也可以通过算法决定数据集的温度。
HDFS的分层存储
HDFS从Hadoop2.3开始支持分层存储
它是如何工作的呢?
正常情况下,一台机器添加到集群后,将会有指定的本地文件系统目录来存储这块副本。用来指定本地存储目录的参数是dfs.datanode.dir。另一层中,比如归档(ARCHIVE)层,可以使用名为StorageType的枚举来添加。为了表明这个本地目录属于归档层,该本地目录配置中会带有[ARCHIVE]的前缀。理论上,hadoop集群管理员可以定义多个层级。
比 如说:如果在一个已有1000个节点,其总存储容量为20PB的集群上,增加100个节点,其中每个节点有200TB的存储容量。相比已有的1000个节 点,这些新增节点的计算能力就相对较差。接下来,我们在所有本地目录的配置中增加ARCHIVE的前缀。那么现在位于归档层的这100个节点将会有 20PB的存储量。最后整个集群被划分为两层——磁盘(DISK)层和归档(ARCHIVE)层,每一层有20PB的容量,总容量为40PB。

基于温度将数据映射到存储层
在这个例子中,我们将在拥有更强计算能力节点的DISK层存储高频率使用的“热(HOT)”数据。
至于“温(WARM)”数据,我们将其大部分的副本存储在磁盘层。对于复制因子(replication factor)为3的数据,我们将在磁盘层存储其两个副本,在归档层存储一个副本。
如果数据已经变“冷(COLD)”,那么我们至少将在磁盘层存储其每个块的一个副本。余下的副本都放入归档层。
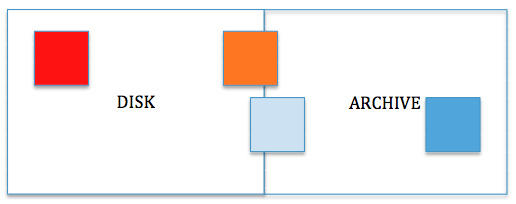
当 一个数据集为认为是“冰冻(FROZEN)”的,这就意味着它几乎已经不被使用,将其存储在具有大量CPU、能执行众多任务节点或容器的节点上是不明智 的。我们会把它存储到一个具有最小计算能力的节点上。因此,所有处于“冰冻(FROZEN)”状态块的全部副本都可以被移动到归档层。
跨层的数据流
当 数据第一次添加到集群中,它将被存储到默认的磁盘层。基于数据的温度,它的一个或多个副本将被移动到归档层。移动器就是用来把数据从一个层移动到另一层 的。移动器的工作原理类似平衡器,除了它可以跨层地移动块的副本。移动器可接受一条HDFS路径,一个副本数目和目的地层信息。然后它将基于所述层的信息 识别将要被移动的副本,并调度数据在源数据节点到目的数据节点的移动。
Hadoop 2.6中支持分层存储的变化
Hadoop 2.6中有许多的改进使其能够进一步支持分层存储。你可以附加一个存储策略到某个目录来指明它是“热(HOT)”的,“温(WARM)”的,“冷 (COLD)”的, 还是“冰冻(FROZEN)”的。存储策略定义了每一层可存储的副本数量。我可以改变目录的存储策略并启动该目录的移动器来使得策略生效。
使用数据的应用
基于数据的温度,数据的部分或者全部副本可能存储在任一层中。但对于通过HDFS来使用数据的应用而言,其位置是透明的。
虽 然“冰冻”数据的所有副本都在归档层,应用依然可以像访问HDFS的任何数据一样来访问它。由于归档层中的节点并没有计算能力,运行在磁盘层的映射 (map)任务将从归档层的节点上读取数据,但这会导致增加应用的网络流量消耗。如果这种情况频繁地发生,你可以指定该数据为“温/冷”,并让移动器移回 一个或多个副本到磁盘层。
确定数据温度以及完成指定的副本移动至预先定义的分层存储可以全部自动化。
eBay的分层存储
eBay 在其中一个具有非常大规模的集群上使用了分层存储。该集群拥有40PB的数据。我们又额外增加了10PB计算能力受限的存储容量。每一个新的机器都可以存 储220TB。我们把增加的存储标记为归档层,并把一些目录标识为“温”、“冷”或者“冰冻”。然后根据它们的温度,移动所有或部分的副本到归档层。
每GB归档层的价格要比磁盘层价格低四倍。这种差异主要是由于在归档层的机器具有非常有限的计算能力,故降低了成本。
总结
无 计算能力的存储比有计算能力的存储要便宜。我们可以依据数据的温度来确保具计算能力的存储能得到充分地使用。因为每一个分块的数据都会被复制多次(默认是 3次),根据数据的温度,许多副本都会被移动到低成本的存储中。HDFS支持分层存储并提供必要的工具来进行跨层的数据移动。eBay已经在其一个非常大 规模的集群上启用了分层存储,用来进行数据存档。
本文作者:佚名
来源:51CTO