互联网时代的到来,使得名人的形象变得更加鲜活,也拉近了明星和粉丝之间的距离。歌星、影星、体育明星、作家等名人通过互联网能够轻易实现和粉丝的互动,赚钱也变得前所未有的简单。同时,互联网的飞速发展本身也造就了一批互联网明星,这些人借助新的手段,最大程度发挥了粉丝经济的能量和作用,在互联网时代赚得盆满钵满。
正是基于这样一个大背景,今天我们做一个分析明星微博数据的小项目。
1、项目需求
自定义输入格式,将明星微博数据排序后按粉丝数关注数 微博数分别输出到不同文件中。
2、数据集
明星 明星微博名称 粉丝数 关注数 微博数
俞灏明 俞灏明 10591367 206 558
李敏镐 李敏镐 22898071 11 268
林心如 林心如 57488649 214 5940
黄晓明 黄晓明 22616497 506 2011
张靓颖 张靓颖 27878708 238 3846
李娜 李娜 23309493 81 631
徐小平 徐小平 11659926 1929 13795
唐嫣 唐嫣 24301532 200 2391
有斐君 有斐君 8779383 577 4251
3、分析
自定义InputFormat读取明星微博数据,通过自定义getSortedHashtableByValue方法分别对明星的fan、followers、microblogs数据进行排序,然后利用MultipleOutputs输出不同项到不同的文件中
4、实现
1)、定义WeiBo实体类,实现WritableComparable接口
- package com.buaa;
- import java.io.DataInput;
- import java.io.DataOutput;
- import java.io.IOException;
- import org.apache.hadoop.io.WritableComparable;
- /**
- * @ProjectName MicroblogStar
- * @PackageName com.buaa
- * @ClassName WeiBo
- * @Description TODO
- * @Author 刘吉超
- * @Date 2016-05-07 14:54:29
- */
- public class WeiBo implements WritableComparable<Object> {
- // 粉丝
- private int fan;
- // 关注
- private int followers;
- // 微博数
- private int microblogs;
- public WeiBo(){};
- public WeiBo(int fan,int followers,int microblogs){
- this.fan = fan;
- this.followers = followers;
- this.microblogs = microblogs;
- }
- public void set(int fan,int followers,int microblogs){
- this.fan = fan;
- this.followers = followers;
- this.microblogs = microblogs;
- }
- // 实现WritableComparable的readFields()方法,以便该数据能被序列化后完成网络传输或文件输入
- @Override
- public void readFields(DataInput in) throws IOException {
- fan = in.readInt();
- followers = in.readInt();
- microblogs = in.readInt();
- }
- // 实现WritableComparable的write()方法,以便该数据能被序列化后完成网络传输或文件输出
- @Override
- public void write(DataOutput out) throws IOException {
- out.writeInt(fan);
- out.writeInt(followers);
- out.writeInt(microblogs);
- }
- @Override
- public int compareTo(Object o) {
- // TODO Auto-generated method stub
- return 0;
- }
- public int getFan() {
- return fan;
- }
- public void setFan(int fan) {
- this.fan = fan;
- }
- public int getFollowers() {
- return followers;
- }
- public void setFollowers(int followers) {
- this.followers = followers;
- }
- public int getMicroblogs() {
- return microblogs;
- }
- public void setMicroblogs(int microblogs) {
- this.microblogs = microblogs;
- }
- }
2)、自定义WeiboInputFormat,继承FileInputFormat抽象类
- package com.buaa;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.InputSplit;
- import org.apache.hadoop.mapreduce.RecordReader;
- import org.apache.hadoop.mapreduce.TaskAttemptContext;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.util.LineReader;
- /**
- * @ProjectName MicroblogStar
- * @PackageName com.buaa
- * @ClassName WeiboInputFormat
- * @Description TODO
- * @Author 刘吉超
- * @Date 2016-05-07 10:23:28
- */
- public class WeiboInputFormat extends FileInputFormat<Text,WeiBo>{
- @Override
- public RecordReader<Text, WeiBo> createRecordReader(InputSplit arg0, TaskAttemptContext arg1) throws IOException, InterruptedException {
- // 自定义WeiboRecordReader类,按行读取
- return new WeiboRecordReader();
- }
- public class WeiboRecordReader extends RecordReader<Text, WeiBo>{
- public LineReader in;
- // 声明key类型
- public Text lineKey = new Text();
- // 声明 value类型
- public WeiBo lineValue = new WeiBo();
- @Override
- public void initialize(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException {
- // 获取split
- FileSplit split = (FileSplit)input;
- // 获取配置
- Configuration job = context.getConfiguration();
- // 分片路径
- Path file = split.getPath();
- FileSystem fs = file.getFileSystem(job);
- // 打开文件
- FSDataInputStream filein = fs.open(file);
- in = new LineReader(filein,job);
- }
- @Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
- // 一行数据
- Text line = new Text();
- int linesize = in.readLine(line);
- if(linesize == 0)
- return false;
- // 通过分隔符'\t',将每行的数据解析成数组
- String[] pieces = line.toString().split("\t");
- if(pieces.length != 5){
- throw new IOException("Invalid record received");
- }
- int a,b,c;
- try{
- // 粉丝
- a = Integer.parseInt(pieces[2].trim());
- // 关注
- b = Integer.parseInt(pieces[3].trim());
- // 微博数
- c = Integer.parseInt(pieces[4].trim());
- }catch(NumberFormatException nfe){
- throw new IOException("Error parsing floating poing value in record");
- }
- //自定义key和value值
- lineKey.set(pieces[0]);
- lineValue.set(a, b, c);
- return true;
- }
- @Override
- public void close() throws IOException {
- if(in != null){
- in.close();
- }
- }
- @Override
- public Text getCurrentKey() throws IOException, InterruptedException {
- return lineKey;
- }
- @Override
- public WeiBo getCurrentValue() throws IOException, InterruptedException {
- return lineValue;
- }
- @Override
- public float getProgress() throws IOException, InterruptedException {
- return 0;
- }
- }
- }
3)、编写mr程序
- package com.buaa;
- import java.io.IOException;
- import java.util.Arrays;
- import java.util.Comparator;
- import java.util.HashMap;
- import java.util.Map;
- import java.util.Map.Entry;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.conf.Configured;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- /**
- * @ProjectName MicroblogStar
- * @PackageName com.buaa
- * @ClassName WeiboCount
- * @Description TODO
- * @Author 刘吉超
- * @Date 2016-05-07 09:07:36
- */
- public class WeiboCount extends Configured implements Tool {
- // tab分隔符
- private static String TAB_SEPARATOR = "\t";
- // 粉丝
- private static String FAN = "fan";
- // 关注
- private static String FOLLOWERS = "followers";
- // 微博数
- private static String MICROBLOGS = "microblogs";
- public static class WeiBoMapper extends Mapper<Text, WeiBo, Text, Text> {
- @Override
- protected void map(Text key, WeiBo value, Context context) throws IOException, InterruptedException {
- // 粉丝
- context.write(new Text(FAN), new Text(key.toString() + TAB_SEPARATOR + value.getFan()));
- // 关注
- context.write(new Text(FOLLOWERS), new Text(key.toString() + TAB_SEPARATOR + value.getFollowers()));
- // 微博数
- context.write(new Text(MICROBLOGS), new Text(key.toString() + TAB_SEPARATOR + value.getMicroblogs()));
- }
- }
- public static class WeiBoReducer extends Reducer<Text, Text, Text, IntWritable> {
- private MultipleOutputs<Text, IntWritable> mos;
- protected void setup(Context context) throws IOException, InterruptedException {
- mos = new MultipleOutputs<Text, IntWritable>(context);
- }
- protected void reduce(Text Key, Iterable<Text> Values,Context context) throws IOException, InterruptedException {
- Map<String,Integer> map = new HashMap< String,Integer>();
- for(Text value : Values){
- // value = 名称 + (粉丝数 或 关注数 或 微博数)
- String[] records = value.toString().split(TAB_SEPARATOR);
- map.put(records[0], Integer.parseInt(records[1].toString()));
- }
- // 对Map内的数据进行排序
- Map.Entry<String, Integer>[] entries = getSortedHashtableByValue(map);
- for(int i = 0; i < entries.length;i++){
- mos.write(Key.toString(),entries[i].getKey(), entries[i].getValue());
- }
- }
- protected void cleanup(Context context) throws IOException, InterruptedException {
- mos.close();
- }
- }
- @SuppressWarnings("deprecation")
- @Override
- public int run(String[] args) throws Exception {
- // 配置文件对象
- Configuration conf = new Configuration();
- // 判断路径是否存在,如果存在,则删除
- Path mypath = new Path(args[1]);
- FileSystem hdfs = mypath.getFileSystem(conf);
- if (hdfs.isDirectory(mypath)) {
- hdfs.delete(mypath, true);
- }
- // 构造任务
- Job job = new Job(conf, "weibo");
- // 主类
- job.setJarByClass(WeiboCount.class);
- // Mapper
- job.setMapperClass(WeiBoMapper.class);
- // Mapper key输出类型
- job.setMapOutputKeyClass(Text.class);
- // Mapper value输出类型
- job.setMapOutputValueClass(Text.class);
- // Reducer
- job.setReducerClass(WeiBoReducer.class);
- // Reducer key输出类型
- job.setOutputKeyClass(Text.class);
- // Reducer value输出类型
- job.setOutputValueClass(IntWritable.class);
- // 输入路径
- FileInputFormat.addInputPath(job, new Path(args[0]));
- // 输出路径
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- // 自定义输入格式
- job.setInputFormatClass(WeiboInputFormat.class) ;
- //自定义文件输出类别
- MultipleOutputs.addNamedOutput(job, FAN, TextOutputFormat.class, Text.class, IntWritable.class);
- MultipleOutputs.addNamedOutput(job, FOLLOWERS, TextOutputFormat.class, Text.class, IntWritable.class);
- MultipleOutputs.addNamedOutput(job, MICROBLOGS, TextOutputFormat.class, Text.class, IntWritable.class);
- // 去掉job设置outputFormatClass,改为通过LazyOutputFormat设置
- LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class);
- //提交任务
- return job.waitForCompletion(true)?0:1;
- }
- // 对Map内的数据进行排序(只适合小数据量)
- @SuppressWarnings("unchecked")
- public static Entry<String, Integer>[] getSortedHashtableByValue(Map<String, Integer> h) {
- Entry<String, Integer>[] entries = (Entry<String, Integer>[]) h.entrySet().toArray(new Entry[0]);
- // 排序
- Arrays.sort(entries, new Comparator<Entry<String, Integer>>() {
- public int compare(Entry<String, Integer> entry1, Entry<String, Integer> entry2) {
- return entry2.getValue().compareTo(entry1.getValue());
- }
- });
- return entries;
- }
- public static void main(String[] args) throws Exception {
- String[] args0 = {
- "hdfs://ljc:9000/buaa/microblog/weibo.txt",
- "hdfs://ljc:9000/buaa/microblog/out/"
- };
- int ec = ToolRunner.run(new Configuration(), new WeiboCount(), args0);
- System.exit(ec);
- }
- }
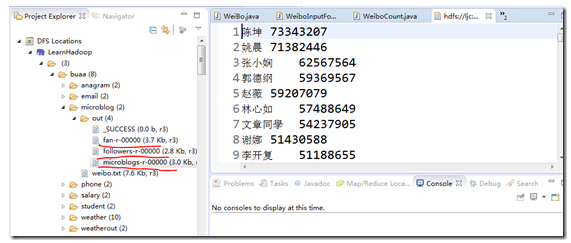
5、运行结果
本文作者:刘超ljc
来源:51CTO
时间: 2024-09-27 16:51:25