引言
5W1H(WWWWWH)分析法也叫六何分析法,是一种思考方法,也可以说是一种创造技法。我们也对大数据问些问题,相信这也是很多中小企业面临的现实问题。大数据这个词也是从12年开始慢慢热起来的,经过4年的发展,如今,很多企业已经开始有自己的大数据平台,但是对于更多的企业是没有的。
笔者也在成都的云栖大会分享了笔者的一些思考与总结,由于后续没有录像放出来,应一些朋友、同学、用户的要求,笔者直接文字写出来。文字都是笔者经过推敲写出来的,肯定要比现场讲的思路更加缜密。
最后会涉及到怎么做,如果对前面没兴趣,可以直接拉到最后。

大数据是什么?
这是一个很大的话题,大数据特点总结起来大约有5个,大量、高速、多样、价值、真实性。笔者也只能根据自己的看法,阐述一二。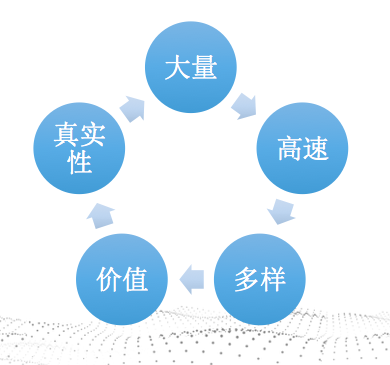
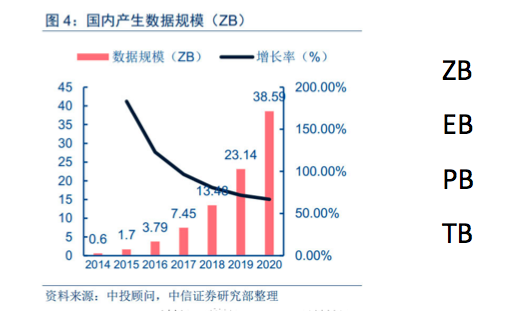
- 大量,根据 中投顾问的数据,最近几年的数据增长为100%-200%左右,国内可使用的数据为ZB级别。一般中小企业的数据在TB到PB左右,后续会讲述,我们的数据从哪里来。

- 高速,第一个指数据增长速度比较快;第二个指数据产生后,需要高速的处理,这就有一个矛盾,大量跟高速处理本来就是矛盾的,目前也是通过技术不断的进步跟业务的取舍来合理平衡这个问题的。
- 多样,第一个指数据的类型:结构化、半结构化(如文档型的)、非结构化(如视频、图片、语音等);第二个是指数据的种类,各行各业的数据,有时候我们讲究数据融合、打通。
- 价值,数据是对客观世界的反馈。如果说上帝知晓万物是对物质的掌控,企业CEO对企业的掌控就是对数据的掌控。后续会稍微对价值篇展开讨论。
- 真实性,往往反应的是事物之间的相关性,是一种真实的客观存在。
那到底是什么?如果让笔者一句话总结,形而上的说法:大数据是人类生产到了一种更高阶段的对现实世界探求的客观描述。具体的:大数据指在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
为什么需要大数据?
这个就要具体说说大数据的价值点了。
首先我们想想为什么大数据在这几年火了呢?笔者记得4年前,阿里成立数据事业部的时候,也正是大数据刚开始火的时候。
从百度指数上看,云计算在11年之前就开始火了。现在搜索云计算这个词的用户反倒没有以前多,但是大数据这个词从12年开始就不断的增加,超过了云计算。为什么呢?
笔者认为:
- 12年新技术,特别是hadoop技术的发展,让廉价存储、分析大量的数据成为了可能。
- 大公司,比如说阿里巴巴,积累的很多了数据,又开始分析这些数据,对企业的生产产生了巨大的价值。这些会形成一个风暴迅速传播。
我们还是具体说说,为什么需要大数据吧。看起来是有点多此一举,不是很明白吗!?有价值。我们需要讲到问题的核心,大数据对于企业,就是提高效率、提升竞争力的;对于社会,可以拯救生命,造福人类。国家提出了互联网+的概念,其实我们仔细想想,其核心是 大数据+ 。现在比较高大上的无人驾驶、基因测序、智能交通、人工智能等其核心对数据的处理。
举几个不那么高大上的具体的例子,这三个例子后续讲具体怎么做。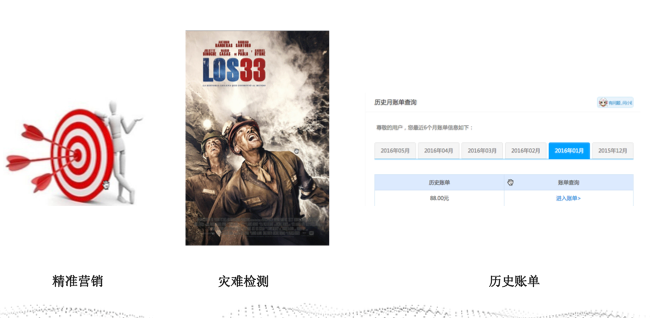
- 广告的精准营销,可以节约广告投放的成本,也会减少对客户的骚扰,其核心是大数据处理。
- 灾难检测,比如煤矿灾难,是否可以提前预警,减少生命的伤亡,财产的损失,其核心是大数据处理。
- 历史账单,现在(本文写于2016年6月)我们去中国移动网站查询历史账单,只能查询最近6个月的,笔者非常想知道去年这个时候,我在移动花费了多少钱(要知道运营商经常乱扣钱的)。笔者可以在淘宝查询09年的消费记录,很清楚的知道09年7月份,在淘宝买了啥, 也可以对我们在淘宝的消费记录做一个数据分析,是不是要节约开支。
啥时候用?
有的人说,我不可能一开始就造一个大数据平台吧。我感觉用excel就可以做数据分析了,那也是可以的。不过,你还是得考虑下,如果一直用excel做数据分析,那也还说明你还没有步入大数据时代。这个也是好事情,因为你没有使用大数据的利器,你公司还没有倒闭。等你合理使用大数据后,你的企业可能会腾飞起来。 一般来讲,企业可能会有以下几种原因没有去建设大数据平台。注意,成本往往不是核心的因素,在风投市场,你说我用大数据来提高生产力,挖掘数据价值,只要你说的真是那么回事情,你的公司的估值立马提升。对于传统做起来的公司,根本不差这么点钱。
具体我们不去分析,笔者只想表述,很多人都知道大数据是很重要,但是就是认为不紧急。对于企业来讲,现在的市场竞争何其激烈(不比中移动),你不做,竞争对手做,你就是loser
谁来做?
这个事情,不是基层几个同学想做就能做的事情。必须得从最高层(董事长、CEO)往下的。如果你是基础的员工,你发现这个事情确实很有价值,那你的机会来了,你可以谏言去做这个事情。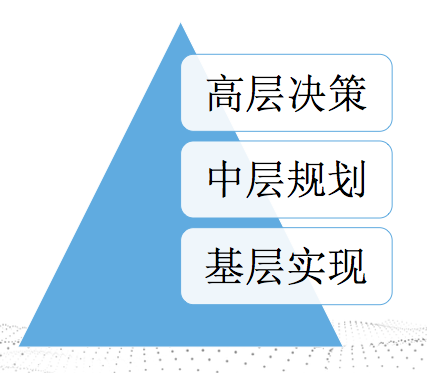
我们一般是遵循这个的,高层决策要干这个事情,中层规划怎么做,基础实现。
具体实现谁来,有的是请外面的直接做业务的大数据公司,有的是自己搞。我们很多公司还是自己主导的,外面的公司一般是辅助。最后,我们招聘三类基础的同学:
- 应用研发,就是hadoop、hive、spark数据工程师。小公司一般不细分,大点可以细分出算法工程师、数据ETL工程师等
- 运维,如果你要自建平台的话。
- Hadoop专家,如果你需要修改内核的话。
好了,公司终于开始想大干一场了,也有人来干这个事情了。
在哪里用?
如果我们开始想自建,肯定会遇到,这四类问题。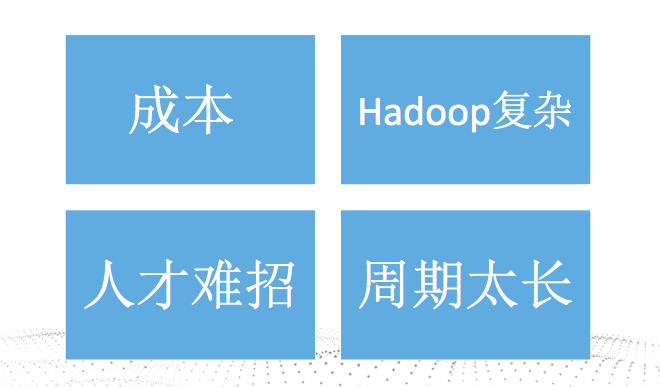
Hadoop 复杂性
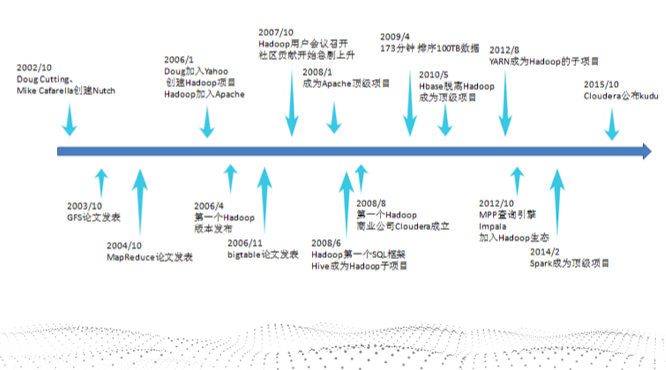
Hadoop不同于数据库,比如mysql(往往是单机的,有时候再做一个容灾,一般DBA肯定搞定,我们也很少去修改mysql的源码)。对于Hadoop来讲,版本众多,且组件30+,代码数百万行。
- Hadoop发展的10年:
- 从最初的2个组件到30+个组件
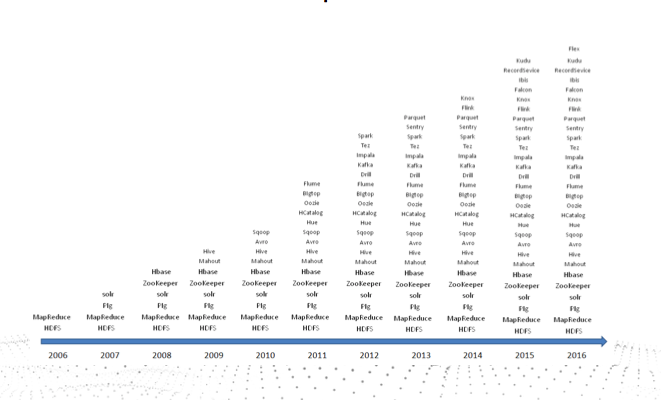
- 2016年整理的数据处理的大图

人才难找
一方面很难从市场上招聘到合适的人才,因为大数据本身发展才4年时间,一开始大家还没有反应过来呢。另一方中小公司还是很难留住专业的底层的Hadoop内核专家及底层的运维同学的,因为没有环境、员工自身也很难成长,中小公司很难有一个团队是搞hadoop内核研发的,这个不同于数据研发工程师。
周期太长
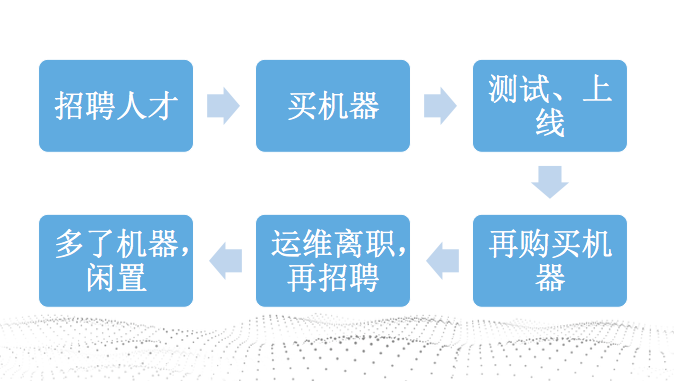
从招聘人才到上线,一般周期起码得6个月左右。
阿里云E-MapReduce平台能提供的
终于说到了 阿里云E-MapReduce了,我们也是为了解决这些用户痛点才产生的。
首先肯定是周期会缩短很多,这个是云的共性。
- 半自动化运维系统(建设了一部分):帮助运维Hadoop平台,会监控Hadoop系统,出现状况后会报警,且有一些场景下会自动修复。
- 专家系统(正在建设):帮助优化Hadoop、spark作业。比如:小文件是否过多,map运行时间是否过短,用压缩提高效率等,有一整套的报表展示。
- 专家服务:一般是我们的专家点到点跟客户谈具体的解决方案,具体会遇到的问题。还有比如,优化Hadoop性能,推动Hadoop在下几个版本会默认支持OSS的,见:HADOOP-12756

这些直接解决了,运维难,周期长的问题,也解决了底层员工难招聘的问题。
成本
很多中小企业还会很关心成本,我们做了一个大致估算。
传统的方式是110w+左右,使用阿里云的E-MapReduce的成本(可以使用存储计算分离),差不多66w左右,如果使用按需按量晚上跑离线等来算,会更低的。不细说每一项,表格中列的很清楚(价格为估算的)。特别说的机会成本,这个自建是没有算的,因为这个会根据实际的情况有天壤之别。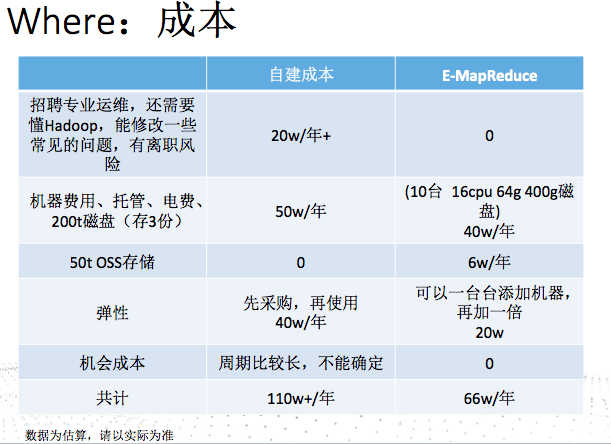
从价值出发
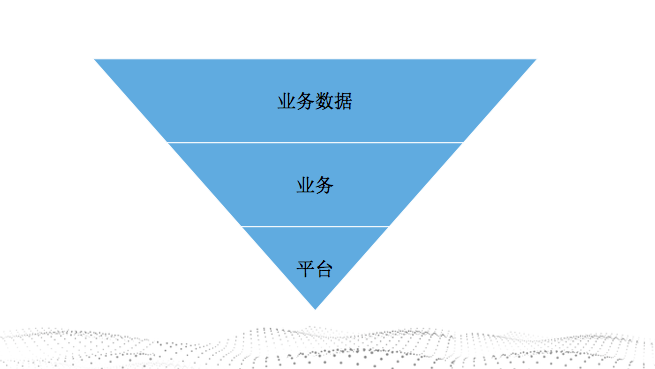
我们认为对于中小企业来讲,价值链体现为倒三角形,也就是数据最具有价值,再就是业务系统算法等,最后是平台。平台对于中小企业,自己建设成本很高。
我们希望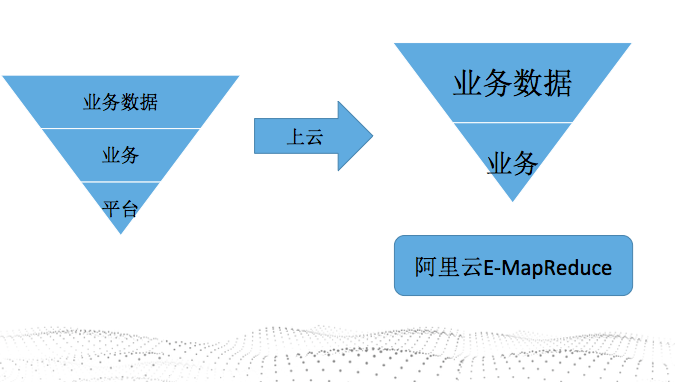
阿里云E-MapReduce把众多小的平台汇总成一个大的平台,专业的人才做专业的事情,把事情做好,做专,不断满足广大客户的需求,最终达到一个共赢的局面。
在哪里用?
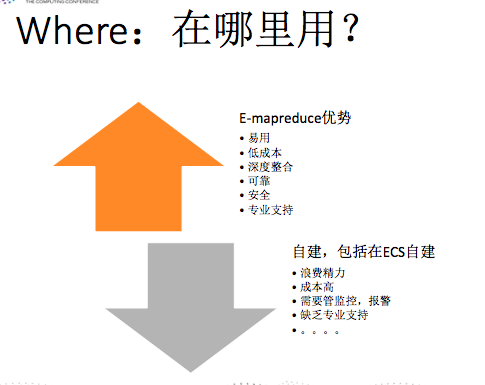
其实,E-MapReduce还有其他很多的优势,没有一一列出,此图有一个大致的总结。可以访问E-MapRedcue主页
BTW 混合云方案
如果业务(可能是CRM、ERP系统)不能上云,可以采取方案,拉一根专线上云。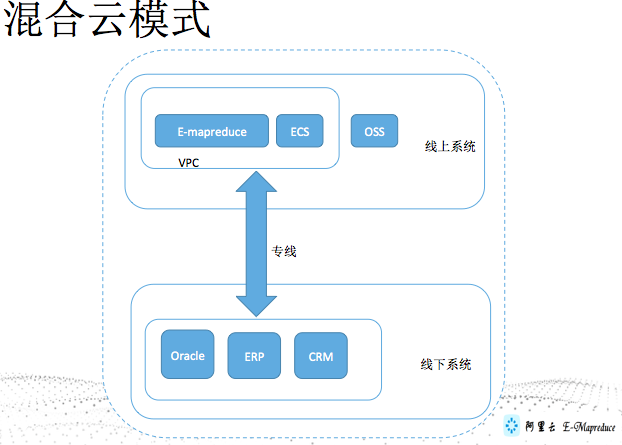
怎么做?
终于讲到怎么做了,前面看起来是讲给老板听的。其实每个同学都应该有top level的思维的,如果是自己的企业,怎么去思考这个问题。
大致的步骤
数据处理的大致步骤,数据源->数据清洗->数据存储服务->数据分析->可视化展示(有的没有)
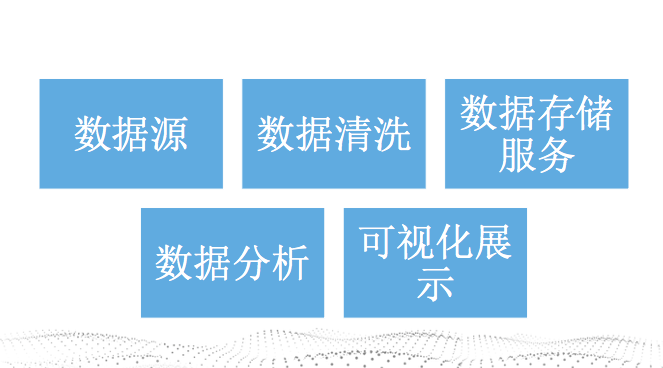
- 数据源,企业的数据一般来源四个方面
- 企业的数据,包括用户的访问日志,apache日志,tomcat日志;数据库的实际结构化的数据;用户存储的图片、资料等。(一般需要用户授权给企业分析,一般的企业估计就直接分析了)
- 外面爬取的数据,比如从微博等有公开爬的数据
- 政府机构开放数据,比如中国地图、一些航班的信息(这方面美国做的比较好,中国就差一些)
- 数据交换或者购买,目前来看还不是主要的途径,大家都把自己的数据握得很紧。
- 数据清洗
数据来源多种多样,需要统一格式;对于一些非结构化的数据,半结构化的数据,需要格式化。有两大类,一个是离线数据清洗,一个是在线实时数据清洗。离线数据清洗,一般把数据存放到OSS或者HDFS中,再启动hive脚本或者写mapreduce或者spark做离线分析,最后数据可以放在hive中或者其它的在线数据存储服务中。在线实时数据清洗,一般是用sparkstreaming或者strom/jstorm直接处理实时流过来的数据,清洗完成,因为实时化,所以一般会接到在线的数据存储上,比如rds、mogodb、redis、hbase等。 - 数据存储服务
基本来讲,hadoop提供大数据的存储服务为Hbase,Hbase有非常多的场景应用。当然也可以存储到其它的存储服务商。 - 数据分析
接下来会具体分析的。 - 可视化展示
一般是bi报表及大屏之类的。这个阿里云也有相应的BI工具的,用户也可以使用商业的工具,比如:teradata结合EMR数据分析出报表。
场景
大数据处理场景,我们一般分为4类。

- 离线分析,具体讲就是 数据是先存储在一个地方,后续再分析的,往往一般特别指写好程序,按照一定的周期固定运行的。
- 流式数据处理,指数据一条条流过来的。这类数据处理具有很高的时效性,往往是数秒钟的延迟,在一些特别的场景(比如风控)到毫秒的场景。
- 大数据数据存储服务,在单机如mysql无法满足需求的时候,需要大数据的在线存储服务,通过分布式的能力提供在线服务的能力。目前在hadoop体系中,特别是国内,hbase用的比较多。
- ad-hoc分析,就是用户有一个想法,这个想法用户想及时查询数据,一般是运营同学或者数据分析的同学。还有一些,比如计算学习算法的参数调整,往往用户需要加载一点数据,再验证,看下结果,再调整参数(这个也是为什么spark比hadoop从易用层面更加适合机器学习场景的原因。
离线分析
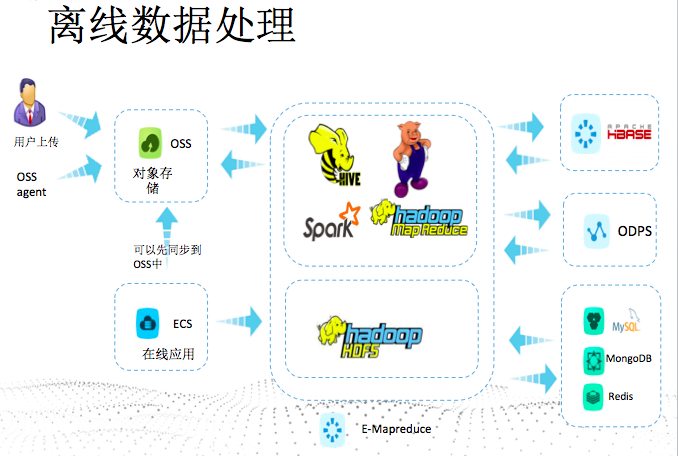
典型的场景是广告里面的精准营销(前面也提了下),为了做这个一般需要:
- 尽量收集到关于用户更多的数据,为了做用户画像,这些数据从不同的地方来,上面分析过主要的四个途径。
- 数据一般直接存储在OSS、HDFS中。
- 通过离线处理,机器学习的分类等算法(一般在E-MapReduce推荐使用spark或者spark mllib机器学习算法库),给用户打标签,比如爱好、性别等,尽量刻画一个用户,还原在现实生活中的状态。期间会除去很多的噪音,细节点很多,需要不断优化(一般数据越多,越精准)。
- 后续 广告通过相关特征匹配推荐打标签的用户,再通过用户的点击率等信息沉淀数据,反过来优化算法。
流式处理
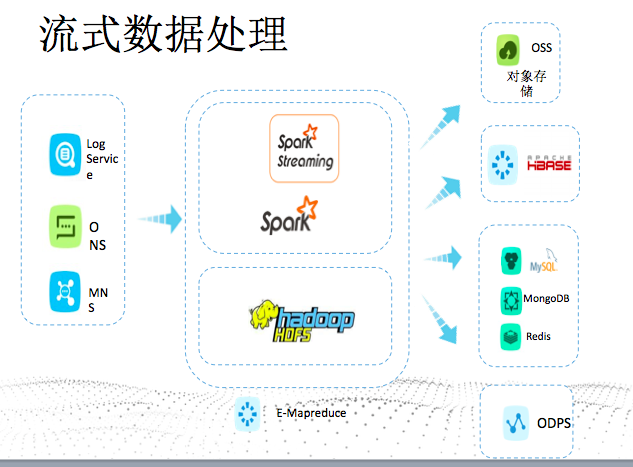
典型的场景是故障检测(比如灾难检测):
- 在需要检测的点上,部署很多传感器(比如煤矿),这些传感器不断的产生大量的数据。
- 这些数据通过网络(4g或者专线)上传到云中的logservices
- E-MapReduce中启动sparkStreaming或者storm/jstorm来分析上传的数据
- 通过统计,识别其中的一些异常特征信息,把这些信息存储到数据存储服务中
- 通过大屏或者BI报表,或者监控报警反馈给用户
- 一方面用户可以替换快坏的设备,另一方面可以预警,预防生命财产的损失
海量数据在线服务
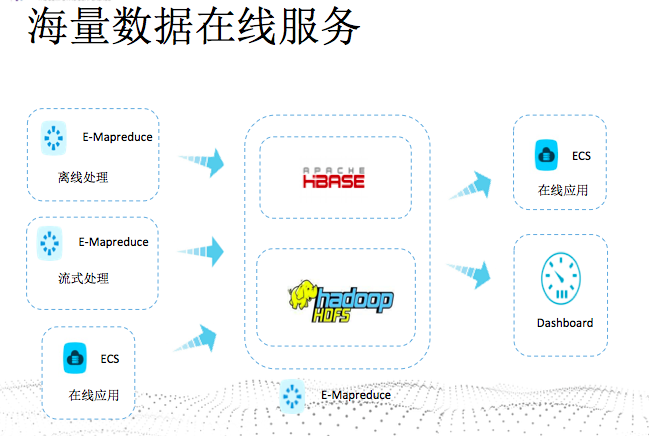
为什么中国移动不能查询6个月以上的账单呢,但是淘宝可以查询09年的账单?排除其他的考虑,从技术来讲就是淘宝可以支持海量数据的在线服务的能力。
典型的场景就是历史账单的查询:
- 分析完成后或者用户直接产生的数据存储在Hbase中
- 通过业务系统直接查询Hbase,提供给用户使用
ad-hot数据分析

如果一个公司的运营同学可以通过hive sql查询数据做运营计划。那这个公司无疑真的是一个数据驱动的公司。这个就涉及到ad-hot数据分析平台的建设。
- 底层还是数据准备好,打通,清洗好,每一段时间固定生产一些数据。
- 运营同学,做计划的时候,可以天马行空查询自己所需要的数据。
还有就是开发同学自己ad-hot,这个一般直接用hue或者zepplelin,可以写scala、python、R来做。专搞数据分析,精通各种工具,业务场景,我们称之为数据科学家。
后记
昨天讲述完成后,特别跟一个客户聊了他们正在建设的大数据平台。征得他的同意,把这个数据流程图放出来了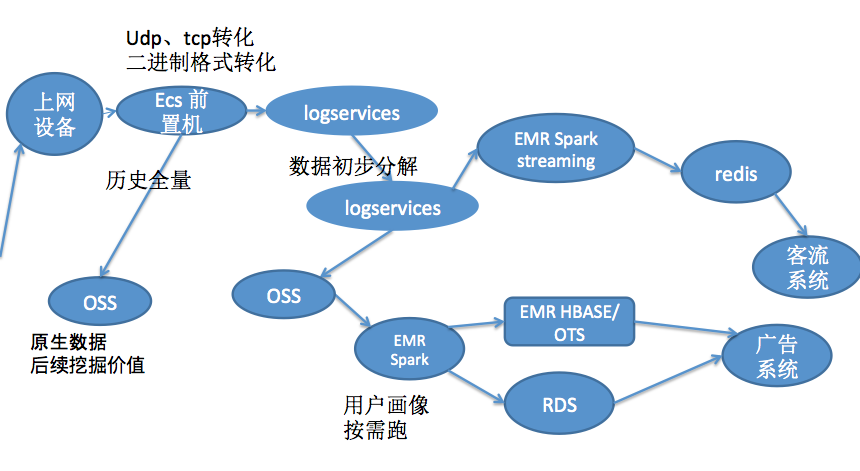
从中可以看出,离线处理、流式处理、海量数据在线服务都使用到了。
记录几个要点:
- 数据从基站上传后需要经过一些预处理,可以通过logservices做压力缓冲。
- 源数据预先存储一份到OSS中,当前处理可能价值没有挖掘完成,后续可以再挖掘。
- 典型的lambda架构,一路流过来,在线sparkstreaming直接处理后,接redis,做实时的查看;离线沉淀到OSS中。
- 广告平台的搭建,采取离线分析,做用户画像,后数据输出到广告系统。
- 采取E-MapReduce按需运行,节约成本(在晚上运行)
- 如果rds支撑不住大数据量,采取Hbase等分布式海量存储服务
我们从大数据的特征说起,谈到了大数据的价值,再聊啥时候做,谁去做,选择啥平台,最后聊到了怎么做的问题。通过对一些真实的场景分析,了解了大数据的全貌。
版权声明
2016年6月30日写于成都双流机场。
笔者微博:阿里封神 欢迎转载,但请保留原文地址