现代城市是由人、机、物等组成的繁复的生活系统,其间产生的数据可用巨量来形容。要对这些宏大的数据进行收集、梳理并作分析,难度有之。在日前举办的杭州云栖大会上,浙江大学陈为教授为我们分享了其团队近几年在城市大数据可视化方面的部分科研成果,并探讨了机器学习等在城市数据研究中的重要性。本文为其演讲实录,并略经编辑、删减。
可视分析研究的兴起
今天我向各位分享的是我们浙江大学可视化与可视分析小组最近两年的研究工作。
首先简单给大家两个定义。
- 第一个,可视化是什么?可视化实际上是把数据信息转化为人眼能识别的可视符号,通过眼睛来增强人类大脑认知的一种方法。可视化其实是人机交互、虚拟现实应用里面的关键技术。
- 第二个,可视分析是什么?2004年美国在对反恐情报的分析中,出现了一些核心问题(DT君注:美国国土安全局之后成立国家可视化与分析中心),后来就演化出了一个新的学科,叫做可视分析学。这门学科是把可视化、人机交互、数据挖掘结合起来,形成的一种新的解决问题的综合性的思维方式。
我从2004年开始就转向了可视化分析方面的研究。尤其最近几年,人工智能的兴起使得我们能够更好地考虑去做智能可视化,来分析一些问题。
今天要向大家展示的,是围绕最近几年我们拿到的一些真实、少量的数据,以及我们所做的部分研究工作。
对人群位置和手机通话关系做可视化
第一项研究,是基于手机基站数据。简单来讲,每一个手机用户,他每分钟在什么位置,这个位置是不精确的,而是一个基站的ID。
用户在某些基站可能会停留,也可能会移动,这其实反映了城市人群的流动。同时我们也获得了这些用户互相之间的通话数据。有了这些数据后,我们自然而然想:这个城市的人群到底是怎么流动的呢?当然这是基于基站的流动,不是基于车辆,也不是基于GPS。
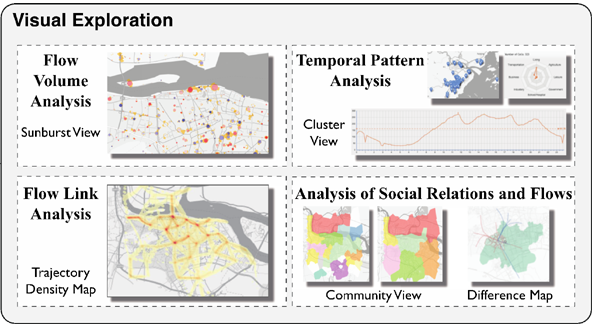
- 上图是我们设计的4个视图。左上角是以手机基站为中心的人群流动的规模分析,以及随着时间演变,它的变化趋势。
- 左下角是一个热力图,它展现了在不同的区域,人群的密度、分布情况。
- 右上角是一个传统的统计可视化,通过统计的报表来分析。
- 右下角是结合了聚类,用数据挖掘的传统方法,来研究社交关系和人群流动之间有没有一些没法用统计方法来表现的规律。
在整个界面上,我们分成了几个视图,视图本身是用WebGL进行加速,它的背后是整个城市数百万人的手机每分钟的位置数据,以及不定时的发短信和电话的记录等数据的支撑。
在我们看来,可视化一个非常重要的功能是给人一个提示、给人一个直觉、给人一个恍然大悟的感觉。
需要注意的是,我们今天给大家提供的例子,都是以二维为背景的,因为我们觉得虽然三维的背景在某些应急指挥或者城市规划中应用很广泛,但在一些非结构化、时空和非时空的信息分析当中,二维和高维的空间数据分析更加适合。
在这个视图中,我们使用了开源的OpenStreetMap作为底图,在此基础上做了叠加和WebGL加速,从而能够做到实时呈现。
基于手机信令数据做人群流动的可视化
接着我们来看看,我们在对手机信令数据的进一步挖掘中,如何观察人群的流动。
如何来衡量人群流动呢?我们发现,20世纪80年代,国内已经有人在研究张量场和流场这样的理论,我们认为,在城市人口密集区域研究人群流动,也可以通过流场来表达和刻画,然后再采取一些扩散对流的方法,来进行表达。
获得了手机信令相关的原始数据后,要进行梳理和清洗,再转化为向量场。什么是向量场呢?就比如风朝某个方向吹,其实就是一种向量场。
将向量场应用到人群流动分析中,可以用来刻画人群在大范围内的宏观的流动。下面这张图是我们和阿里合作的人群实时流动的可视化分析的截图:
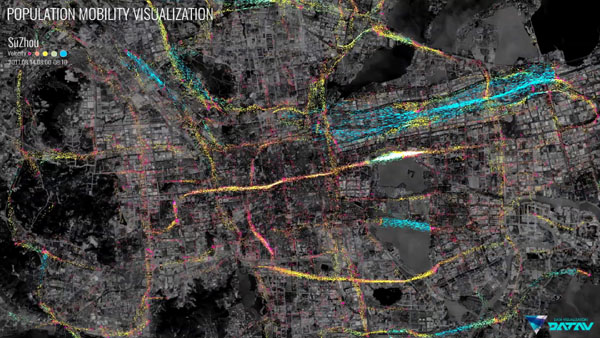
在图中,人群的流动是发生在道路上的。在早晚高峰,它具有某种大范围的宏观流场特征。通过可视化的方法,我们能让用户看到人群移动的方向,以及分叉和融合、聚集和扩散的情况。
我们目前的数据可能还不是那么精确,因为我们是将某个区域划分为若干个小方格来进行计算、统计人群的流动,如果我们有GPS之类数据的话,可以更好地采取类似的计算机视觉的技术,来监测人群中可能发生的踩踏情况。
理论上来说,如果我们的数据汇聚得比较好,是可以提前预防踩踏事件的。
从出租车轨迹来对路况进行可视化查询
第三个例子是基于出租车轨迹的相关数据对路况进行可视化查询。
2012年时,杭州市有8300多辆出租车,这些出租车的车流占整个城市车流的7%左右,因此出租车的轨迹能够反映城市交通的某种状态。
要通过出租车的数据来查询哪个地方堵车,哪个路口的人群往哪里走等等,我们需要有一个能够即时反馈的查询工具。
虽然我们也可以写一个程序,用Excel打开进行查询,但是要做到随时随地查询、对不同区域进行对比等,这样我们就需要一个可视化分析的界面,因为这才是一个即时的分析工具。
我们的课题组主要做的就是将空间的数据转化为可视化的交互界面查询,向用户提供一个更简单、敏捷地的数据工具。这背后当然需要一些数据挖掘算法。
这里来看下一我们的原始数据的情况:
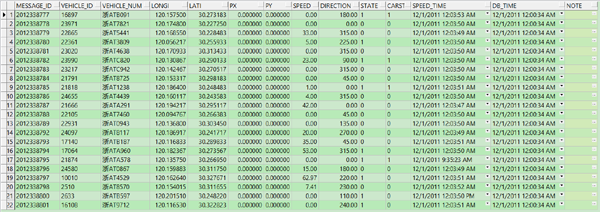
我们拿到的原始数据,打开一个文件需要10分钟,但在我们对数据进行处理和建立索引后,用户的查询同样也做到了实时。
基于这些数据,我们能做到什么呢?
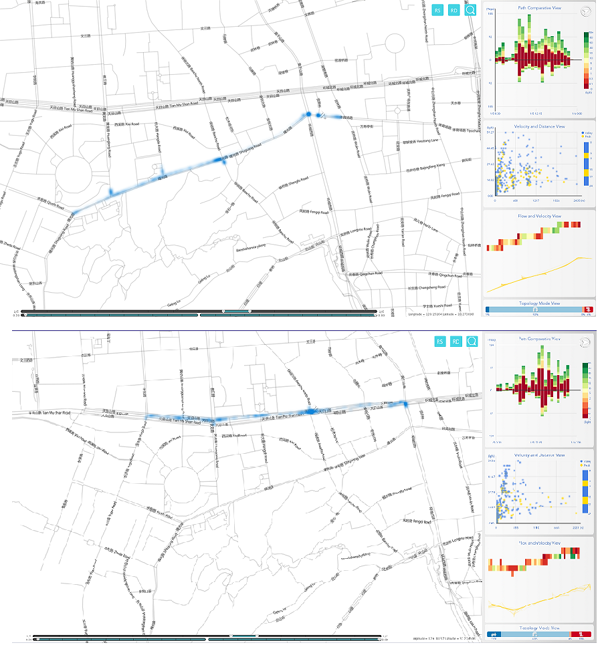
我们可以做双向车道、潮汐车道的对比,还可以分析交叉路口、堵车等各种交通方面的问题。
比如,下图展示的是杭州天目山路和曙光路的情况。这是两条平行道路,但是由于曙光路施行了潮汐车道,所以,从图中可以看出,曙光路的拥塞情况较轻,从右侧的散点图能看出曙光路的车流量要比天目山路(主干道)更大。
下面的视频,展示了杭州8300辆出租车的轨迹的情况,以及我们基于这些数据对车流和交通状况的一些分析:
将机器学习引入城市空间位置的可视表达与分析
在对数据实现可视查询后,我们认为,要对深层次的信息进行刻画,我们还可以采用一些机器学习的方法来进行表达。
比如说,我们最近就进行了一个简单的尝试。大家知道,最近有一种最新的word2vec方法,它实际是一种深度学习的数据表达。我们也把这个方法扩展到了非结构化数据的处理上。用于对时空、人群和出租车轨迹的数据分析。从而能够帮助我们更好地来观察人群位置移动等。
通过把粗糙的信息进行过滤后,用户还能够从中找到一些很有趣的信息。
下面是我们的一些可视化界面截图:
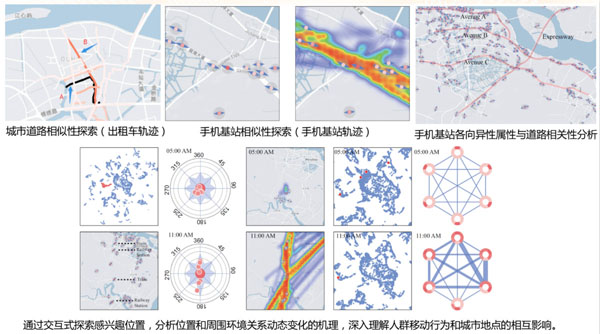
通过引入机器学习,我们可以探索手机基站的相似性关系、城市道路的相似性、手机基站各向异性属性与道路的相关性分析等等。可以更好的探索人群和城市地点之间的交互过程。
我们认为,对这些信息进行可视化不仅是为了让用户看,更重要的是了解在三元空间中的人、机、物之间发生了什么事。
人的社会关系的可视推理和异构数据的关联分析
最后再来谈谈我们如何对个人的社会关系进行可视推理,以及不同结构类型的数据如何进行关联分析。
我们希望基于三元空间里的诸如微博数据、手机的基站相关的位置数据、出租车数据,来推测某一个不明身份者的社会关系。
先来举个例子。有一个孕妇,在生小孩前后通过手机在车上连续发了7条带有位置的微博,但是微博里面的地理信息位置不够精确,而我们恰好有这个时间段里的手机基站和出租车轨迹的相关数据,通过简单的方法,我们可以在1-2分钟内,快速把这个孕妇住在哪、她的丈夫是谁、她的手机是哪一个ID等等,都能找出来。
对于这类关系的分析,我们需要借助于人和机器的智能融合,来让用户通过时间线的表达,通过地理、时间,来快速迭代地把四元空间中可能会发生信息碰撞(公安相关领域一个术语)的人物关系找出来。
另外,通过此类分析,我们还可以找到交班的出租车位置信息,人群的通勤规律等等。
做这样的分析,我们当然不是为了破坏隐私,反过来理解,我们其实也在做关于隐私保护的可视化分析。我们希望能给我们的用户一种一针见血、快速而敏捷地找到某个人的社会关系的一种方法。注意这些目前还不是自动做到,而是需要把人的常识,经验融入到机器,通过可视化的交互方式去迭代地融入,这样才能找到一些蛛丝马迹。
接着再来看看如何对异构数据进行关联分析。
通过把不同的线索快速汇聚在一起,能让大家快速成为福尔摩斯。通过对不同线索的汇聚,对数据进行关联推理分析,这里我还是举两个例子。
第一个例子,某个人在微博中称其在某个时间打车时丢了一部手机,半小时后用电话打过去发现手机关机。谁会拿走他的手机呢?我们通过数据,两分钟之内能够查出来。可以从几千条出租车轨迹中,快速匹配出来。最后还原出来整个事件:原来是出租车司机把这个手机拿走了。
下面这张图展示了从某条微博,到最终定位到某位出租车司机的推理过程:
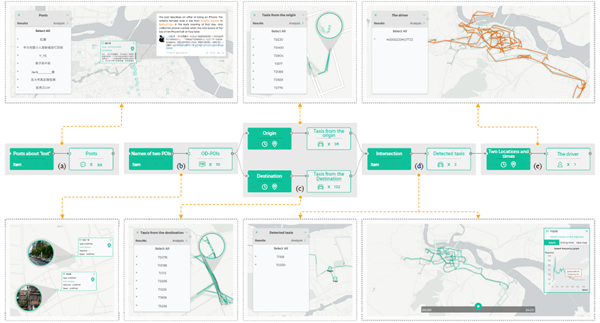
(图片说明:城市数据的多样化导致了多源异构的数据,它们在带来信息量的同时带来了很大的数据学习成本和数据查询成本。本文作者团队建立的一套模型,可以提高数据查询效率,利用可视化的方法,用户能够简捷直观地自定义数据查询目标,并利用不同视图展示查询结果,有效提高了城市数据的分析效率。这个图展示了某个事件的分析推理过程。)
第二个例子,是关于某一起车祸。车祸发生前,所有的天气情况、道路情况以及它引起的交通拥堵等情况,都可以快速进行分析。此外,我们的平台上还汇集了手机信令、出租车轨迹、微博数据、谷歌视频、地图、街道等各种网上信息。可以将不同的数据关联起来。
我们认为,对于大数据,第一步是要“存”(存储),第二步是“通”(关联),第三步是能做一些分析。
再进一步,可能还需要进行更多的数据挖掘,引入机器学习、人工智能等算法,才能够让我们智慧城市建设走得更远,形成一个以数据为中心的城市大脑。
原文发布时间为:2017-10-25
本文作者:佚名