【故障处理】队列等待之enq: US - contention案例
1 BLOG文档结构图

2 前言部分
2.1 导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~:
① enq: US - contention等待事件的解决
② 一般等待事件的解决办法
③ 队列等待的基本知识
Tips:
① 本文在ITpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和微信公众号(xiaomaimiaolhr)有同步更新
② 文章中用到的所有代码,相关软件,相关资料请前往小麦苗的云盘下载(http://blog.itpub.net/26736162/viewspace-1624453/)
③ 若文章代码格式有错乱,推荐使用搜狗、360或QQ浏览器,也可以下载pdf格式的文档来查看,pdf文档下载地址:http://blog.itpub.net/26736162/viewspace-1624453/,另外itpub格式显示有问题,可以去博客园地址阅读
④ 本篇BLOG中命令的输出部分需要特别关注的地方我都用灰色背景和粉红色字体来表示,比如下边的例子中,thread 1的最大归档日志号为33,thread 2的最大归档日志号为43是需要特别关注的地方;而命令一般使用黄色背景和红色字体标注;对代码或代码输出部分的注释一般采用蓝色字体表示。
List of Archived Logs in backup set 11
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- ------------------- ---------- ---------
1 32 1621589 2015-05-29 11:09:52 1625242 2015-05-29 11:15:48
1 33 1625242 2015-05-29 11:15:48 1625293 2015-05-29 11:15:58
2 42 1613951 2015-05-29 10:41:18 1625245 2015-05-29 11:15:49
2 43 1625245 2015-05-29 11:15:49 1625253 2015-05-29 11:15:53
[ZHLHRDB1:root]:/>lsvg -o
T_XDESK_APP1_vg
rootvg
[ZHLHRDB1:root]:/>
00:27:22 SQL> alter tablespace idxtbs read write;
====》2097152*512/1024/1024/1024=1G
本文如有错误或不完善的地方请大家多多指正,ITPUB留言或QQ皆可,您的批评指正是我写作的最大动力。
3 故障分析及解决过程
3.1 故障环境介绍
|
项目 |
source db |
|
db 类型 |
RAC |
|
db version |
11.2.0.4.0 |
|
db 存储 |
ASM |
|
OS版本及kernel版本 |
AIX 64位 7.1.0.0 |
3.2 故障发生现象及报错信息
最近系统做压测,碰到的问题比较多,今天同事发了个AWR报告,说是系统响应很慢,我简单看了下,简单分析下吧:
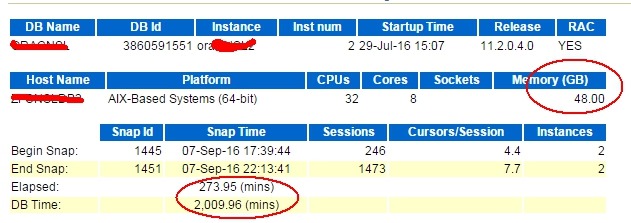
270分钟时间而DB Time为2000多分钟,DB Time太高了,负载很大,很可能有异常的等待事件,系统配置还是比较牛逼的。
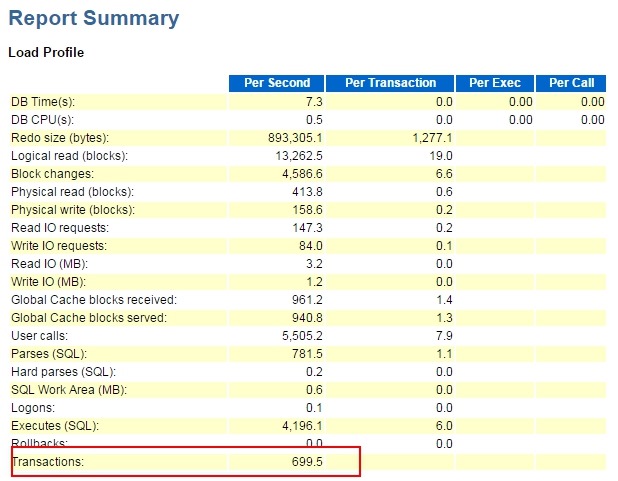
事务量很大,其它个别参数有点问题,不一一解说了。等待事件很明显了:
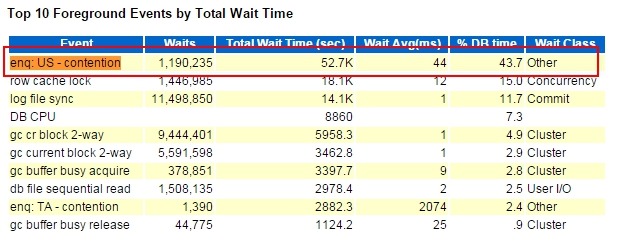
AWR的其它部分就不分析了,首先这个等待事件:enq: US - contention比较少见,查了一下资料,有点收获:
SELECT * FROM V$EVENT_NAME WHERE NAME = 'enq: US - contention';

SELECT * FROM v$lock_type d WHERE d.TYPE='US';

"enq: US - contention",这个event说明事务在队列中等待UNDO Segment,通常是由于UNDO空间不足导致的。
在对此事件说明之前,需要理解在使用AUM(atuomatic undo management)时,回滚段在何时联机或脱机。AUM与RBU(rollback segment management)不同,回滚段的管理是Oracle自动完成的。使用AUM时,回滚段的联机或脱机的时刻如下:
1)在执行alter database open的时候将回滚段联机
2)通过alter system set undo_tablespace=xxx 修改撤销表空间时,将原来的回滚段脱机后,再将新的回滚段联机。
3)通过SMON,自动脱机或者联机回滚段,如果一段时间内,事务量增加,联机状态的回滚段也会增加,一段时间内若是没有实物或事务减少,回滚段就会被smon进程脱机。
为了同步将回滚段联机或脱机的过程,执行该工作的服务器进程或后台进程应获得US锁,每个回滚段非配一个US锁,ID1=Undo segment#。若在获得US锁的过程中发生争用,则等待enq:US-contention事件。服务器进程应该在开始事务时分配到回滚段,但如果不存在可用的回滚段时,应该创建新的回滚段或将脱机状态的回滚段联机。在实现此项工作期间,服务器进程为了获得US锁而等待,等待占有可用回滚段。
这是oracle10g中开始出现的bug(在11.1.0.7中仍有这个BUG),当因为系统activity增加或者降低的时候,oracle SMON进程会自动ONLINE或者OFFLINE rollback segments。这样导致某些与undo segments相关的latch或者enqueue被hold住太长时间,导致系统很多活跃session都开始等待enq: US - contention。可以同时使用以下解决方法:
1. 设置event让SMON不自动OFFLINE回滚段
alter system set events '10511 trace name context forever, level 1';
2. 设置参数_rollback_segment_count :表示有多少rollback segment要处于online的状态;可以将该数值设置为数据库最繁忙的时候的回滚段数目。
alter system set "_rollback_segment_count"=1000 SID='*';
这里以"_"开头的为隐藏参数,通过show parameter 是看不到的,可以通过以下语句:
select a.ksppinm name, b.ksppstvl value, a.ksppdesc description
from xksppia,xksppia,xksppcv b
where a.indx = b.indx
and a.ksppinm like '%_rollback_segment_count%';
3. undo autotune bug多多。最好disable。
alter system set "_undo_autotune"= false;
这种方法就是关闭了UNDO的自动调整功能,同时也能解决掉UNDO表空间会在很长时间都一直保持着使用率是接近100%的问题。
4. 有一个patch: A fix to bug 7291739 is to set a new hidden parameter, _highthreshold_undoretention to set a high threshold for undo retention completely distinct from maxquerylen.
alter system set "_highthreshold_undoretention"=;
5. 增加undo表空间
alter tablespace UNDOTBS1 add datafile '+DATA1' size 30G;
6. 设置undo表空间的NOGUARANTEE
select tablespace_name, retention from dba_tablespaces where tablespace_name like 'UNDO%';
ALTER TABLESPACE UNDOTBS RETENTION NOGUARANTEE;
7. 减少UNDO_RETENTION的时间
SQL> show parameter undo
NAME TYPE VALUE
------------------ ---------------------- --------
undo_management string AUTO
undo_retention integer 10800
8. 重启数据库节点
3.3 故障分析及解决
我们查询ASH视图看看当时的情况:
SELECT D.SQL_ID,CHR(BITAND(P1, -16777216) / 16777215) ||
CHR(BITAND(P1, 16711680) / 65535) "Lock",
BITAND(P1, 65535) "Mode", COUNT(1),COUNT(DISTINCT d.session_id )
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN TO_DATE('2016-09-07 17:39:44', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2016-09-07 22:13:41', 'YYYY-MM-DD HH24:MI:SS')
AND D.EVENT = 'enq: US - contention'
GROUP BY D.SQL_ID,(CHR(BITAND(P1, -16777216) / 16777215) ||
CHR(BITAND(P1, 16711680) / 65535)),(BITAND(P1, 65535));

LOCK为US,MODE为6,看看具体的SQL内容:
SELECT A.SQL_TEXT, A.EXECUTIONS, A.MODULE, A.SQL_ID
FROM V$SQL A
WHERE A.SQL_ID IN ('5ww8x9u15a90y',
'ayngk81z8fh0m',
'1cmnjddakrqbv',
'26ad9zvt5xgb3');
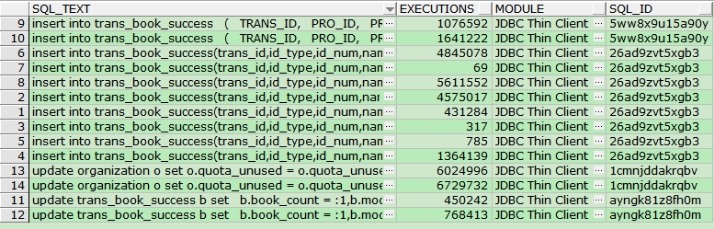
看看时间段是哪个区间:
SELECT D.SQL_ID, TO_CHAR(D.SAMPLE_TIME, 'YYYY-MM-DD HH24:MI'), COUNT(1)
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.EVENT = 'enq: US - contention'
AND D.SQL_ID IN ('5ww8x9u15a90y', '26ad9zvt5xgb3')
GROUP BY D.SQL_ID, TO_CHAR(D.SAMPLE_TIME, 'YYYY-MM-DD HH24:MI');

看来问题几种在这2分钟之内。基本都是对同一个表做插入或者更新操作:
SELECT DISTINCT D.CURRENT_OBJ#
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN
TO_DATE('2016-09-07 17:39:44', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2016-09-07 22:13:41', 'YYYY-MM-DD HH24:MI:SS')
AND D.EVENT = 'enq: US - contention'
GROUP BY D.CURRENT_OBJ#;
SELECT * FROM DBA_OBJECTS a WHERE a.object_id IN ('87620','87632','87663','87667','87686','87684','87688','87626','87646','87642','87639','87661','87628','87675','87643','87677','87660','87631','87629','87668','87682','87685','87654','87640','87627','87636','87664','87655','87645','87637','87669','87673','87666','87634','87644','87672','87648','87649','87662','87651','87641','87653','87659','87680','87681','0','87625','87670','87658','87674','87671','87633','87679','87647');
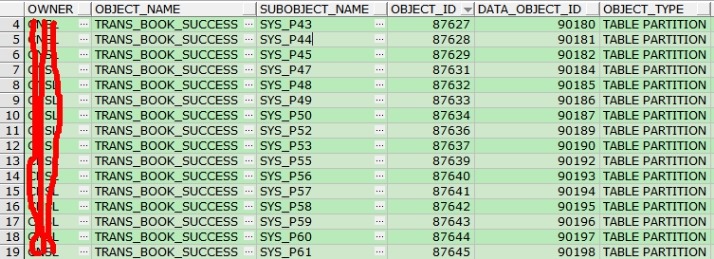
可以看到操作的表是一个分区表。
解决方案:
alter tablespace UNDOTBS1 add datafile '+DATA1' size 30G;
alter system set events '10511 trace name context forever,level 1';
ALTER SYSTEM SET "_rollback_segment_count"=1000 SID='*';
执行之后经过开发进行压测,已经没有该等待事件的产生了:
SELECT D.SQL_ID, TO_CHAR(D.SAMPLE_TIME, 'YYYY-MM-DD HH24:MI'), COUNT(1)
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.EVENT = 'enq: US - contention'
GROUP BY D.SQL_ID, TO_CHAR(D.SAMPLE_TIME, 'YYYY-MM-DD HH24:MI');
查询无数据。
About Me
..........................................................................................................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新,推荐pdf文件阅读
● QQ群:230161599 微信群:私聊
● 本文itpub地址:http://blog.itpub.net/26736162/viewspace-2124767/ 博客园地址:http://www.cnblogs.com/lhrbest/articles/5858001.html
● 本文pdf版:http://yunpan.cn/cdEQedhCs2kFz (提取码:ed9b)
● 小麦苗分享的其它资料:http://blog.itpub.net/26736162/viewspace-1624453/
● 联系我请加QQ好友(642808185),注明添加缘由
● 于 2016-09-08 09:00~2016-09-08 19:00 在中行完成
● 【版权所有,文章允许转载,但须以链接方式注明源地址,否则追究法律责任】
..........................................................................................................................................................................................................
长按识别二维码或微信客户端扫描下边的二维码来关注小麦苗的微信公众号:xiaomaimiaolhr,学习最实用的数据库技术。
