Kernel对象:
Kernel就是在程序代码中的一个函数,这个函数能在OpenCL设备上执行。一个Kernel对象就是kernel函数以及其相关的输入参数。

Kernel对象通过程序对象以及指定的函数名字创建。注意:函数必须是程序源代码中存在的函数。

运行时编译:
在运行时,编译程序和创建kernel对象是有时间开销的,但这样比较灵活,能够适应不同的OpenCL硬件平台。程序动态编译一般只需一次,而Kernel对象在创建后,可以反复调用。
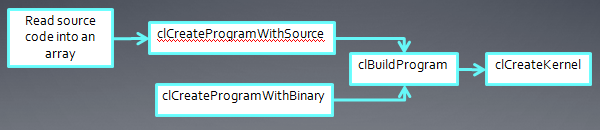
创建Kernel后,运行Kernel之前,我们还要为Kernel对象设置参数。我们可以在Kernel运行后,重新设置参数再次运行。

arg_index指定该参数为Kernel函数中的第几个参数(比如第一个参数为0,第二个为1,…)。内存对象和单个的值都可以作为Kernel参数。下面是2个设置Kernel参数的例子:
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&d_iImage);
clSetKernelArg(kernel, 1, sizeof(int), (void*)&a);
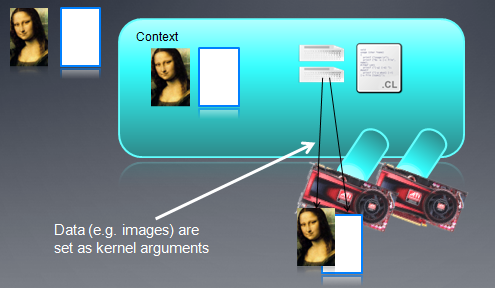
在Kernel运行之前,我们先看看OpenCL中的线程结构:
大规模并行程序中,通常每个线程处理一个问题的一部分,比如向量加法,我们会把两个向量中对应的元素加起来,这样,每个线程可以处理一个加法。
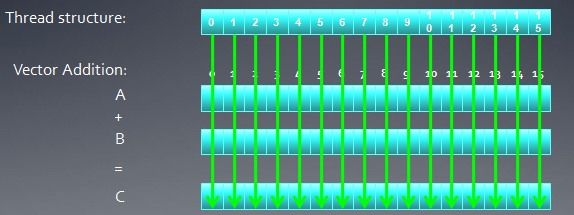
下面我看一个16个元素的向量加法:两个输入缓冲A、B,一个输出缓冲C

在这种情况下,我们可以创建一维的线程结构去匹配这个问题。

每个线程把自己的线程id作为索引,把相应元素加起来。
OpenCL中的线程结构是可缩放的,Kernel的每个运行实例称作WorkItem(也就是线程),WorkItem组织在一起称作WorkGroup,OpenCL中,每个Workgroup之间都是相互独立的。
通过一个global id(在索引空间,它是唯一的)或者一个workgroup id和一个work group内的local id,我就能标定一个workitem。
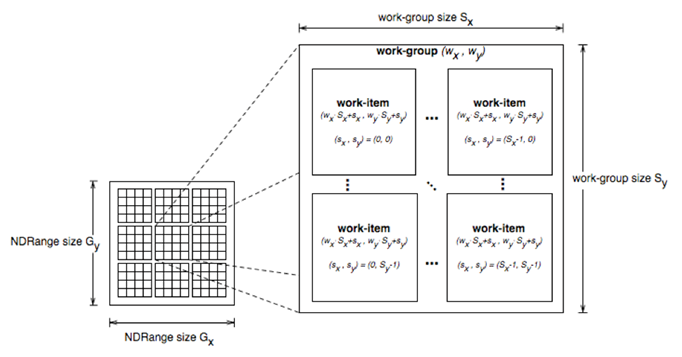
在kernel函数中,我们能够通过API调用得到global id以及其他信息:
get_global_id(dim)
get_global_size(dim)
这两个函数能得到每个维度上的global id。
get_group_id(dim)
get_num_groups(dim)
get_local_id(dim)
get_local_size(dim)
这几个函数用来计算group id以及在group内的local id。
get_global_id(0) = column, get_global_id(1) = row
get_num_groups(0) * get_local_size(0) == get_global_size(0)