来源:http://blog.csdn.net/ohmygirl/article/details/17846199
来源:http://www.cnblogs.com/forcertain/archive/2012/11/29/2795139.html
来源:http://www.cnblogs.com/Darren_code/archive/2011/09/28/Fiddler.html
Fiddler简介
1.为什么是Fiddler?
抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark.为什么使用fiddler?原因如下:
a.Firebug虽然可以抓包,但是对于分析http请求的详细信息,不够强大。模拟http请求的功能也不够,且firebug常常是需要“无刷新修改”,如果刷新了页面,所有的修改都不会保存。
b.Wireshark是通用的抓包工具,但是比较庞大,对于只需要抓取http请求的应用来说,似乎有些大材小用。
c.Httpwatch也是比较常用的http抓包工具,但是只支持IE和firefox浏览器(其他浏览器可能会有相应的插件),对于想要调试chrome浏览器的http请求,似乎稍显无力,而Fiddler2 是一个使用本地 127.0.0.1:8888 的 HTTP 代理,任何能够设置 HTTP 代理为 127.0.0.1:8888 的浏览器和应用程序都可以使用 Fiddler。
2.什么是Fiddler?
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。使用了Fiddler之后,web客户端和服务器的请求如下所示:
![]()
Fiddler 作为系统代理,当启用 Fiddler 时,IE 的PROXY 设定会变成 127.0.0.1:8888,因此如果你的浏览器在开启fiddler之后没有设置相应的代理,则fiddler是无法捕获到HTTP请求的。如下是启动Fiddler之后,IE浏览器的代理设置:
![]()
以Firefox为例,默认情况下,firefox是没有启用代理的(如果你安装了proxy等代理工具或插件,是另外一种情况),在firefox中配置http代理的步骤如下:
工具->选项->高级->网络->设置 。并配置相应的代理如下:
![]()
就可以使用Fiddler抓取Firefox的HTTP请求了。
3.Fiddler使用界面简介
Fiddler主界面的布局如下:
![]()
主界面中主要包括四个常用的块:
1.Fiddler的菜单栏,上图绿色部分。包括捕获http请求,停止捕获请求,保存http请求,载入本地session、设置捕获规则等功能。
2.Fiddler的工具栏,上图红色部分。包括Fiddler针对当前view的操作(暂停,清除session,decode模式、清除缓存等)。
3.web Session面板,上图黄色区域,主要是Fiddler抓取到的每条http请求(每一条称为一个session),主要包含了请求的url,协议,状态码,body等信息,详细的字段含义如下图所示:
![]()
4.详情和数据统计面板。针对每条http请求的具体统计(例如发送/接受字节数,发送/接收时间,还有粗略统计世界各地访问该服务器所花费的时间)和数据包分析。如inspector面板下,提供headers、textview、hexview,Raw等多种方式查看单条http请求的请求报文的信息:
![]()
而composer面板下,则可以模拟向相应的服务器发送数据的过程(不错,这就是灌水机器人的基本原理,也可以是部分http flood的一种方式)。
![]()
也可以粘贴一次请求的raw http headers,达到模拟请求的目的:
![]()
Filter标签则可以设置Fiddler的过滤规则,来达到过滤http请求的目的。最简单如:过滤内网http请求而只抓取internet的http请求,或则过滤相应域名的http请求。Fiddler的过滤器非常强大,可以过滤特定http状态码的请求,可以过滤特定请求类型的http请求(如css请求,image请求,js请求等),可以过滤请求报文大于或则小于指定大小(byte)的请求:
![]()
请多的过滤器规则需要一步一步去挖掘。
使用Fiddler抓包分析
Fiddler抓取HTTP请求。
抓包是Fiddler的最基本的应用,以本博客为例,启动Fiddler之后,在浏览器中输入http://blog.csdn.net/ohmygirl 键入回车之后,在Fiddler的web session界面捕获到的HTTP请求如下图所示:
![]()
各字段的详细说明已经解释过,这里不再说明。需要注意的是#号列中的图标,每种图标代表不同的相应类型,具体的类型包括:
![]()
另外,注意请求的host字段。可以看到有来自多个www.csdn.net的子域名的响应,说明在大型网站的架构中,大多需要多个子域名,这些子域名可能是单独用于缓存静态资源的,也可能是专门负责媒体资源的,或者是专门负责数据统计的(如pingback)。
右键单击其中的一条请求。可以选择的操作有:save(保存请求的报文信息,可以是请求报文,可以是响应报文)。例如,我们保存的一条请求头信息如下:
![]()
不仅是单条session,Fiddler还支持保存所有抓取到的session(并支持导入),这对于抓取可疑请求然后保存,并在之后随时分析这些请求是很有帮助的。
如果想要重新发送某些请求,可以选中这些请求,然后点击工具栏中的reply.就可以重新发送选中的这些请求。
左键点击单条HTTP请求,可以在右侧的tab面板中看到如下信息:
1. Statistic。
关于HTTP请求的性能和其他数据分析:
![]()
我们可以从中看出一些基本性能数据:如DNS解析的时间消耗是8ms,建立TCP/IP连接的时间消耗是8ms等等信息。
2. Inspectors。
分为上下两个部分,上半部分是请求头部分,下半部分是响应头部分。对于每一部分,提供了多种不同格式查看每个请求和响应的内容。JPG 格式使用 ImageView 就可以看到图片,HTML/JS/CSS 使用 TextView 可以看到响应的内容。Raw标签可以查看原始的符合HTTP标准的请求和响应头。Auth则可以查看授权Proxy-Authorization 和 Authorization的相关信息。Cookies标签可以看到请求的cookie和响应的set-cookie头信息。
![]()
3. AutoResponder
Fiddler比较重要且比较强大的功能之一。可用于拦截某一请求,并重定向到本地的资源,或者使用Fiddler的内置响应。可用于调试服务器端代码而无需修改服务器端的代码和配置,因为拦截和重定向后,实际上访问的是本地的文件或者得到的是Fiddler的内置响应。当勾选allow autoresponser 并设置相应的规则后(本例中的规则是将http://blog.csdn.net/ohmygirl的请求拦截到本地的文件layout.html),如下图所示
![]()
然后在浏览器中访问http://blog.csdn.net/ohmygirl,得到的结果实际为:
![]()
这刚好是本地layout.html的内容,说明请求已经成功被拦截到本地.当然也可以使用Fiddler的内置响应。下图是Fiddler支持的拦截重定向的方式:
![]()
因此,如果要调试服务器的某个脚本文件,可以将该脚本拦截到本地,在本地修改完脚本之后,再修改服务器端的内容,这可以保证,尽量在真实的环境下去调试,从而最大限度的减少bug发生的可能性。
不仅是单个url,Fiddler支持多种url匹配的方式:
I. 字符匹配
如 example可以匹配 http://www.example.com和http://example.com.cn
II. 完全匹配
以EXACT开头表示完全匹配,如上边的例子
EXACT:http://blog.csdn.NET/ohmygirl
III. 正则表达式匹配
以regex: 开头,使用正则表达式来匹配URL
如:regex:(?insx).*\.(css|js|PHP)$ 表示匹配所有以css,js,php结尾的请求url
4. Composer。
老版本的fiddler中叫request-builder.顾名思义,可以构建相应的请求,有两种常用的方式构建请求:
(1)Parsed 输入请求的url之后executed即可,也可以修改相应的头信息(如添加常用的accept, host, referrer, cookie,cache-control等头部)后execute.
这个功能的常见应用是:“刷票”(不是火车票!!),如刷新页面的访问量(基于道德和安全原因,如果你真去刷票,刷访问量,本博客概不负责)
(2)Raw。使用HTTP头部信息构建http请求。与上类似。不多叙述
5. Filter
Fiddler另一个比较强大的功能。Fiddler提供了多维度的过滤规则,足以满足日常开发调试的需求。如下图示:
![]()
过滤规则有:
a. host和zone过滤。可以过滤只显示intranet或则internet的HTTP请求
也可以选择特定域名的HTTP请求
![]()
b. client process:可以捕获指定进程的请求。
这对于调试单个应用的请求很有帮助。
其他更多的设置可以参考fiddler的官方文档。
Fiddler命令行和HTTP断点调试
一. Fiddler内置命令。
上一节(使用Fiddler进行抓包分析)中,介绍到,在web session(与我们通常所说的session不是同一个概念,这里的每条HTTP请求都成为一个session)界面中可以看到Fiddler抓取的所有HTTP请求.而为了更加方便的管理所有的session, Fiddler提供了一系列内置的函数用于筛选和操作这些session(习惯命令行操作Linux的童鞋应该可以感受到这会有多么方便).输入命令的位置在web session管理面板的下方(通过快捷键alt+q可以focus到命令行).
Fiddler内置的命令有如下几种:
1. select命令。
选择所有相应类型(指content-type)为指定类型的HTTP请求,如选择图片,使用命令select image.而select css则可以选择所有相应类型为css的请求,select html则选择所有响应为HTML的请求(怎么样,是不是跟SQL语句很像?)。如图是执行select image之后的结果:
![]()
2. allbut命令。
allbut命令用于选择所有响应类型不是给定类型的HTTP请求。如allbut image用于选择所有相应类型不是图片的session(HTTP请求),该命令还有一个别名keeponly.需要注意的是,keeponly和allbut命令是将不是该类型的session删除,留下的都是该类型的响应。因此,如果你执行allbut xxxx(不存在的类型),实际上类似与执行cls命令(删除所有的session, ctrl+x快捷键也是这个作用)
3. ?text命令
选择所有 URL 匹配问号后的字符的全部 session
4. >size 和 <size命令
选择响应大小大于某个大小(单位是b)或者小于某个大小的所有HTTP请求
5. =status命令
选择响应状态等于给定状态的所有HTTP请求。
例如,选择所有状态为200的HTTP请求:=200
6. @host命令
选择包含指定 HOST 的全部 HTTP请求。例如:@csdn.NET
选择所有host包含csdn.Net的请求
7. Bpafter, Bps, bpv, bpm, bpu
这几个命令主要用于批量设置断点
Bpafter xxx: 中断 URL 包含指定字符的全部 session 响应
Bps xxx: 中断 HTTP 响应状态为指定字符的全部 session 响应。
Bpv xxx: 中断指定请求方式的全部 session 响应
Bpm xxx: 中断指定请求方式的全部 session 响应。等同于bpv xxx
Bpu xxx:与bpafter类似。
当这些命令没有加参数时,会清空所有设置了断点的HTTP请求。
更多的其他命令可以参考Fiddler官网手册。
二. 使用Fiddler进行HTTP断点调试。
这是Fiddler又一强大和实用的工具之一。通过设置断点,Fiddler可以做到:
1. 修改HTTP请求头信息。例如修改请求头的UA, Cookie, Referer 信息,通过“伪造”相应信息达到达到相应的目的(调试,模拟用户真实请求等)。
2. 构造请求数据,突破表单的限制,随意提交数据。避免页面js和表单限制影响相关调试。
3. 拦截响应数据,修改响应实体。
为什么以上方法是重要的?假设js前端程序员和服务器程序员是分工合作的,js程序员想要调试Ajax请求的功能,这样便不必等待服务器端程序员开发好所有接口之后再开始开发js端的ajax请求功能,因为通过“模拟”真实的服务器端的响应,便可以保证功能的正确性,而服务器端开发程序员,只要保证最终的响应是符合规定的即可。这大大简化了程序开发的效率,当然也降低了不同业务线程序员联调的难度。
有两种方法设置断点:
1.fiddler菜单栏->rules->automatic Breakpoints->选择断点方式,这种方式下设定的断点会对之后的所有HTTP请求有效。
有两个断点位置:
a. before response。也就是发送请求之后,但是Fiddler代理中转之前,这时可以修改请求的数据。
b.after response。也就是服务器响应之后,但是在Fiddler将响应中转给客户端之前。这时可以修改响应的结果。
2.命令行下输入。Bpafter xxx或者bpv,bpu,bpm等设置断点。这种断点只针对特定类型的请求。
我们以本地的web项目为例,演示如何简单的设置HTTP断点:
1.首先设置Firefox的代理,使之可以抓取所有的HTTP请求(localhost的请求,也可以在filter中设置只抓取intranet请求),设置如下图所示:
![]()
2. 这时用web打开本地的项目。页面的内容为:
![]()
4. 设置响应后断点(after response breakpoint),可以通过命令行设置:bpafter localhost。键入回车之后,web再次访问文件,通过Fiddler的web session界面可以看到,请求已经被挂起来了,而web浏览器也一直处于加载的状态。观察右侧的inspector面板下,也出现了新的东西:
![]()
这时我们就可以修改响应的信息了。修改过程为:
切换到textView子面板,选择需要修改的部分,然后点击 “run to complete“,便可回送修改后的响应。假设我们修改后的内容如下:
![]()
点击执行后,打开刚刚的web界面。可以看到的页面的变化。
![]()
可见,页面的响应已经有了相应的变化。这就是响应后断点。当然实际应用中,断点的设置和响应的修改会比这复杂的多,这里只是基本的示例。
终止断点的方式有:
1. 在inspector界面点击“run complete“即会终止本次HTTP请求的断点。
2. 输入Go命令,也会使得当前的请求跳过断点。
3. 在rules->auto breakpoint中disabled断点即可。
总之,Fiddler的断点功能非常强大,关于它的进一步学习和应用,需要一个不断积累和摸索的过程。
工作原理
先上个图
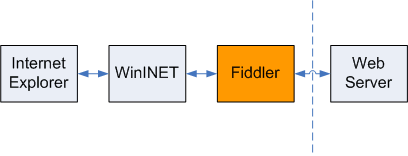
此图一目了然,可以看出fiddler在请求中所处的位置,我们就可以确定它能干些什么。
它实际工作在本机的8888端口http代理,我们启动fiddler时,它会自动更改代理设置:
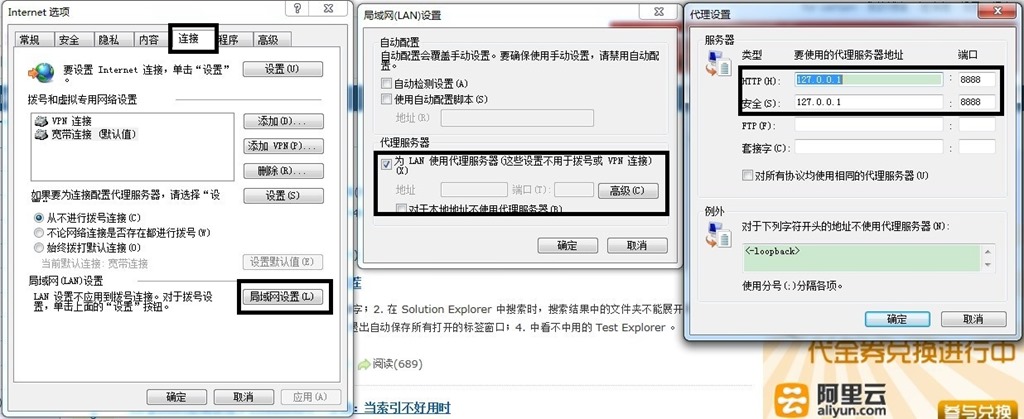
从此我们可以看出,只要是http的请求,在请求发起离开本机之前都会经过fiddler,当response回来,没有达到实际请求者时,也会经过fiddler:这样我们就可以在轻易的实现修改请求和响应的内容,这样我们就可以轻松的调试现网的程序。
与其它工具的区别
firebug、IE和chrome自带的开发者工具:这是前端开发的利器了,它们监听浏览器发起的请求和给浏览器的响应,显示请求数据和响应数据,这个fiddler基本功能一致,但它只是监听,只是对请求和响应数据的记录,而fiddler完全是接管了请求和响应。另外可以对呈现给浏览器html、css内容实现动态的修改,对页面制作人员简直有如再生父母的感觉;强大的js调试功能,前端开发人员的福音啊,这两点都是fiddler不具备的。
wireshark更变态了,貌似监视的是网卡,所有通过网卡的数据都会被记录。
下面说一下fiddler的强大功能。
fiddler强大功能之一 断点
在正式开始之前,我们就不介绍fiddler的基本界面了,可以看开头推荐的文章。
我们在命令输入区域输入help,回车会打开一页面,这个页面详细介绍了fiddler的所有命令,其中有关于断点的命令:bpu在请求开始里中断,bpafter在响应到达时中断,bps在特定http状态码时中断,bpv/bpm在特定请求method时中断。
除此之外,在菜单栏:
也可以设置断点,不过这个会对所有的请求,不太实用。
下面我们就以bpu为例来说一下断点功能:
1,以百度为例子,打开百度首页
2,在fiddler命令输入区输入 bpu www.baidu.com,这样就可中断url中包含这个地址的请求
3,然后在刚打开的百度页面输入fiddler点击搜索
4,此时我们会在fidller会话面板看到
红色小图标开头的会话,双击。
5,查看右边面板
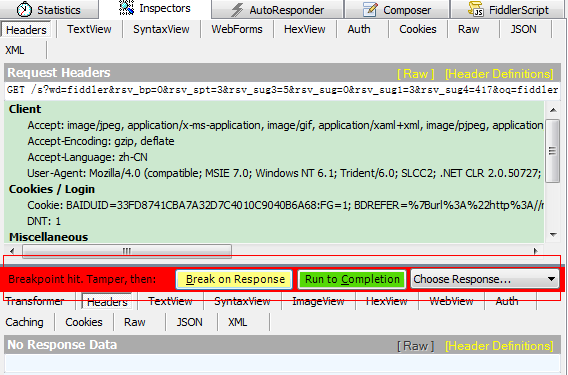
6,此在断点在请求未发出时,上半部分是请求的数据内容,切到webforms我们可以看到更直观的数据的请求数据:
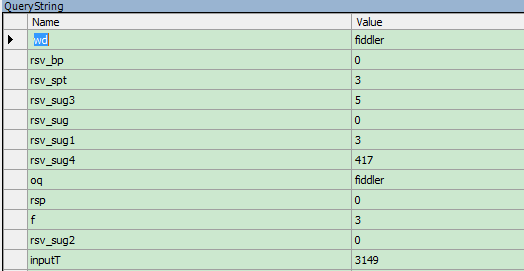
在这里我们可以看到wd和oq参数都是我们输入的关键字fiddler,可以修改,是的可以修改的,全部改成fiddler2。这里只是就实现修改了请求数据,其它的post数据,甚至是headers里的cookie、referer、user-agent等都可以修改。
7,看面板中间的

两个按钮和一个下拉选择框:break on response,点击这个按钮,就会在发出请求,在响应数据回到fiddler时再次中断;run to complete,点击就会正常处理,不会再中断请求。
打开下拉选择框:
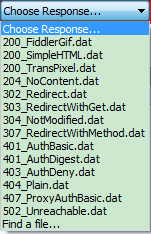
这里有很多的操作选择,就是选择输出内容,选择之后,实际的响应数据就会这些操作替代,特别是最后一个find a file:这个我们可以中断一个图片,然后这里选择本地的一张图片,这样我们就可以替换页面的图片。比较强大的场景就是例如现网js出了问题,但是一般现网的js是压缩过的,在firebug中根本无法调试,这样我们可以把它映射到本地的一个原始版本,这样firebug就会拿到一份原始的js,就可以方便的调试了。这个功能大家自己动手去实验吧。
8,点击break on response,这时在右边面板下部分就有内容了,就是响应内容,fiddler再次中断,响应内容已经回到本机,但是还在fiddler代理这里,还没有到浏览器。
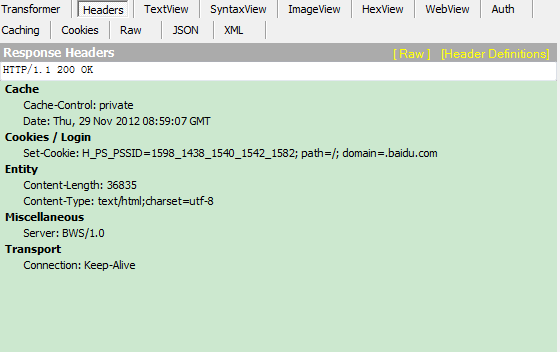
切到webview:
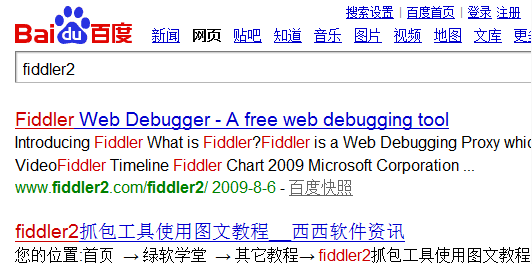
我们可以看到我们关键词已经变成了fiddler2,返回是fiddler2的搜索结果。
切到textview面板,我们可以看到返回的html内容,对,在这里,我们可以再次修改响应的内容,例如我们找到title标签加一些内容。
当然不只这些,我们知道firebug这些工具是不能修改js的,我们用fiddler就可以中断我们要修改的js文件,然后在这里修改部分代码,之后再借助firebug就可以完美调试现网代码。
9,看右边面板中间的操作区域,

此时我们仍然可以通过下拉选择特定的响应内容替代服务器的响应。
10,点击run to complete.
此时查看浏览器标签区:
是我们修改过的内容了。
另外:命令行输入 go 会断续执行所有中断,再次输入 bpu 会清除所有的断点。
fiddler强大功能之二 AutoResponder
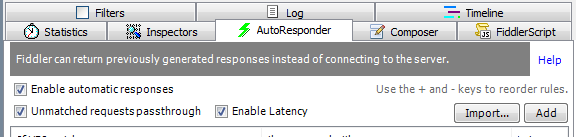
这个面板,这个功能和上边我们介绍的choose response的功能大概相同,就是针对一些匹配的请求,让请求者得到的我们指定的数据,而不是服务端返回的真实数据。
不过这个面板确定启用了建立好的规则之后,每次匹配都会使用指定的响应内容,比上边要每次中断时指定方便。
我们可以直接从左侧会话面板直接拖拉会话到这个面板,例如我们直接从左侧面板拖baidu的记录到这个面板,看下面的编辑区域

然后在第二行里,选择404_plain.dat,点击save保存。
面板中会有

这样的一条记录。
再去刷新baidu,会得到
就这样,我们就可以会为某一个请求如js的请求,返回本地的一个js数据,在配合firebug完美调试页面前端。
不想使用时,直接去此面板上面的勾,或者去掉某条规则上的勾。
fiddler强大功能之三 请求构造器
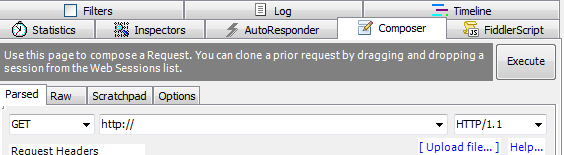
顾名思意,就是构造请求,然后点击execute按钮可以发起请求。
我们可以自己手动规定请求的各个内容,同样的我们可以从会话面板拖一个会话到此面板,此时面板会显示这个会话发起请求的所有数据,这样我们可以在此基础上修改这些数据,然后点击execute按钮来发起一次请求。
fiddler强大功能之四 自定义脚本
通过修改脚本文件,我们可以在fiddler本身的逻辑之上,加入自己的特殊处理。
我们可以
调出脚本进行修改,也可以在
![]()
这个面板上直接修改。
令广大.net同学高兴的是,fiddler本身是C#写的,再加上较为详细的注释,这个脚本文件对于我们来说还是比较容易上手的,具体自己去体会吧。
fiddler强大功能之五 性能测试
我们从会话列表中选择一个或多个会话,然后查看右边statistics面板:
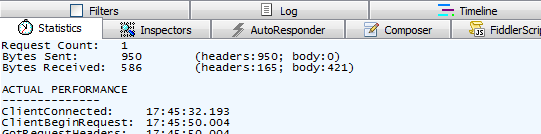
在这个面板中,我们可以看到这些请求各个阶段的时间,发送和接受数据量,还会有一个在世界不同地方访问这些请求一个评估。
最下面还有一个 show chat的链接点击我们可以看到一个直观的各种类型数据在总的数据的图形。
除了这些统计之外,我们还可以在会话列表查看,查看我们请求内容的是否做了浏览器缓存和缓存时间。
还可以在菜单中
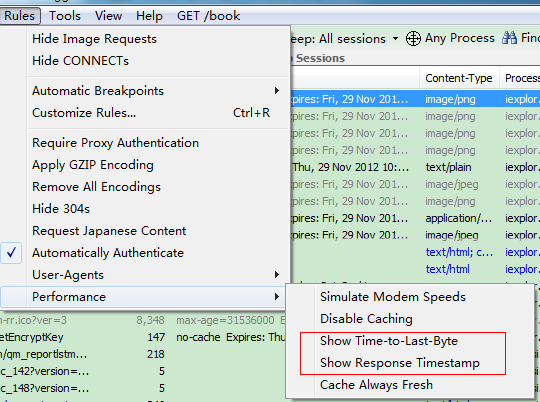
勾选这两项显示会话响应结束时间,同时在菜单的第二项和最后一项我们可以禁用或总启用浏览器的缓存。
看清楚这个菜单的第一项 对 模拟网速,当我们勾选这个项之后,然后在自定义脚本里找到:
|
1 2 3 4 5 6 |
|
它们分别是:每上传1KB数据时暂停300ms和每下载1KB数据时暂停150ms,我们可以通过修改这些值来达到模拟网速的效果。
另外,我们选择一个会话,然后在右侧
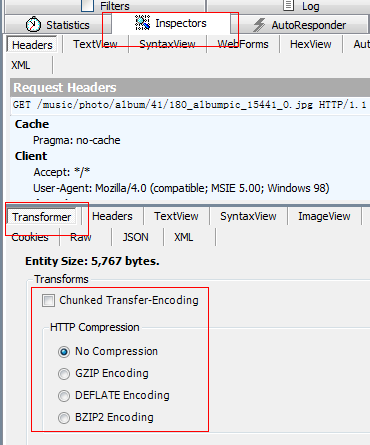
来查看这些请求是否启用了gzip压缩,然后选择各个压缩的字节大小,来直观的看到我们启用压缩之后能节省多少的数据流量。
fiddler强大功能之六 强大的命令
这里就不介绍了,在命令输入区域,输入help,回车之后,打开的页面上介绍挺全的,真的很强大。
fiddler强大功能之七 过滤器
你有时会不会打开fiddler来抓取这个页面的,但是其它的各种请求的数据也会被记录,然后再费劲查找,这时就启用过滤器吧。

启用之后,就可以根据自己的意志去加条件,不过这里不对这些做介绍,而是给大家说一个更简单的工具:
工具栏上
这个工具,我们鼠标摁住这个按钮,然后拖动到我们要抓取的浏览器标签页之上,然后松开,就会看到
这样的效果,这样fiddler就会只抓取该进程的请求。这个按钮还可以拖动到其它的任何程序上甚至是桌面上:
不过explorer貌似不会发起http请求,呵呵。
除了这些主要功能之外,fiddler的工具栏上提供了一些非常实用的其它功能,例如删除按钮,可以选择删除特定内容;keep:All sessions按钮,可以选择会话面板只保存多少个会话,查找,清理缓存等操作,最后说两个比较有挺有意思的:
1,工具栏的
点中之后,它会为那些编码的数据自动的解码,利于阅读。
2,工具栏差不多最右边有个工具
点击,弹出一个小工具:让我们可以进行各种形式的编码和解码。
3,最下方状态栏

左边一个点击下,可以让fiddler不再抓包,通过IE代理处可以查看,其实是清除了代理设置,再点击就可以再次开始抓包;右边这个按钮我们可以决定让fiddler抓取浏览器发起或其它程序发起的http请求。
细心查看,你也可能会发现fiddler其它强大的功能。不用多说,fiddler绝对是前端开发的利器,开发者工具firebug之类的配合可以解决很多前端开发中的很多问题。
Fiddler是啥?
百度百科里是这样介绍它的 - “Fiddler是一个web调试代理。它能够记录所有客户端和服务器间的http请求,允许你监视,设置断点,甚至修改输入输出数据,fiddler包含了一个强大的基于事件脚本的子系统,并且能够使用.net框架语言扩展。”
所以无论你是从事什么开发,哪种语言,只要你想了解HTTP,这个工具就值得你去了解,而且更重要的一点,这个工具是免费的。
Fiddler就是以代理服务器的方式,监听系统的网络数据流动。
启动Fiddler后,所发生的网络数据流通过Fiddler进行中转,就可以看到HTTP/HTTPS数据流的信息,我们就可以通过对这些信息加以分析。Fiddler还提供了清除IE缓存、请求构造器、文本转换工具等等一系列工具,对前端开发工作很有价值。
Fiddler的安装与下载:
Fiddler下载地址:http://www.fiddler2.com/fiddler2/
假如你是早期的XP版本的系统在安装的过程中会提示你下载.net framework 2.0或以上版本 。安装过程很简单,就不介绍了。
Fiddler的使用界面和功能介绍:![]()
监听开关 - 只有两种状态,用的时候就开着,不用就让丫休息。capturing表示捕捉状态
监听类型 - 四种状态分别对应 监听所有请求;监听浏览器请求,监听非浏览器请求,和全部隐藏(Hide All)
命令行 - 就不作介绍了,难者不会,会者不难。我就属于前者,悲剧呀...
请求列表 - 请求列表的信息分别有 结果(Result),协议(Protocol),主机名(Host),网页地址(URL),内容大小(Body),缓存(Caching),响应的HTTP内容类型(Content-Type),请求所运行的程序(Process),注释(Comments),自定义(Custom)
请求相关信息 - 右边这一大片都是数据流的相关信息的查看器,这些查看器提供很多查看形式,可以查看数据流的内容。
Fiddler请求列表的icon对应具体的数据类型和状态,其含义是:
![]()
Fiddler请求相关信息对应的主要功能:
工具最右方的是请求相关信息的查看器,提供了数据多方面的查看方式。想了解?看图片。
统计资料信息(Statistics)
![]()
强大的检查器(Inspectors) - 功能很多,等待你慢慢挖掘。
![]()
![]()
时间轴(Timeline)
![]()
自动回复器(autoResponder) - 一会就是介绍它的具体使用方法
![]()
说说我在工作中为什么使用Fiddler,如何使用Fiddler。
前端工程师在工作中总会有那么一些要求,要求书写的代码具有优良的兼容性,要求考虑代码的高性能,要求方法要面向对象,要求...前端工程师总是和浏览器兼容有很多不得不说的事。
条件1:在我们前端工程师开发的工作中,要调试服务器上某个HTML/CSS/JavaScript文件。一般情况下,我们都是将文件直接进行修改,然后重新发布再去做验证,这样就容易影响到测试环境或者生成环境的稳定性。更好的做法是,我们在本地开发环境中直接修改文件并进行验证,然后发布到测试环境,这样能保证测试环境的稳定,可是又比较繁琐。
条件2:现在我的情况是需要调试上线产品的浏览器兼容性问题,且我没有本地环境或者生成环境去测试。假如有Bug发生在Firefox或者Chrome这种有控制台支持调试的浏览器下一切都好说,可是假如bug只发生在遨游,TT,世界之窗,搜狗...这种的没有调试功能的浏览器下,而且你还碰见了我目前的情况,那么如果没有Fiddler这种工具,只能说这就是一场灾难。
Fiddler工具可以修改HTTP数据的特性,我们就非常便捷地基于生产环境修改并验证,确认后再发布。
第一步,先定位调试文件且下载。假设发现页面中的某个文件有问题(HTML/CSS/JavaScript都行),那么我们需要做的是就把他先下载到本地(如果本地有这个本地那么可以跳过此步骤),下载到本地的文件偶尔会有乱码的情况,建议你先清理浏览器缓存或者调整注册表(Fiddler2中文乱码问题)。使用细节如下:
![]()
第二步,Fiddler - autoResponder出场,开启此功能。打开AutoResponder标签设置。可以看到界面上有三个选择框,第一个的作用是开启或禁用自动重定向功能,我们就可以在下面添加重定向规则了;第二个选择框被勾上时,不匹配的请求可以通过,不影响那些没满足我们处理条件的请求。
![]()
第三步,创建重定向规则,将目标是这个js的HTTP请求重定向到本地文件。选中刚刚定位的文件,通过“Add…”按钮增加规则,也可以直接拖动过来。
![]()
第四步,选择本地刚刚保存的文件或者替换的文件,作为替换这个请求的内容。
![]()
第五步,你调试或者不调试,它就在那里 - 只会请求你本地的选择的那个文件。所以,想怎么修改都随便你了。刷新页面,就可以看见这个alert了。
![]()
总结:虽然介绍时一共分为5个步骤,其实只要用习惯了很随意就可以调试了。快速前端调试其实很简单,你说类。