更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
作者介绍:irek Stanek
Azimo移动开发部门负责人,人工智能专家。自称梦想很大却在写代码,更多开发博客见http://frogermcs.github.io/
AI工程师的一项必须技能就是理解并能解释领域内的高度技术性的论文。我在AI Nanodegree课程中的一个课题就是分析《自然》杂志上关于AlphaGo的一篇文章——《Google Deepmind system which for the first time in history beat elite professional Go player, winning by 5 games to 0 with European Go champion — Fan Hui》。这篇文章的目的是为了使得这些知识更通俗易懂,尤其是对初学者和首次接触的人。
AlphaGo和数学
AlphaGo是谷歌DeepMind小组研发的针对围棋的AI。而在AlphaGo 出现之前,有预测称根据现有的最新技术,能击败人类职业围棋选手的AI还要十年才会出现。
为什么围棋比国际象棋简单,但是却引起了这么多的关注?
是因为复杂性。
围棋和国际象棋都是完美信息的游戏,每个玩家完全知道以前发生过的所有事件,因此游戏存在最优解。如果使用搜索树的方法寻找最优解,国际象棋存在10¹²³种解,而围棋存在10³⁶⁰种解(译者注:可以简单理解为围棋棋盘比较大因此解多)。而一般的多核处理器每秒钟可以做10⁹次运算,意味着如果要算尽围棋的解需要花费的时间比宇宙存在的时间还要长。
AlphaGo和其他AI游戏程序的最高级别目标是有效减少搜索空间,在合理的时间(AlphaGo的每次运动时间为5s)内,尽可能快的结束游戏。
为了估计每个游戏状态的价值,AlphaGo使用蒙特卡罗树搜索(MCTS)——通过基于搜索空间的随机抽样扩展搜索树——来分析最优的动作。 MCTS在游戏中基于许多playouts来运作,这些playouts是在随机落子的游戏中生成的;每个playout的结果都倍用来衡量游戏树中不同节点的权重,这样在未来的playouts中,好的节点更有可能被选中。通过附加策略增强的MCTS(例如预测人类专家动作)使我们有可能实现strong-amateur级别游戏。
下一步会基于预先训练好的深度卷积网络。这种技术现在广泛用于图像分类、人脸识别或玩Atari游戏。旁注:人们可以从Facebook的Intro to AI movies开始了解深度学习或卷积网络的工作原理。
AlphaGo使用神经网络的目标是:有效位置评估(价值网络)和行动抽样(策略网络)。
策略网络
为了训练策略网络,机器学习有两个阶段。
第一阶段是监督学习(SL)(它扩展了MCTS解决方案,用于预测人类职业棋手的行动)。 SL策略网络已经根据KGS Go Server的3000万个案例进行了训练。经过训练的网络能够准确预测专家行动,准确率高达57%(其他研究团队最高为44.4%)。
然而虽然新的准确性提高了,但评估速度明显较慢。因此有了另一个被称为快速推出(FR)的策略。它不太准确(27%),但更快(2μs至3ms),被用于在评估MCTS中的节点时运行rollouts一直到游戏结束。
第二阶段是增强学习(RL)。SL擅长预测下一个最有可能的行动,而RL能够预测最能够获胜的行动。在这个阶段,AlphaGo通过随机选择迭代之前的自己进行了120万场游戏。
相比RL,SL能够赢得超过80%的游戏;而与Pachi相比,这个数值高达85%(Pachi是一个基于蒙特卡洛树搜索启发式的开源程序,在KGS业余爱好者中排第二)。而之前的基于SL的解决方案在对阵Pachi时,只能够赢得约11%的游戏。
价值网络
训练的最后阶段主要集中在位置评估(position evaluation)(估计当前行动的获胜概率)。对KGS数据集的训练会导致过拟合,为了防止这种情况,新的训练集是由自动播放数据产生的(3000万个不同的位置,每个都是从不同的游戏种抽取的) 。
训练价值函数比使用rollout策略的蒙特卡洛算法更准确,其单次评估准确率与使用强化学习策略的蒙特卡罗算法类似(但计算量减少了15000倍)。
策略和价值网络搜索
AlphaGo在蒙特卡罗搜索树中使用策略和价值网络的组合。游戏树的搜索由下面4个阶段组成: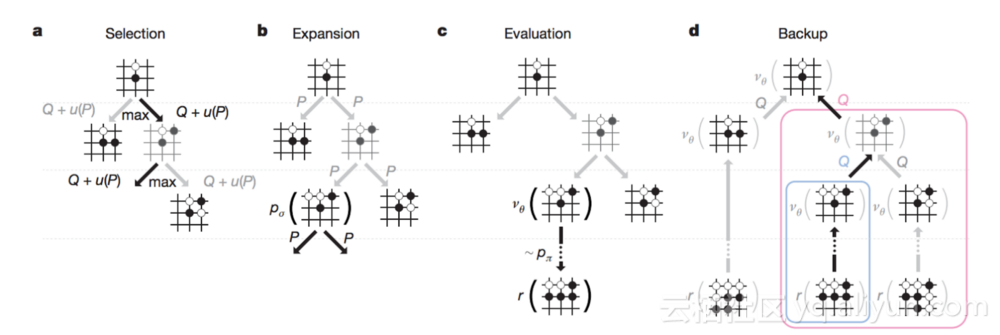
- 选择 - 模拟通过选择具有最大动作值Q(这个移动有多好)的edge来遍历树。
- 扩展 - 如果任何节点被扩展,则由SL策略网络处理一次,以获得每个行动的先验概率。
- 评估 - 每个节点通过价值网络和FR策略进行评估。
- 备份 - 动作值Q由评估步骤收集的值进行更新。当游戏代理的时间结束时,通过最高动作值Q选择最佳移动。
结果
AlphaGo的表现是众所周知的。在2015年,它击败人类职业棋手樊麾,欧洲多个联赛的冠军。这是机器第一次在围棋中击败了职业棋手。在与其它最好的围棋程序(如Crazy Stone, Pachi, Zen等)进行的比赛模拟中,AlphaGo获胜率高达99.8%。 AlphaGo的分布式版本对单机版本的胜率为77%,意味着它不仅表现强劲,而且还具有很好的可扩展性。在与樊麾的比赛中,AlphaGo花费的步数要比当年深蓝大战Kasparov少了1000倍,意味着落子更加智能。
这些所有结论清楚地表明,多亏了AlphaGo,我们在寻找General AI and the Singularity的路上又近了一步。