1.2 短文本理解研究现状
1.2.1 短文本理解模型概述
本节根据短文本理解所需知识源的属性,将短文本理解模型分为三类:隐性(implicit)语义模型、半显性(semiexplicit)语义模型和显性(explicit)语义模型。其中,隐性和半显性模型试图从大量文本数据中挖掘出词与词之间的联系,从而应用于短文本理解。相比之下,显性模型使用人工构建的大规模知识库和词典辅助短文本理解。
1隐性语义模型
隐性语义模型产生的短文本表示通常为映射在一个语义空间上的隐性向量。这个向量的每个维度所代表的含义人们无法解释,只能用于机器计算。以下将介绍几种代表性的隐性语义模型。
隐性语义分析(Latent Semantic Analysis,LSA)模型:最早的基于隐性语义的文本理解框架为LSA模型[54],也被称为Latent Semantic Indexing(LSI)模型。LSA模型旨在用统计方法分析大量文本从而推出词与文本的含义表示,其思想核心是在相同语境下出现的词具有较高的语义相关性。具体而言,LSA模型构建一个庞大的词与文本的共现矩阵。对于每个词向量,它的每个维度都代表一个文本;对于每个文本向量,其每个维度代表一个词。通常,矩阵每项的输入是经过平滑或转换的共现次数。常用的转换方法为TFIDF。最终,LSA模型通过奇异值分解(SVD)的方法将原始矩阵降维。在短文本的情境下,LSA模型有两种使用方式。首先,在语料足够多的离线任务上,LSA模型可以直接构建一个词与短文本的共现矩阵,从而推出每个短文本的表示。其次,在训练数据量较小的情境下,或针对线上任务(针对测试数据),可以事先通过标准的LSA模型方法得到每个词向量,然后使用额外的语义合成方式获取短文本向量。
超空间模拟语言(Hyperspace Analogue to Language,HAL)模型:一个与LSA模型类似的模型是HAL模型[96]。HAL模型与LSA模型的主要区别在于前者是更加纯粹的词模型。HAL模型旨在构建一个词与词的共现矩阵。对于每个词向量,它的每个维度代表一个语境词。该模型统计目标词汇与语境词汇的共现次数,并经过相应的平滑或转换(如TFIDF、Pointwise Mutual Information(PMI)等)得到矩阵中每个输入的值。通常,语境词的选取有较大的灵活性。例如,语境词可被选为整个词汇,或者除停止词外的高频词[159]。类比LSA模型,在HAL模型中可以根据原始向量的维度和任务要求选择是否对原始向量进行降维。由于HAL模型的产出仅仅为词向量,在短文本理解这一任务中需采用额外的合成方式(如向量相加)来推出短文本向量。
神经语言模型(Neural Language Model,NLM):近年来,随着神经网络和特征学习的发展,传统的HAL模型逐渐被NLM[20,114,110,45]取代。与HAL模型通过明确共现统计构建词向量的思想不同,NLM旨在将词向量当成待学习的模型参数,并通过神经网络在大规模非结构化文本的训练来更新这些参数以得到最优的词语义编码(常被称作Word Embedding)。
最早的概率性NLM由Bengio等提出[20]。其模型使用前向神经网络(Feedforward Neural Network)根据语境预测下一个词出现的概率。通过对训练文本中每个词的极大似然估计,模型参数(包括词向量和神经网络参数)可使用误差反向传播(BP)算法进行更新。此模型的缺点在于仅仅使用了有限的语境。后来,Mikolov等[114]提出使用递归神经网络(Recurrent Neural Network)来代替前向神经网络,从而模拟较长的语境。此外,原始NLM的计算复杂度很高,这主要是由于网络中大量参数和非线性转换所致。针对这一问题,Mikolov等[110]提出两种简化(去掉神经网络权重和非线性转换)的NLM,即Continuous Bag of Words(CBOW)和Skipgram。前者通过窗口语境预测目标词出现的概率,而后者使用目标词预测窗口中的每个语境词出现的概率。
另一类非概率性的神经网络以Collobert和Weston的工作[45]为代表。其模型Senna考虑文本中的n元组。对每个n元组中某个位置的词(如中间词),模型选取随机词来代替该词,从而产生若干新的n元组作为负样本。在训练中,一个简单的神经网络为n元组打分,训练目标为正样本得分s+与负样本得分s-间的最大间隔排序损失(maxmargin ranking loss):
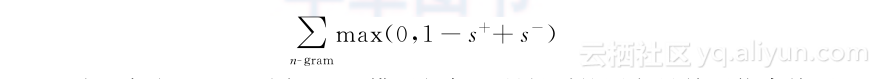
总而言之,NLM同HAL模型相似,所得到的词向量并不能直接用于短文本理解,而需要额外的合成模型依据词向量得到短文本向量。
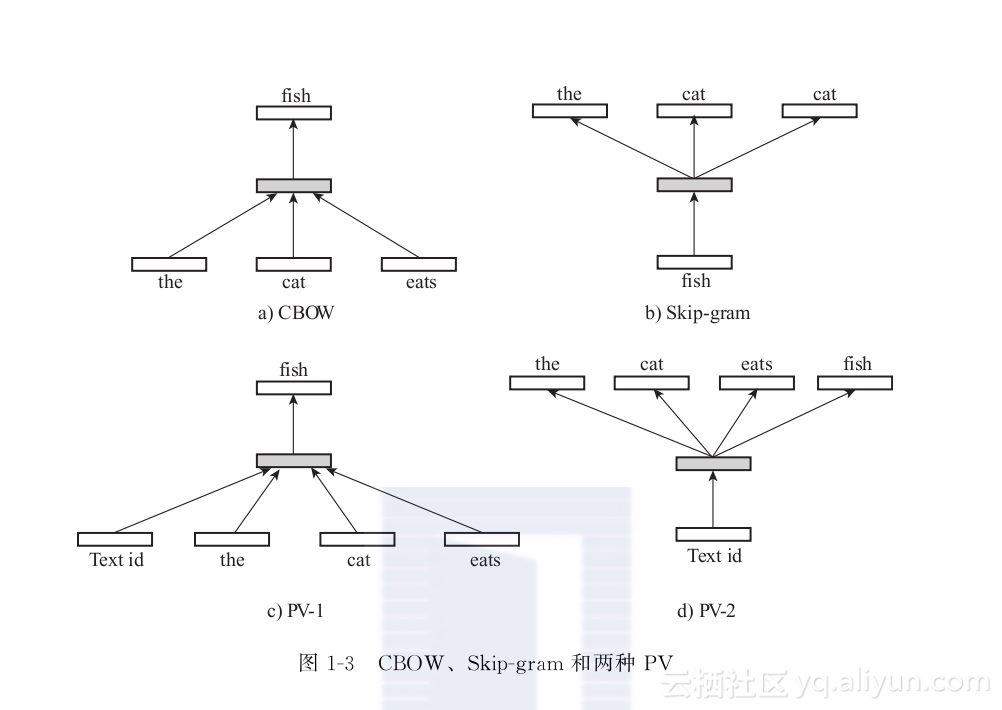
段向量(Paragraph Vector,PV):PV[98]是另一种基于神经网络的隐性短文本理解模型。PV可被视作CBOW和Skipgram的延伸,可直接应用于短文本向量的学习。PV的核心思想是将短文本向量当作“语境”,用于辅助推理(例如,根据当前词预测语境词)。在极大似然的估计过程中,文本向量亦被作为模型参数更新。PV的产出是词向量和文本向量,对于(线上任务中的)测试短文本,PV需要使用额外的推理获取其向量。图13比较了CBOW、Skipgram和两种PV的异同。
2半显性语义模型
半显性语义模型产生的短文本表示方法也是一种映射在语义空间里的向量。与隐性语义模型不同的是,半显性语义模型的向量的每一个维度是一个“主题”(topic),这个主题通常是一组词的聚类。人们可以通过这个主题猜测这个维度所代表的含义。但是这个维度的语义仍然不是明确、可解释的。半显性语义模型的代表性工作是主题模型(topic model)。
主题模型:最早的主题模型为LSA模型的延伸。LSA模型尝试通过线性代数(奇异值分解)的处理方式发现文本中的隐藏语义结构,从而得到词和文本的特征表示;而主题模型则尝试从概率生成模型(Generative Model)的角度分析文本语义结构,模拟主题这一隐藏参数,从而解释词与文本的共现关系。
最早的主题模型Probabilistic LSA(PLSA)模型由Hofmann等提出[70]。PLSA模型假设文本具有主题分布,而文本中的词从主题对应的词分布中抽取。以d表示文本,w表示词,z表示主题(隐藏参数),Z表示主题集合,则文本和词的联系概率p(d,w)的生成过程可被表示如下:
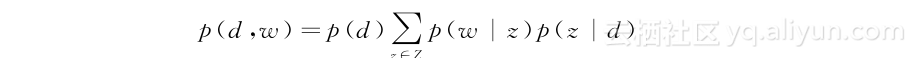
虽然PLSA模型可以模拟每个文本的主题分布,然而其没有假设主题的先验分布(每个训练文本的主题分布相对独立),它的参数随训练文本的个数呈线性增长,且无法应用于测试文本。
一个更加完善的主题模型为LDA模型(Latent Dirichlet Allocation Model)[29]。LDA模型从贝叶斯的角度为两个多项式分布添加了狄利克雷先验分布,从而解决了PLSA模型中存在的问题。在LDA模型中,每个文本的主题分布为多项式分布Mult(θ),其中θ从狄利克雷先验Dir(α)中抽取。同理,对于主题的词分布Mult(φ),其参数φ从狄利克雷先验Dir(β)获取。图14对比了PLSA模型和LDA模型的盘子表示法(Plate notation)。
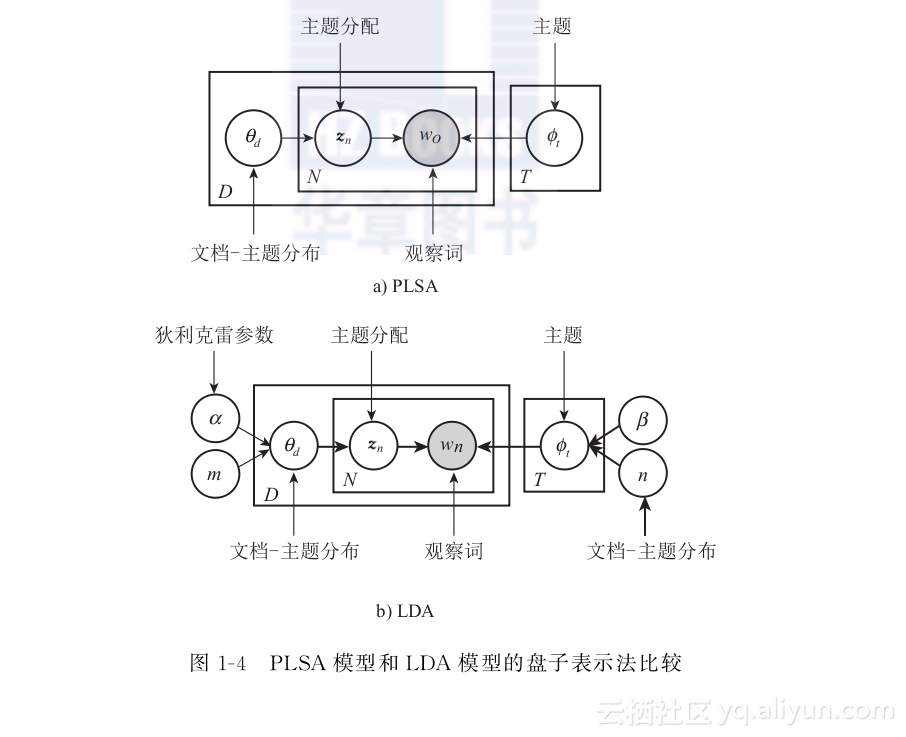
总之,通过采用主题模型对短文本进行训练,最终可以获取每个短文本的主题分布,以作为其表示方式。这种方法将短文本转为了机器可计算的向量。
3显性语义模型
近年来,随着大规模知识库系统的出现(如Wikipedia、Freebase、Probase等),越来越多的研究关注于如何将短文本转化成人和机器都可以理解的表示方法。这类模型称为显性语义模型。与前两类模型相比,显性语义模型最大的特点就是它所产生的短文本向量表示不仅是机器可用于计算的,也是人类可以理解的,每一个维度都有明确的含义,通常是一个明确的“概念”(concept)。这意味着机器将短文本转为显性语义向量后,人们很容易就可以判断这个向量的质量,并发现其中的问题,从而方便进一步的模型调整与优化。
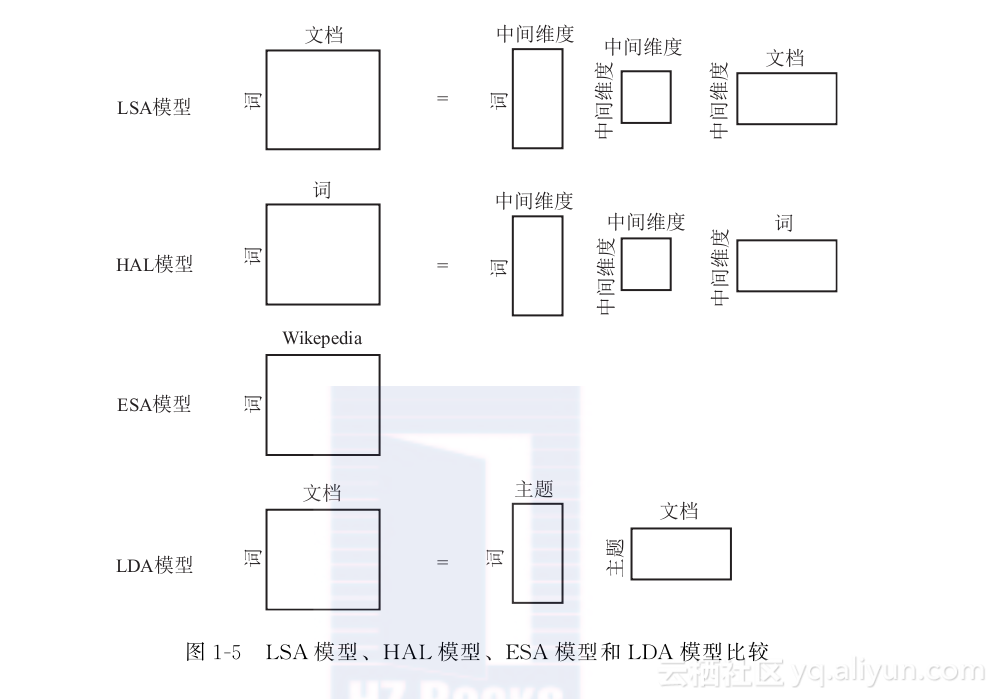
显性语义分析(Explicit Semantic Analysis,ESA)模型:在基于隐性语义的模型中,(低维)向量的每个维度并没有明确的含义标注。与之相对的是显性语义模型,向量空间的构建由知识库辅助完成。最具代表性的显性语义模型为ESA模型[66]。ESA模型同LSA模型的构建思路一致,旨在构建一个庞大的词与文本的共现矩阵。在这个矩阵中,每个输入为词与文本的TFIDF。然而,在ESA模型中词向量的每个维度代表一个明确的知识库文本,如Wikipedia文章(或标题)。此外,原始的ESA模型没有对共现矩阵进行降维处理,因而产生的词向量具有较高维度。在短文本理解这一任务中,需使用额外的语义合成方法推导出短文本向量。图15比较了LSA模型、HAL模型、ESA模型和LDA模型的区别与联系。
概念化(Conceptualization):另一类基于显性语义的短文本理解方法为概念化[153,90,77,172]。概念化旨在借助知识库推出短文本中每个词的概念分布,即将词按语境映射到一个以概念为维度的向量上。在这一任务中,每个词的候选概念可从知识库中明确获取。例如,通过知识库Probase[166],机器可获悉apple这个词有fruit和company这两个概念。当apple出现在“apple ipad”这个短文本中,通过概念化可分析得出apple有较高的概率属于company这个概念。
最早的概念化方法由Song等提出[153]。其模型使用知识库Probase,获取短文本中每个词与概念间的条件概率p(concept|word)和p(word|concept),从而通过朴素贝叶斯方法推出每个短文本的概念分布。这一单纯基于概率的模型无法处理由语义相关但概念不同的词组成的短文本(如“apple ipad”)。为解决无法识别语境的问题,Kim等[90]对Song的模型做出了改进。新的模型使用LDA主题模型,分析整条短文本的主题分布,进而计算p(concept|word,topic)。
另一个基于Probase的短文本理解框架为Hua等提出的Lexical Semantic Analysis(LexSA)[77]。LexSA将短文本理解系统化为分词、词性标注和概念识别三个步骤,并在每个步骤使用新的模型消除歧义。在分词和词性标注环节,作者分别使用图模型推出短文本的最优分词方式和词的词性;在概念识别环节,每个词被表示成以概念为维度的向量。为了进一步强调LexSA中各环节的相互作用关系,Wang等[172]提出为短文本构建统一的候选词关系图,并使用随机游走(Random Walk)的方法推出最优的分词、词性和词的概念。
1.2.2 短文本理解模型粒度分析
从另一个角度而言,短文本理解模型在文本分析上的粒度也有差异。部分方法直接模拟短文本的表示方式,因此本节将其归为“文本”粒度。其余大多数方法则以词为基础,这些方法首先推出每个词的表示,然后使用额外的合成方式推出短文本的表示。本节将这些方法归为“词”粒度。本节将深入讨论121节中的短文本理解模型在文本分析粒度上的差异,并从应用层面论证方法的适用性。
1文本粒度模型
首先,文本粒度的模型包含LSA模型、LDA模型和PV。这些模型均尝试直接推导出短文本的向量表示作为模型的输出。在LSA模型中,通过构建一个词与文本的共现矩阵,每个文本可用以词为维度的向量表示。作为结果,可得到每个文本的主题分布。PV通过神经网络推测(inference)的方式获取文本向量的最优参数。上述模型所得的文本向量均可以直接用于与这些文本相关的任务,如文本分类[139,154]、聚类[173]和摘要生成[64]。值得注意的是,LSA模型同时输出词向量。因而在短文本数量不足的情况下,可以先采用基于大量完整文本的LSA模型获取词向量,再通过额外的合成方法获取短文本向量。对于LDA模型和PV而言,其模型亦可以通过额外的文本训练,然后应用于短文本。
2词粒度模型
同LSA模型、LDA模型和PV相比,其他模型(NLM、ESA模型等)均属于词粒度模型,因为这些模型的产出仅为词向量。针对短文本理解这一任务,必须使用额外的合成手段来推出短文本的表示。例如,在参考文献[59,26,71]等工作中,作者均利用词向量推导出文本表示,并用于后续的文本相似度判断、文本复述、情感分析等任务。这里的一个特例为概念化模型,由于概念化可以直接基于语境推出短文本中每个词的概念,这样的输出方式已经可以满足机器短文本理解的需求。因而概念化虽属于词粒度的模型但并不需要额外的文本合成。
3文本合成
如何通过词向量获取任意长度的文本向量(包括短文本)是时下流行的一个研究领域。根据复杂度的不同,文本合成方法可被大致分为代数运算模型[159,59,26,116,63]、张量模型[43,34,84]和神经网络模型[114,145,148,85,91]。
代数运算模型:最早的合成模型由Mitchell和Lapata[116]提出。其模型使用逐点的(pointwise)向量相加的方式从词向量推出文本向量。虽然这一基于“词袋”的方法忽略了句子中的词序(“cat eats fish”和“fish eats cat”将有相同的表示),但事实表明其在很多自然语言处理任务上有着不错的效果,且其常常被用作复杂模型的基准[26]。类似的代数运算模型还有逐点的向量乘积[159,59,26]以及乘法与加法的结合运算[63]。
张量模型:张量模型[43,34]为代数运算模型的延伸,其试图强调不同词性的词在语义合成中的不同角色。例如在red car这个词组中,形容词red对名词car起修饰作用。而在eat apple中,动词eat的角色好比作用于apple的函数。从这个角度而言,将不同词性的词均表示为同等维度的向量过于简化。因而,在张量模型中不同词性的词被表示为不同维度的张量,整个句子的表示方式以张量乘法的形式获取。目前,张量模型的最大挑战是如何获取向量与张量的映射关系[84]。
神经网络模型:时下最为流行的文本合成模型为基于神经网络的模型,如Recursive Neural Network(RecNN)[145,148]、Recurrent Neural Network(RNN)[114]、Convolutional Neural Network(CNN)[85,91]等。在这些模型中,最基本的合成单元为神经网络。通常的形式为神经网络根据输入向量x1、x2推出其组合向量y:
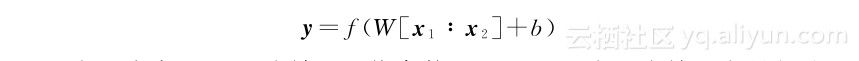
在上式中W和b为神经网络参数,[x1∶x2]为两个输入向量相连,f为非线性转换。
在具体的文本合成中,不同的神经网络模型的构造不同。例如,RecNN依赖于语法树开展逐层的语义合成,它无法被用于短文本。相比之下,RNN(序列合成)和CNN(卷积合成)都可以通过词向量快速推导出短文本向量。