1.3 写WordCountMapReduce示例程序,打包并使用独立的Hadoop运行它
Hadoop MapReduce实战手册
本节传授如何写一个简单的MapReduce程序,以及如何执行它,如图1-1所示。
![]()
要运行MapReduce作业,用户需要提供一个map函数、一个reduce函数、输入数据,以及输出数据的位置。在执行时,Hadoop实际执行如下步骤。
- Hadoop通过换行符将输入数据分解成多个数据项,并且在每一个数据项上运行一次map函数,将这个数据项作为对应map函数的输入。执行完成时,每个map函数输出一个或者多个键值对。
- Hadoop收集所有map函数产生的键值对,并且通过键对它们进行排序,将具有相同值的键值对分成一组。
- 对于每一个不同的键,Hadoop会运行一次reduce函数,该函数的输入是这个键和它所对应的值的列表。
- reduce函数会输出一个或多个键值对,然后Hadoop将它们作为最终结果写入文件。
准备工作
从本书所对应的源代码中,选择第1章所对应的源代码,即chapter1_src.zip。然后,使用你喜欢的Java集成开发环境(IDE),例如Eclipse,导入源代码。你需要将HADOOP_HOME中名为hadoop-
core的JAR文件和HADOOP_HOME/lib目录下的所有其他JAR文件都添加到IDE的类路径(classpath)下。
从http://ant.apache.org/下载并安装Apache Ant。
操作步骤
现在来写我们的第一个Hadoop MapReduce程序。
- WordCount示例的输入是一组文档,使用MapReduce来对文档集合中的每个单词进行计数。可以从src/chapter1/Wordcount.java找到示例代码。这段代码有三部分:mapper、reducer和主程序。
- mapper实现org.apache.hadoop.mapreduce.Mapper接口。Hadoop运行时,接收输入文件中的每一行作为mapper的输入。map函数使用空白字符作为分隔符,将每一行分解成为多个子串,并且为每个子串(单词)输出一个(word, 1)键值对作为函数输出。
public void map(Object key, Text value, Context context
)throws IOException, InterruptedException
{
StringTokenizeritr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, new IntWritable(1));
}
}
3```
. reduce函数接收所有具有相同键的值作为输入,将该键和该键出现的次数作为输出。
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritableval : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
4. main程序将配置放在一起,并将作业提交给Hadoop运行。
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).
getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
//Uncomment this to
//job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
5. 你可以通过下列命令从示例代码的根目录编译示例程序,该命令使用Apa
che Ant:
ant build
如果还没有准备好Apache Ant,那么应该按照http://ant.apache.org/manual/install.html上给出的说明安装Apache Ant。或者,也可以使用包含源代码的编译好的JAR文件。
6. 将目录跳转到HADOOP_HOME,并且将hadoop-cookbookchapter1.jar文件复制到HADOOP_HOME目录。在HADOOP_HOME下创建一个名为input的目录,并将README.txt文件复制到这个目录下。或者,也可以将任意的文本文件复制到这个input目录。
7. 使用下列命令运行示例程序。在这里,chapter1.WordCount是我们需要运行的main类的名称。在运行该命令时,会在终端看到下面的输出:
bin/hadoop jar hadoop-cookbook-chapter1.jar chapter1.WordCount
input output
12/04/11 08:12:44 INFO input.FileInputFormat: Total input paths to
process : 16
12/04/11 08:12:45 INFO mapred.JobClient: Running job: job_local_0001
12/04/11 08:12:45 INFO mapred.Task: Task:attempt_local_0001_m_000000_0
is done. And is in the process of commiting
...
...
12/04/11 08:13:37 INFO mapred.JobClient: Job complete: job_local_0001
...
8. 在输出目录中有一个文件名类似于part-r-XXXXX的文件,该文件用于存放文档中每一个单词的计数。恭喜!你已经成功地运行了自己的第一个MapReduce程序。
工作原理
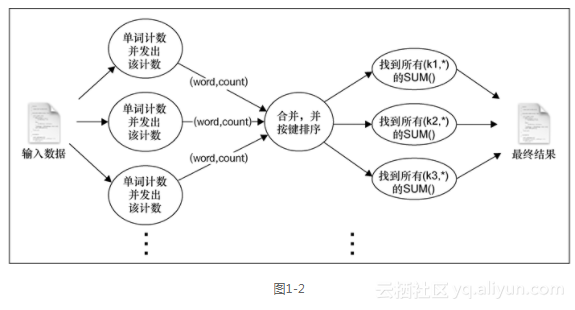
在前面的示例中,MapReduce在本地模式下工作,没有启动任何服务进程,而是使用本地文件系统作为输入、输出和工作数据的存储系统。图1-2显示了WordCount程序幕后发生的事。
<span style='display:block;text-align:center'>
</span>
工作流如下。
1. Hadoop读取输入,以换行符为分隔符将其拆成行,然后以每行作为参数运行map函数。
2. map函数对行进行标记化处理,为每个标记(单词)输出一个键值对(word,1)。
3. Hadoop收集所有的(word,1)对,按word对其进行排序,按每个不同的键对输出的值进行分组,以键及该键的所有值为参数对每个不同的键调用一次reduce。
4. reduce函数使用这些值对每个单词出现的次数进行计数,并将结果以键值对的形式输出。
5. Hadoop将最终的输出结果写到输出目录中。
更多参考
作为一个可选步骤,可以将input目录复制到你为示例程序创建的基于IDE的项目(Eclipse项目)的顶层。现在可以以input output作为参数直接从IDE运行WordCount类。这将像以前运行普通程序一样运行示例。这种从IDE中运行MapReduce作业的方式,是非常有用的调试MapReduce作业的方式。