我们在进行大数据开发过程中,会遇到各种问题,本文将定期收集整理一些在使用阿里云数加 大数据开发套件 时遇到的常见问题,供大家参考~
Q. 如果之前提交的任务修改后再次提交,是否会影响当天的任务调度?
A. 根据修改的内容来确定是否会影响:如果修改的只是 sql 语句,则不会影
响;如果修改自定义参数和调度配置以后重新提交的,都会影响当天的任
务调度 。
Q. 创建一个新的工作流任务,如果保存后没有提交任务,是否可以进行测试?
A. 仅保存后没有提交,sql 任务可以在本地运行,但不可以提交测试 。
Q. 项目管理下项目配置中的启动调度周期是什么意思?如图所示:
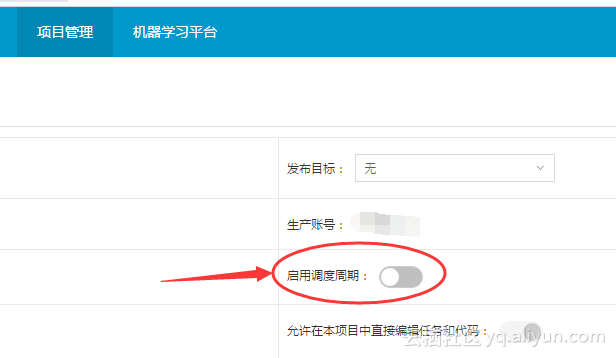
A. 若不启用调度周期,则 周期调度不可用, 也就不会生成新的调度实例 。
Q. 图片中的任务状态实际是暂停的,为什么统计的是失败?
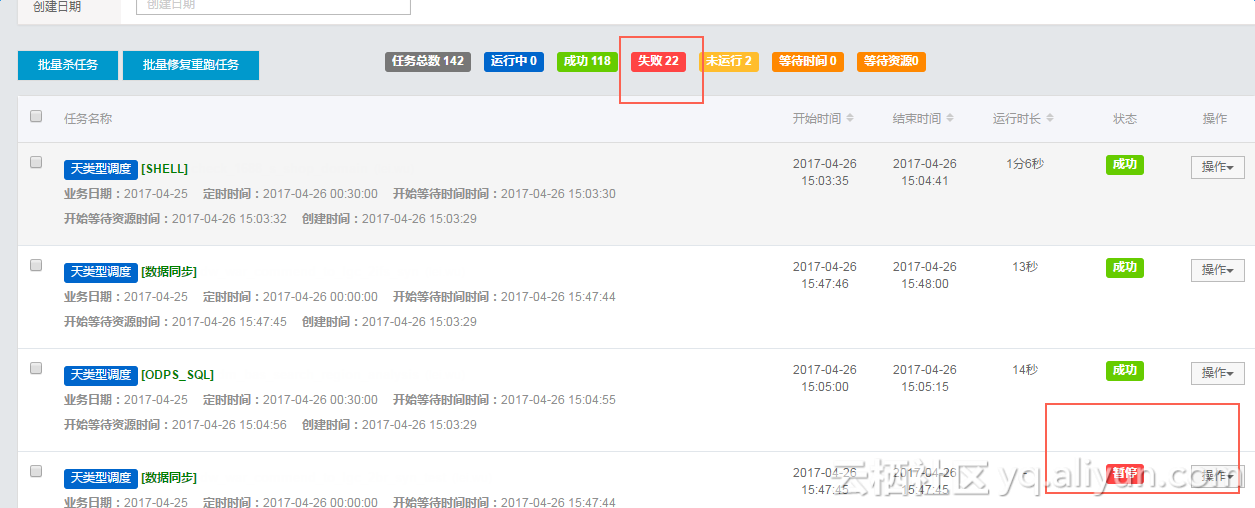
A. 大数据开发套件中的暂停状态,就是失败,所以会放在失败里统计。此处建议如果用于紧急处理任务,减少对下游数据的影响,可以将其置为暂停状态;如果是不再使用的任务,建议删除 。
Q. 在大数据开发套件—运维中心中查看任务,显示全部失败?
A. 因为任务中配置了上游依赖,上游任务跑失败了,导致下游任务无法继续。
Q. 在大数据开发套件中进行补数据任务时,是否需要设置并发?
A. 补数据时不需要设置并发。
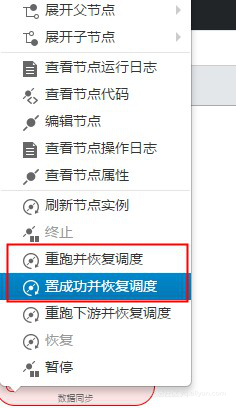
Q. 工作流任务设置为周期性调度,并且是自依赖的,有时上个周期的任务失败会导致下游任务都不能执行了。请问怎样手动启动下游任务?
A. 进入 运维中心-任务运维 页面,找到失败的任务,右击任务名称,需要重跑的任务就重跑,不需要重跑就直接选择置成功,并恢复调度,如下图所示:
Q. 若未成功的上游任务有很多,一个一个进行手动置成功比较麻烦,请问是否有办法先切断依赖,然后从某个时间点再运行吗?
A. 可以重新对某个时间短的数据进行补数据。
Q. 补某个时间段的数据没有问题,但是原来的任务由于上游出错,所有下游任务都不能运行了,应该怎么处理 ?
A. 需要先将这个任务暂停,提交,然后明天取消已暂停的任务,重新提交,后天就可以正常了。此处需要过一天后才能正常运行,未正常运行的,暂时通过补数据来完成。