
如今一谈到大数据,人们就会联想到数百TB以上且规模不断增长的Hadoop集群系统,人们为过去两年我们制造了超过人类历史总和的数据量而感到颤抖,但实际上大数据可以很小,甚至在智能手机和笔记本上就能进行分析处理,而聪明的机器学习算法能将大型强子对撞机数据分析工作量减少上万倍;后大数据时代,人们将更加关心如何让大数据“大事化小”。
但在粒度更小,数据规模却更大的智能传感器时代,在一场官方色彩越来越浓的“去IOE运动”中,如何利用本土低成本技术资源,在Hadoop之外寻找一条新的开源大数据处理技术方案?如何在大力开展“智慧城市”等物联网大数据项目的同时防止对个人隐私的侵犯?
在计算机科学中, 一个简单的真理可以预言一部分未来: "正在CERN(欧洲粒子物理研究所)上演的将很快发生在世界上每个地方。" 我们还可以再加上第二个预言: "一切正在聚集的将最终以分散结尾。" 这与大数据应用有何关系?
大数据通常都很小
许多所谓的 "大数据" 问题其实并不是那么大。一个中央银行五年的交易数据量大概有100GB 大小。所以,中央银行一年的交易数据是完全能够被存储在一部智能手机中的。 一所保险公司关于一个国家的所有交易数据量不会超过4TB。 一个硬盘就可以储存这些保险数据。
那些由企业巨额投资的被标记为时尚 "大数据"用来解决数据分析问题的基础结构,实际上完全可以通过一台笔记本 —— 甚至是一部智能手机 —— 和开源软件来替代。研究者们和全球金融机构都用像 Scikit-Learn[1], Pandas[2]或NLTK[3] 这样的开源软件来处理交易数据和客户关系数据。如MariaDB[4]这样传统的数据库现如今能够处理差不多每秒1百万的录入。MariaDB 10.0[5] 甚至还有来自淘宝的开发人员开发的一些可以被延伸的复制技术。
我建议在进行昂贵的投资前:先购买一个小型的含至少32 GB记忆卡的GNU/Linux 服务器, 一个大容量的SSD 盘(例如 1 TB)并学习 Scikit-Learn 机器学习工具包10230。在大多数情况下,这些已经足够解决您的问题。 如果还不够,您还可以设计一个稍后能够延伸成一个大型基础架构的模型。Scikit-Learn 被许多谷歌工程师用作 "大数据" 问题建模解决方案的工具包。
最小的微粒生产出最大的数据
极端的挑战由核物理及小微粒研究提出来,不断引导了新信息技术的创造。 HTML 是由在欧洲核子研究组织 – 也被称为CERN 的Tim Berners Lee于1991 为解决大规模文档管理的问题而创造。CERN的大型强子对撞机 (the Large Hadron Collider,简称LHC)被设计用作处理每秒1 PB 的数据。它在2013年提供了第一个证明 希格斯玻色子 [6]存在的证据, 这是一个在过去的50年里都没有被解决的问题。
让我们来理解一下每秒1 PB 的数据意味着什么。 1 PB和1,000 TB, 1,000,000 GB 或者是13.3年的HD视频容量一样大。 能够每秒处理1 PB的数据相当于能够处理419,428,800个(13.336524*3600)HD摄像设备生成的数据。这比中国的闭录电视摄像机[7]多15倍, 比英国的多100倍[8].
总的说来,在CERN里为小粒子创造的技术可以被应用到实时收集和处理地球上每个人制造的以声音,视频,健康监测,智能材料日志等形式存在的数据。
智能传感器介绍
大数据结构成功的关键概念是它可以迅速丢弃收集的大部分数据并最终只 储存其中的一小部分[9]。 这是通过将大多数数据处理转移到所谓的 "人工智能"的智能传感器上来实现,在现实的高级统计学中也被叫做机器学习。
大型强子对撞机的传感器之一 ,叫做 紧凑μ子线圈 (CMS)[10] – 每秒中能够收集3太字节代表小型粒子碰撞的图像数据。然后它会自动丢弃被认为是无关的图像并"只" 发送每秒100 Mb到LHC存储结构中,这比它收集的原始数据要少30,000倍。传感器本身使用了FPGA, 一种能够比一般处理器更快处理数据的可编程硬件, 来实施叫做 "clustering"[11]的机器学习运算法则。
如果我们希望将大型强子对撞机的想法应用到闭录电视监控, 我们可以在每个摄像机中存储几个小时的视频并使用一个FPGA 或者一个GPU直接在摄影机中实时处理视频数据。我们可以使用可改编程序的人工智能来侦查人群的数量,性别,尺寸, 行为(和平的, 暴力的, 偷偷摸摸的,迷路的,工作的等等),一个物品的存在(例如:一个手提箱)或一个物品的缺少(例如: 一个路灯)。 只有这些元数据才可以通过网络被发送到一个中央处理设备。 如果有需要的话,这个设备可以决定下载相关的图片或着视频片段。 以防出现一个地区的闭录电视被犯罪人员破坏而无法进行连接的情况,然后发送一个 consumer drone 遥控飞行器[12] 去检查问题的源头。
总的来说, LHC告诉我们如何通过少量的投资或者是广泛的覆盖面来快速建立一个有效的摄像监控系统。 这个系统能够被 – 在世界上的任何地方- 部署到现存的窄频带通信网络 – 包括GSM。它同样也比集中存储和处理所有信息的系统更加有弹性。并且它在电力中断的时候也可以离线工作。
智能隐私,智慧市场
"With the tapping program code-named PRISM, the U.S. government has infringed on the privacy rights of people both at home and abroad" 由新华网在2014年2月28日发表,它解释了美国人权的现状[13]. 类似的项目在许多国家都实施了严格的隐私法律[27]. 65%的市场份额都贡献给了监控和背后强大的经济力量。如果不加以规范管理, 大数据是最容易侵犯隐私权的技术之一。
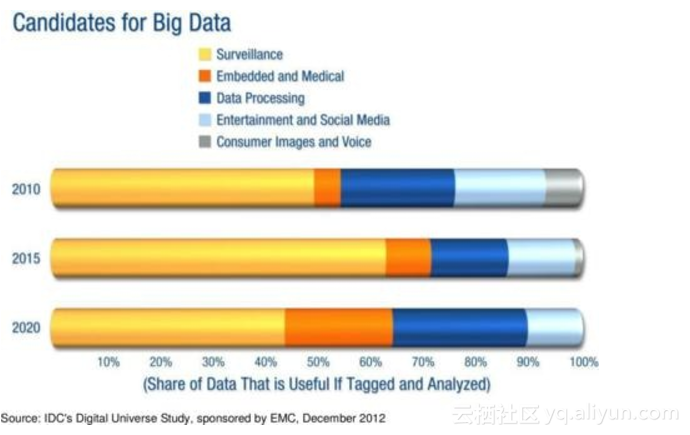
大数据的候选市场[14]
智能传感器提供了一个可能的解决方案, 只要编码能够由独立的负责隐私的权利机关审核。通过在传感器中丢弃,加密并匿名化大多数的数据, 并在产出地加强执行隐私律法,滥用监控系统的风险可以通过缺少原始数据的传输和缺少集中的存储来降低。传感器访问记录可以作为开源数据发布出来以确保审核 的完成。
升级闭录电视到智能摄像机仅在中国就代表了每年2千亿元人民币的市场。 一个国有的升级项目可以作为在智能摄像机内建立"智慧城市" 核心功能的契机:公共网络的访问, 网页加速,微云,移动存储卸载, 地理定位, 多重访问mesh网络,无障碍收费系统等等。 这些只是许多可以进行开发应用的一小部分,并且日后还可以在全球范围内推广,因为 中国是最大的闭录电视系统的生产方并且已经和许多外国国防工业有紧密的合作关系[15]。
物联网代表了更大的数据
到2020年,监控系统将不再是大数据的首要市场了。 根据Gartner分析,260亿个对象将会被连接到互联网[16], 超出全球范围的闭录电视摄像机数量的100倍。连接的对象包含工厂,车,电子消费品,工业传感器,风力发电机,交通灯等使用的工业用传感器。
通过故障预测进行预防性维护 —— 一个机器学习和大数据的直接应用,以及其它的智慧功能都将会被内嵌入对象中。低价系统芯片(SOC)里的GPU 将被用于实施低成本高速度的机器学习[17]。
中国工业已经具有了一个连接物联网及大数据的优势。 最近ARM, 展讯(Spreadtrum), 全志科技(Allwinner), 瑞芯微电子(Rockchip),华为以及其他公司的结盟[18]强 调了中国设计的以ARM为基础解决方案逐渐增长的重要性。我们可以想象, 在几年的时间内,一个有GPU, 网络及Linux操作系统的系统芯片价值将不超过1美元。用这个价钱,它将可以成为用来为智能设备实施机器学习运算法则的标准组件。更高端一点来说, 一个大数据集群可以被设计成一个多核ARM 系统的系统芯片(SOC)以及固态硬盘(SSD)。首次,所有的组件都可以来自中国并且用比因特尔更低的成本提供相同质量的性能。

中国移动计算联盟(MCA) 于2014年4月在深圳正式成立(Credit. Bob Peng, ARM) [18]
现在所缺乏的是通过使用高效的分布式运算法则来处理数据的软件。考虑到最近在中国讨论的"No ICE Policy [21]" 以及HADOOP对Java强烈的依赖性(一个现在被Oracle控制的产品)。这正是考虑为大数据使用另一种软件解决方案的最佳时机。近期,许多社区都开始在 Python的Numpy 开源技术上整合他们的数据处理能力[20, 21] 另外一些则是在创建新的语言例如Julia [22]。需要解决的大挑战之一是 "out-of-core" 数据处理,即超越可用存储器的极限来处理数据。像Wendelin [23] 和Blaze [24] 这样的项目已经都在进行中用来提供开源的解决方案。
总的来说,我们的猜测是"No ICE"的解决方法将会在中国的这些大数据项目中里被创造出来 – 例如 贵州[25]或着新疆 [26] – 由数以亿计的人民币预算作为强大的后盾,向纯粹的科技创新敞开大门, 使其能够处理由智能传感器产生的艾字节或是zetabytes数据。
鸣谢
我要感谢来自Kolibree [28]的Thomas Serval , 来自Items [29]的Maurice Ronai , 来自Cityzen Data [32]的Hervé Rannou 和 Mathias Herberts, 以及来自Scikit-Learn [1]的Alexandre Gramfort分享他们关于大数据的想法。