定时任务是常见需求。普遍的做法是,选择一台或几台机器,通过crontab实现定时任务。但是对于大规模或大量的定时任务,这种做法的缺点非常多,比如:
- 可靠性低,一台机器宕机,该机器上的定时任务就无法执行了
- 没有调度功能,机器之间的负载可能不均衡
- 没有重试机制,任务可能运行失败
- 无法运行大规模分布式任务
阿里云容器服务在离线任务的基础上,增加了定时任务的功能,通过简单的描述,解决了上述问题。关于离线任务的细节,请参考在阿里云容器服务中运行离线作业。
只有10月25号之后升级了agent版本或新创建的集群才能使用该功能。
基于docker compose的定时任务描述
跟离线任务一样,定时任务也是基于docker compose的,只需要在应用模板里添加aliyun.schedule标签,如下面例子所示。
version: "2"
labels:
aliyun.project_type: "batch"
aliyun.schedule: "0-59/30 *"
services:
s1:
image: registry.aliyuncs.com/jimmycmh/busybox:latest
labels:
aliyun.scale: "5"
aliyun.retry_count: "3"
aliyun.remove_containers: "remove-all"
command: date
其中aliyun.schedule: "0-59/30 *"表示每30秒执行一次该任务;schedule的格式跟crontab完全相同(但要注意格式是秒 分 时 天 月 星期,比linux上的crontab多了秒这一项),使用的时间为北京时间。
因为定时任务只能是离线任务,只要添加了aliyun.schedule标签,会自动添加aliyun.project_type: "batch"标签,因此上述例子中aliyun.project_type: "batch"也可以省略。
另外,离线任务中所有的功能,在定时任务中依然可用。比如scale、retry_count、remove_containers等,具体含义请参考离线任务的文档。
执行过程
定时任务被创建后,应用处于“等待”状态。当任务指定的时间到达时,任务会被启动运行,其后的状态变化跟离线应用相同;下一个执行时间到达时,应用状态会重复这一过程。
同一个定时任务同一时刻只会有一个实例在执行,如果任务的执行时间大于其执行周期(比如上述任务的执行时间大于30秒),则下一次执行会进入执行队列;如果执行队列长度大于3,则会丢弃该次执行。
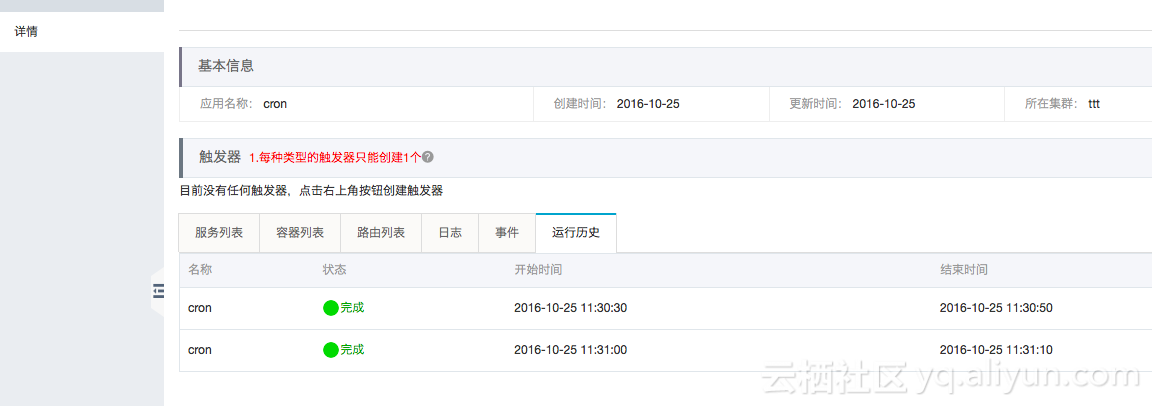
可以在应用详情中查看运行历史及结果,如下图所示;只保留最后10次的运行历史。
高可用性
定时任务控制器采用主-从备模式。主控制器故障时,控制功能将切换至备用控制器。
如果任务的执行时刻正好在主从切换期间,则会延迟至切换完成后执行;如果主从切换期间同一个任务有多次执行,切换完成后只会执行一次。
一般情况下,主从切换时间是秒级,但是为了保证不丢失,请不要设置重复周期小于1分钟的定时任务。