1.8 在分布式集群环境中设置Hadoop
Hadoop MapReduce实战手册
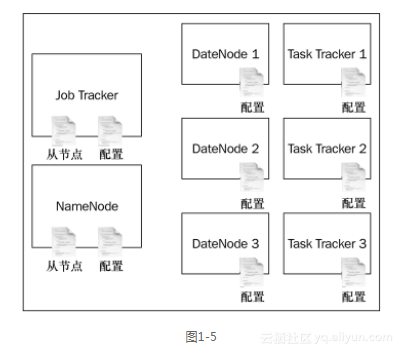
Hadoop的部署包括一套HDFS、一个JobTracker和多个TaskTracker。在1.5节中,我们讨论了HDFS的部署。为了设置Hadoop,我们需要配置JobTracker和TaskTracker,然后在HADOOP_
HOME/conf/slaves文件中指定TaskTracker列表。当我们启动JobTracker时,它会启动相应的TaskTracker节点列表。图1-5描述了一套完整的Hadoop部署。
准备工作
无论使用的是单台机器还是多台机器,本节都适用。如果你用的是多台机器,则应该选择一台机器作为主节点,用于运行HDFS NameNode和JobTracker进程。如果你使用的是单台机器,则可以用它既作主节点,又作从节点。
- 在所有用于安装Hadoop集群的机器上安装Java。
- 如果你使用的是Windows机器,则需要先在每一台机器上都安装Cygwin和SSH服务。链接http://pigtail.net/LRP/printsrv/cygwin-sshd.html提供了详细的说明。
操作步骤
让我们通过设置JobTracker和TaskTracker来设置Hadoop。
- 在每一台机器上,创建一个目录,用于存放Hadoop数据。我们把这个目录称作HADOOP_
DATA_DIR。然后创建三个子目录,HADOOP_DATA_DIR/data、HADOOP_DATA_DIR/local和
HADOOP_DATA_DIR/name。 - 在所有机器上设置SSH密钥,这样我们就可以从主节点登录到所有的节点。1.5节详细介绍了SSH设置。
- 使用>tar zxvf hadoop-1.x.x.tar.gz命令把Hadoop发行包解压缩到所有机器的相同位置。你可以使用任何Hadoop的1.0分支发行包。
- 在所有机器上,编辑HADOOP_HOME/conf/hadoop-env.sh,删除文件中JAVA_HOME行的注释,并将其指向你的本地Java安装目录。例如,如果Java安装在/opt/jdk1.6下,那么就要将JAVA_HOME行改为export JAVA_HOME=/opt/jdk1.6。
- 将主节点(运行JobTracker和NameNode的机器)的IP地址作为一行放置在HADOOP_HOME/conf/
master中。如果你正在进行单节点部署,则保留当前值,填写为localhost。
209.126.198.72
- 然后将所有从节点的IP地址写入HADOOP_HOME/conf/slaves文件,每行一个独立的IP地址。
209.126.198.72
209.126.198.71
- 在每个节点的HADOOP_HOME/conf目录里面,将以下内容添加到core-site.xml、hdfs-
site.xml和mapred-site.xml中。在添加这些配置之前,要先将MASTER_NODE字符串替换为主节点的IP地址,HADOOP_DATA_DIR替换为第一步创建的目录。
将NameNode的URL添加到HADOOP_HOME/conf/core-site.xml中。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://MASTER_NODE:9000/</value>
</property>
</configuration>
在HADOOP_HOME/conf/hdfs-site.xml内添加元数据(名称空间)和本地数据存储的位置1:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>HADOOP_DATA_DIR/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>HADOOP_DATA_DIR/data</value>
</property>
</configuration>
MapReduce本地目录是Hadoop用来存储所用临时文件的位置。在HADOOP_HOME/conf/mapred-site.xml中添加JobTracker的位置。Hadoop将用这个地址来管理作业。最后一个属性设置每个节点最大的map任务数,该值通常与(CPU)核数相同。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>MASTER_NODE:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>HADOOP_DATA_DIR/local</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>8</value>
</property>
</configuration>
- 要格式化新的HDFS文件系统,需要在Hadoop的NameNode(主节点)上运行以下命令。如果在前一节中已经完成了HDFS安装,可以跳过这一步。
>bin/hadoopnamenode –format
...
/Users/srinath/playground/hadoop-book/hadoop-temp/dfs/name has
been successfully formatted.
12/04/09 08:44:51 INFO namenode.NameNode: SHUTDOWN_MSG:
/**
SHUTDOWN_MSG: Shutting down NameNode at Srinath-s-MacBook-Pro.
local/172.16.91.1
**/
- 在主节点上,将工作目录跳转到HADOOP_HOME,并运行以下命令:
>bin/start-dfs.sh
startingnamenode, logging to /root/hadoop-setup-srinath/
hadoop-1.0.0/libexec/../logs/hadoop-root-namenode-node7.beta.out
209.126.198.72: starting datanode, logging to /root/hadoop-setupsrinath/
hadoop-1.0.0/libexec/../logs/hadoop-root-datanode-node7.beta.out
209.126.198.71: starting datanode, logging to /root/hadoop-setupsrinath/
hadoop-1.0.0/libexec/../logs/hadoop-root-datanode-node6.beta.out
209.126.198.72: starting secondarynamenode, logging to /root/hadoop-
setup-srinath/hadoop-1.0.0/libexec/../logs/hadoop-root-secondarynamenode-node7.beta.out
>bin/start-mapred.sh
startingjobtracker, logging to /root/hadoop-setup-srinath/hadoop-1.0.0/
libexec/../logs/hadoop-root-jobtracker-node7.beta.out
209.126.198.72: starting tasktracker, logging to /root/hadoop-setup-
srinath/hadoop-1.0.0/libexec/../logs/hadoop-roottasktracker-node7.beta.out
209.126.198.71: starting tasktracker, logging to /root/hadoop-setup-srinath/
hadoop-1.0.0/libexec/../logs/hadoop-roottasktracker-node6.beta.out
- 在主节点和从节点上,通过ps | grep java命令(如果你使用的是Linux)或通过任务管理器(如果你使用的是Windows)验证部署后的进程列表是否已经正常启动。主节点会列出四个进程—NameNode、DataNode、JobTracker和TaskTracker,从节点有DataNode和TaskTracker。
- 浏览NameNode和JobTracker的Web监控页面。
NameNode:http://MASTER_NODE:50070/。 JobTracker:http://MASTER_NODE:50030/。 - 你可以在${HADOOP_HOME}/logs下找到日志文件。
- 通过使用HDFS命令行列出文件的方式,确认HDFS安装正确。
bin/hadoopdfs -ls /
Found 2 items
drwxr-xr-x - srinathsupergroup 0 2012-04-09 08:47 /Users
drwxr-xr-x - srinathsupergroup 0 2012-04-09 08:47 /tmp
工作原理
正如本章简介中所描述的,Hadoop的安装包括HDFS节点、JobTracker节点和工作节点。当我们启动NameNode时,它通过HADOOP_HOME/slaves文件查找DataNode配置,并在启动时通过SSH在远程服务器上启动DataNode。同样,当我们启动JobTracker时,它通过HADOOP_HOME/slaves文件找到TaskTracker配置,进而启动TaskTracker。
更多参考在下一节中,我们将讨论如何使用分布式环境执行前面提及的WordCount程序。之后的几节将讨论如何使用MapReduce的监控UI监控分布式Hadoop的安装。