数据过滤器使用法则
相信很多企业版用户已经发现编辑器出现了一个新功能「数据过滤器」,然而打开这个功能之后,又不知道怎么用。今天我们就来简单入门一下这个新功能。

能干什么
「数据过滤器」可以算是「字段映射」的升级版。一定有很多人已经用了「字段映射」这个功能用来满足不同组件之间的数据源复用。
映射前:
[
{
"sk": 1
}
]
映射后:
[
{
"sk": 1,
"value": 1
}
]
那么问题来了,如果是下面这种数据格式,我该如何接入到组件上呢?
{
"data": {
"sk": 1
}
}
这种情况下,就轮到「数据过滤器」出手了。
怎么用
首先过滤器使用的语法是 javascript,一种非常简单易上手的语言,可以参考 http://www.w3school.com.cn/js/pro_js_syntax.asp 学习。如果实在学不会,请求教公司里的前端哥哥、前端弟弟、前端姐姐、前端妹妹们。
回到「数据过滤器」的功能上。假设你已经学会了javascript语言,我们的每个过滤器是一个 function,接口定义如下,框架只传入一个变量 data,过滤器需要返回经过处理后的 data:
function (data) {
// do something...
return data;
}
你只需要书写函数体即可,比如我现在要把上一段的问题解决,我只需将 data 的数据格式由 Object 转换为 Array ,并且将 sk 字段的数值放到 value 字段上即可:
data.data.value = data.data.sk;
return [data.data];
或者
return [{
"value": data.data.sk
}]
上面这两种写法,均可以达到同样的效果。
注意点:(敲黑板)
「数据过滤器」中限制了全局变量的访问,目前仅支持 Date, String, Array, Math, Object, RegExp, Boolean, parseInt, parseFloat, JSON。
叠加使用
当我们将过滤器的场景标准化之后,就可以建立多个通用的过滤器,通过多个叠加方式,变成数据该有的样子。
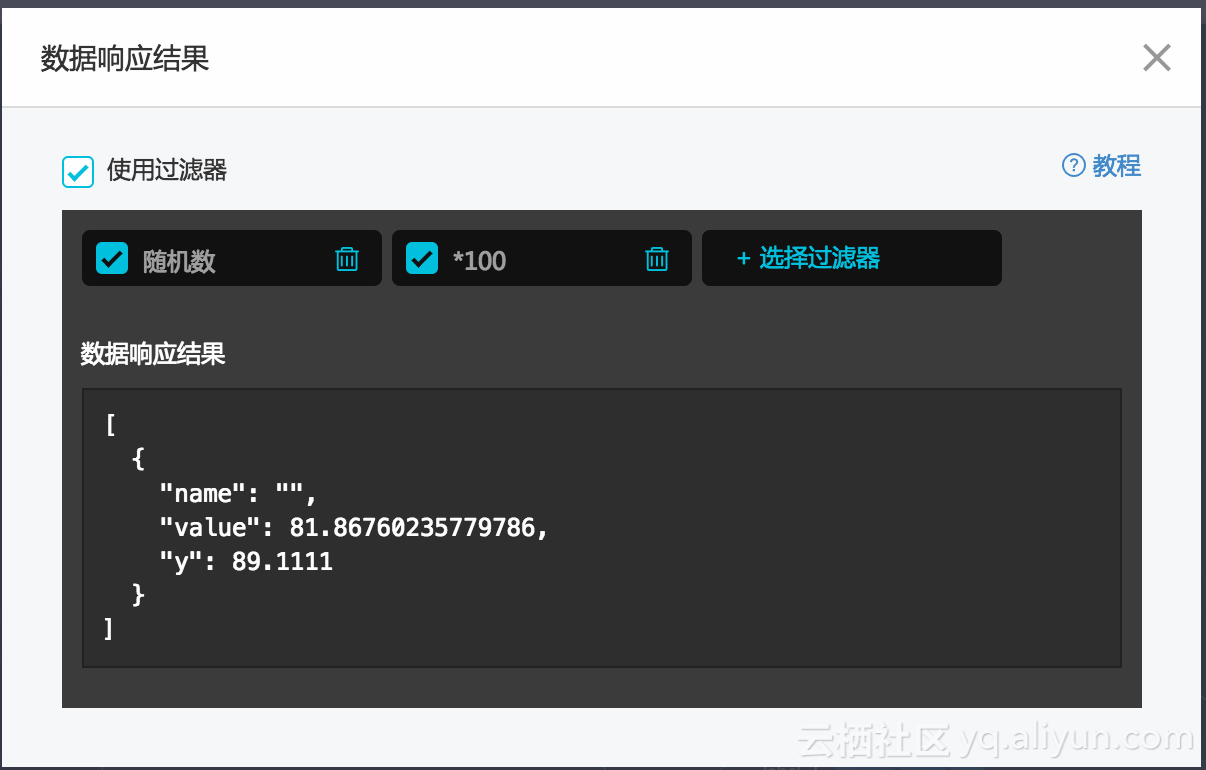
比如我要实现一个随机数效果,并且所有数据放大100倍。
原始数据为
[
{
"name": "",
"value": 232425,
"y": 0.891111
}
]
我先新建一个名称为随机数的过滤器
data[0].value = Math.random(0, 1);
return data;
再新建一个名称为*100的过滤器:
data.forEach(function (val,index) {
val.y = val.y * 100;
val.value = val.value * 100;
});
return data;
添加完成之后的效果如下图:
注意点:(敲黑板)
多个过滤器叠加时,数据流动方向为从左到右,即先经过随机数处理之后的数据再传到*100进行处理。
数据过滤器的功能就先介绍到这里了,下期再见