在 iOS 开发中,NSArray 是一个很重要的数据结构。尤其 TableView 中的数据缓存与更新, NSArray 来缓存数据以及对于显示数据的修改操作。而在 Core Foundation 中 CFArray 与 NSArray 相互对应,这引起了笔者对 Core Foundation 和 Foundation 库中的原生数据结构实现产生兴趣,所以来研究一下。
CFArray 历史渊源
NSArray 和 CFArray 是 Toll-Free Bridged 的,在 opensource.apple.com 中, CFArray 是开源的。这更有助于我们的学习与研究。在 Garan no Dou 大神之前在做个人工具库的时候,曾经研究过 CFArray 的历史渊源和实现手段,在阅读此文之前可以参考一下前辈的优秀博文。
Array 这篇 2005 年的早期文献中,最早介绍过 CFArray ,并且测试过其性能水平。它将 CFArray 和 STL 中的 Vector 容器进行了性能对比,由于后者的实现我们可以理解成是对 C 中的数组封装,所以在性能图上大多数操作都是线性的。而在 CFArray 的图中,会发现很多不一样的地方。
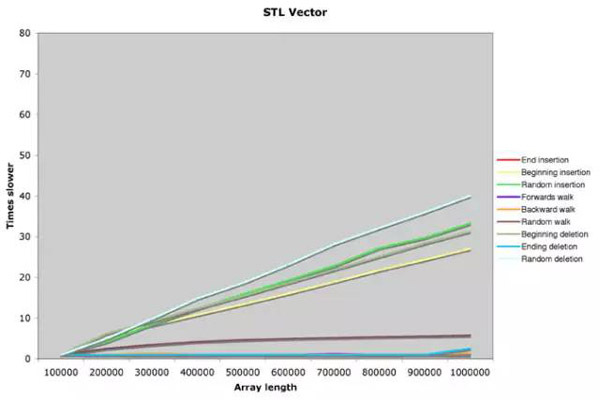
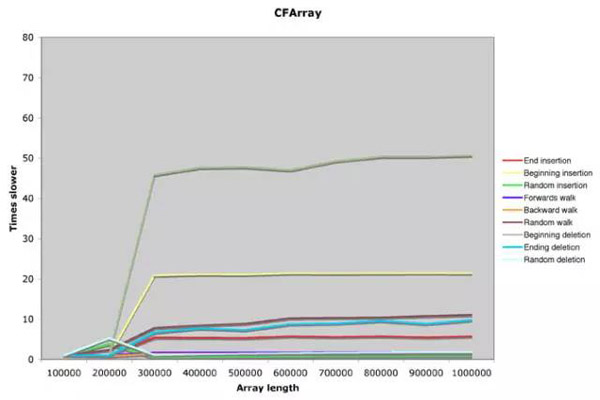
上图分析可以看出, CFArray 在头插、尾插插入时候的效率近乎常数,而对于中间元素的操作会从小数据的线性效率在一个阀值上突然转变成线性效率,而这个跃变灰不由得想起在 Java 8 当中的 HashMap 的数据结构转变方式。
在 ObjC 的初期,CFArray 是使用 deque 双端队列 实现,所以会呈现出头尾操作高效,而中间操作成线性的特点。在容量超过 300000 左右时(实际应该是 262140 = 2^18 ),时间复杂度发生陡变。在源代码中,阀值被宏定义为 __CF_MAX_BUCKETS_PER_DEQUE ,具体代码可以见 CF-550-CFArray.c (2011 年版本):
- if (__CF_MAX_BUCKETS_PER_DEQUE futureCnt) {
- // 创建 CFStorage 引用
- CFStorageRef store
- // 转换 CFArray 为 Storage
- __CFArrayConvertDequeToStore(array);
- store = (CFStorageRef)array->_store;
- }
可以看到,当数据超出阀值 __CF_MAX_BUCKETS_PER_DEQUE 的时候,会将数据结构从 CFArray 转换成 CFStorage 。 CFStorage 是一个平衡二叉树的结构,为了维护数组的顺序访问,将 Node 的权值使用下标完成插入和旋转操作。具体的体现可以看 CFStorageInsertValues 操作。具体代码可以查看 CF-368.18-CFStorage.c 。
在 2011 年以后的 CF-635.15-CFArray.c 版本中, CFArray 取消了数据结构转换这一功能。或许是为了防止大数据时候二叉树建树的时间抖动问题从而取消了这一特性。直接来看下数据结构的描述:
- struct __CFArrayDeque {
- uintptr_t _leftIdx; // 自左开始下标位置
- uintptr_t _capacity; // 当前容量
- };
- struct __CFArray {
- CFRuntimeBase _base;
- CFIndex _count; // 元素个数
- CFIndex _mutations; // 元素抖动量
- int32_t _mutInProgress;
- __strong void *_store;
- };
从命名上可以看出 CFArray 由单一的双端队列进行实现,而且记录了一些容器信息。
C 数组的一些问题
C 语言中的数组,会开辟一段连续的内存空间来进行数据的读写、存储操作。另外说一句,数组和指针并不相同。有一种被很多教材书籍上滥用的说法:一块被 malloc 过的内存空间等于一个数组。这是错误的。最简单的解释,指针需要申请一个指针区域来存储(指向)一块空间的起始位置,而数组(的头部)是对一块空间起始位置的直接访问。另外想了解更多可以看 Are pointers and arrays equivalent in C? 这篇博文。
C 中的数组最显著的缺点就是,在下标 0 处插入时,需要移动所有的元素(即 memmove() 函数的原理)。类似的,当删除第一个元素、在第一个元素前插入一个元素也会造成 O(n)复杂度的操作 。然而数组是常读写的容器,所以 O(n) 的操作会造成很严重的时间开销。
当前版本中 CFArray 的部分实现细节
在 CF-855.17 中,我们可以看到当前版本的 CFArray 的实现。文档中对 CFArray 有如下的描述:
CFArray 实现了一个可被指针顺序访问的紧凑容器。其值可通过整数键(索引下标)进行访问,范围从 0 至 N-1,其中 N 是数组中值的数量。称其紧凑 (compact) 的原因是该容器进行删除或插入某个值的时候,不会再内存空间中留下间隙,访问顺序仍旧按照原有键值数值大小排列,使得有效检索集合范围总是在整数范围 [0, N-1] 之中。因此,特定值的下标可能会随着其他元素插入至数组或被删除时而改变。
数组有两种类型:不可变(immutable) 类型在创建数组之后,不能向其添加或删除元素,而 可变(mutable) 类型可以添加或从中删除元素。可变数组的元素数量无限制(或者称只受 CFArray 外部的约束限制,例如可用内存空间大小)。与所有的 CoreFoundation 集合类型同理,数组将保持与元素对象的强引用关系。
为了进一步弄清 CFArray 的细节,我们来分析一下 CFArray 的几个操作方法:
- // 通过下标查询元素值
- const void *CFArrayGetValueAtIndex(CFArrayRef array, CFIndex idx) {
- // 这个函数尚未开源
- // 通过给定的 CFTypeID 来验证指定元素是否匹配 Core Foundation 桥接类
- CF_OBJC_FUNCDISPATCHV(__kCFArrayTypeID, const void *, (NSArray *)array, objectAtIndex:idx);
- // 尚未开源
- // 通过给定的 CFTypeID 来验证 Core Foundation 类型合法性
- __CFGenericValidateType(array, __kCFArrayTypeID);
- CFAssert2(0 idx && idx __CFArrayGetCount(array), __kCFLogAssertion, "%s(): index (%d) out of bounds", __PRETTY_FUNCTION__, idx);
- CHECK_FOR_MUTATION(array);
- // 从内存位置取出元素
- return __CFArrayGetBucketAtIndex(array, idx)->_item;
- }
- // 返回查询元素的地址
- CF_INLINE struct __CFArrayBucket *__CFArrayGetBucketAtIndex(CFArrayRef array, CFIndex idx) {
- switch (__CFArrayGetType(array)) {
- // 只允许两种数组类型
- // 不可变对应普通线性结构,可变对应双端队列
- case __kCFArrayImmutable:
- case __kCFArrayDeque:
- // 取地址再加上索引偏移量,返回元素地址
- return __CFArrayGetBucketsPtr(array) + idx;
- }
- return NULL;
- }
通过索引下标查询操作中,CFArray 仍然继承了传统数组的连续地址空间的性质,所以其时间仍然可保持在 O(1) 复杂度,十分高效。
- void CFArrayInsertValueAtIndex(CFMutableArrayRef array, CFIndex idx, const void *value) {
- // 通过给定的 CFTypeID 来验证指定元素是否匹配 Core Foundation 桥接
- CF_OBJC_FUNCDISPATCHV(__kCFArrayTypeID, void, (NSMutableArray *)array, insertObject:(id)value atIndex:(NSUInteger)idx);
- // 通过给定的 CFTypeID 来验证 Core Foundation 类型合法性
- __CFGenericValidateType(array, __kCFArrayTypeID);
- CFAssert1(__CFArrayGetType(array) != __kCFArrayImmutable, __kCFLogAssertion, "%s(): array is immutable", __PRETTY_FUNCTION__);
- CFAssert2(0 idx && idx __CFArrayGetCount(array), __kCFLogAssertion, "%s(): index (%d) out of bounds", __PRETTY_FUNCTION__, idx);
- // 类型检查
- CHECK_FOR_MUTATION(array);
- // 调用该函数进行具体的数组变动过程
- _CFArrayReplaceValues(array, CFRangeMake(idx, 0), &value, 1);
- }
- // 这个函数没有经过 ObjC 的调度检查,即 CF_OBJC_FUNCDISPATCHV 方法
- // 所以为安全考虑,只能用在已经进行调度检查的函数入口之后
- void _CFArrayReplaceValues(CFMutableArrayRef array, CFRange range, const void **newValues, CFIndex newCount) {
- // 进一步类型检查
- CHECK_FOR_MUTATION(array);
- // 加锁操作,增加自旋锁防止竞争
- BEGIN_MUTATION(array);
- // 声明回调
- const CFArrayCallBacks *cb;
- // 偏移下标,元素总数,数组改变后元素总数
- CFIndex idx, cnt, futureCnt;
- const void **newv, *buffer[256];
- // 获取数组中元素个数
- cnt = __CFArrayGetCount(array);
- // 新数组元素总数 = 原数组元素总数 - 删除的元素个数 + 增加的元素个数
- futureCnt = cnt - range.length + newCount;
- CFAssert1(newCount futureCnt, __kCFLogAssertion, "%s(): internal error 1", __PRETTY_FUNCTION__);
- // 获取数组中定义的回调方法
- cb = __CFArrayGetCallBacks(array);
- // 构造分配释放内存抽象
- CFAllocatorRef allocator = __CFGetAllocator(array);
- // 需要的情况下持有新元素,并为其分配一个临时缓冲区
- // 标准是新元素的个数是否超过256
- if (NULL != cb->retain && !hasBeenFinalized(array)) {
- newv = (newCount 256) ? (const void **)buffer : (const void **)CFAllocatorAllocate(kCFAllocatorSystemDefault, newCount * sizeof(void *), 0);
- if (newv != buffer && __CFOASafe) __CFSetLastAllocationEventName(newv, "CFArray (temp)");
- // 为新元素增加数据缓冲区
- for (idx = 0; idx newCount; idx++) {
- newv[idx] = (void *)INVOKE_CALLBACK2(cb->retain, allocator, (void *)newValues[idx]);
- }
- } else {
- newv = newValues;
- }
- // 数据抖动量自加
- array->_mutations++;
- // 现在将一个数组的存储区域分成了三个部分,每个部分都有可能为空
- // A: 从索引下标零的位置到小于 range.location 的区域
- // B: 传入的 range.location 区域
- // C: 从 range.location + range.length 到数组末尾
- // 需要注意的是,索引0的位置不一定位于可用存储的最低位,当变化位置新值数量与旧值数量不同时,B区域需要先释放再替换,然后A和C中的值根据情况进行位移
- if (0 range.length) {
- // 正常释放变化区域操作
- __CFArrayReleaseValues(array, range, false);
- }
- // B 区现在为清空状态,需要重新填充数据
- if (0) {
- // 此处隐藏了判断条件和代码。
- // 大概操作是排除其他的干扰项,例如 B 区数据未完全释放等。
- } else if (NULL == array->_store) {
- // 通过数据的首地址引用指针来判断 B 区释放
- if (0) {
- // 此处隐藏了判断条件和代码
- // 排除干扰条件,例如 futureCnt 不合法等
- } else if (0 futureCnt) {
- // 声明一个双端队列对象
- struct __CFArrayDeque *deque;
- // 根据元素总数确定环状缓冲区域可载元素总个数
- CFIndex capacity = __CFArrayDequeRoundUpCapacity(futureCnt);
- // 根据元素个数确定空间分配大小
- CFIndex size = sizeof(struct __CFArrayDeque) + capacity * sizeof(struct __CFArrayBucket);
- // 通过缓冲区构造器来构造存储缓存
- deque = (struct __CFArrayDeque *)CFAllocatorAllocate((allocator), size, isStrongMemory(array) ? __kCFAllocatorGCScannedMemory : 0);
- if (__CFOASafe) __CFSetLastAllocationEventName(deque, "CFArray (store-deque)");
- // 确定双端队列左值
- deque->_leftIdx = (capacity - newCount) / 2;
- deque->_capacity = capacity;
- __CFAssignWithWriteBarrier((void **)&array->_store, (void *)deque);
- // 完成 B 区构造,安全释放数组
- if (CF_IS_COLLECTABLE_ALLOCATOR(allocator)) auto_zone_release(objc_collectableZone(), deque);
- }
- } else { // Deque
- // 根据 B 区元素变化,重新定位 A 和 C 区元素存储状态
- if (0) {
- } else if (range.length != newCount) {
- // 传入 array 引用,最终根据变化使得数组更新A、B、C分区规则
- __CFArrayRepositionDequeRegions(array, range, newCount);
- }
- }
- // 将区域B的新变化拷贝到B区域
- if (0 newCount) {
- if (0) {
- } else { // Deque
- // 访问线性存储区
- struct __CFArrayDeque *deque = (struct __CFArrayDeque *)array->_store;
- // 在原基础上,增加一段缓存区域
- struct __CFArrayBucket *raw_buckets = (struct __CFArrayBucket *)((uint8_t *)deque + sizeof(struct __CFArrayDeque));
- // 更改B区域数据,类似与 memcpy,但是有写屏障(write barrier),线程安全
- objc_memmove_collectable(raw_buckets + deque->_leftIdx + range.location, newv, newCount * sizeof(struct __CFArrayBucket));
- }
- }
- // 设置新的元素个数属性
- __CFArraySetCount(array, futureCnt);
- // 释放缓存区域
- if (newv != buffer && newv != newValues) CFAllocatorDeallocate(kCFAllocatorSystemDefault, newv);
- // 解除线程安全保护
- END_MUTATION(array);
- }
在 CFArray 的插入元素操作中,可以很清楚的看出这是一个双端队列(dequeue)的插入元素操作,而且是一种仿照 C++ STL 标准库的存储方式,缓冲区嵌套 map 表的静态实现。用示意图来说明一下数据结构:

在 STL 中的 deque,是使用的 map 表来记录的映射关系,而在 Core Foundation 中,CFArray 在保证这样的二次映射关系的时候很直接地运用了二阶指针 _store。在修改元素的操作中,CFArray 也略显得暴力一些,先对数组进行大块的分区操作,再按照顺序填充数据,组合成为一块新的双端队列,例如在上图中的双端队列中,在下标为 7 的元素之前增加一个值为 100 的元素:
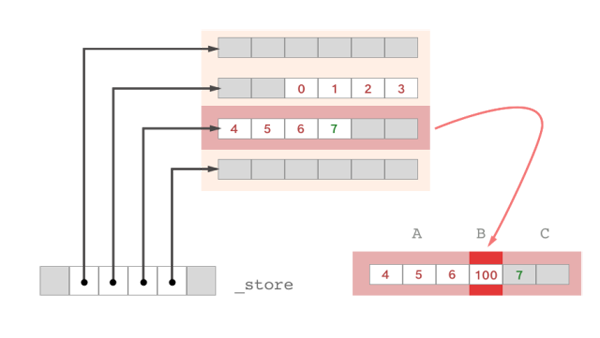
根据索引下标会找到指定部分的缓存区,将其拿出并进行重新构造。构造过程中或将其划分成 A、B、C 三个区域,B 区域是修改部分。当然如果不够的话,系统会自己进行缓存区的扩容,即 CFAllocatorRef 官方提供的内存分配/释放策略。
CFAllocatorRef 是 Core Foundation 中的分配和释放内存的策略。多数情况下,只需要用默认分配器 kCFAllocatorDefault ,等价于传入 NULL 参数,这用会用 Core Foundation 所谓的“常规方法”来分配和释放内存。这种方法可能会有变化,我们不应该以来与任何特殊行为。用到特殊分配器的情况很少,下来是官方文档中给出的标准分配器及其功能。
| KCFALLOCATORDEFAULT | 默认分配器,与传入NULL等价。 |
|---|---|
| kCFAllocatorSystemDefault | 原始的默认系统分配器。这个分配器用来应对万一用CFAllocatorSetDefault改变了默认分配器的情况,很少用到。 |
| kCFAllocatorMalloc | 调用malloc、realloc和free。如果用malloc创建了内存,那这个分配器对于释放CFData和CFString就很有用。 |
| kCFAllocatorMallocZone | 在默认的malloc区域中创建和释放内存。在 Mac 上开启了垃圾收集的话,这个分配器会很有用,但在 iOS 中基本上没什么用。 |
| kCFAllocatorNull | 什么都不做。跟kCFAllocatorMalloc一样,如果不想释放内存,这个分配器对于释放CFData和CFString就很有用。 |
| KCFAllocatorUseContext | 只有CFAllocatorCreate函数用到。创建CFAllocator时,系统需要分配内存。就像其他所有的Create方法,也需要一个分配器。这个特殊的分配器告诉CFAllocatorCreate用传入的函数来分配CFAllocator。 |
在 _CFArrayReplaceValues 方法中的最后一个判断:
- if (newv != buffer && newv != newValues)
- CFAllocatorDeallocate(kCFAllocatorSystemDefault, newv);
会检查一下缓存区的数量问题,如果数量过多会释放掉多余的缓存区。这是因为这个方法具有通用性,不仅仅可以使用在插入元素操作,在增加(CFArrayAppendValue)、替换(CFArrayReplaceValues)、删除(CFArrayRemoveValueAtIndex)操作均可使用。由于将数据结构采取分块管理,所以时间分摊,复杂度大幅度降低。所以,我们看到 CFArray 的时间复杂度在查询、增添元素操作中均有较高的水平。
而在 NSMutableArray 的实现中,苹果为了解决移动端的小内存特点,使用 CFArray 中在两端增加可扩充的缓存区则会造成大量的浪费。在 NSMutableArray原理揭露 一文中使用逆向的思路,挖掘 NSMutableArray 的实现原理,其做法是使用环形缓冲区对缓存部分做到最大化的压缩,这是苹果针对于移动设备的局限而提出的方案。
本文作者:佚名
来源:51CTO