这个研究是我在一门课上的期末作业,旨在用一些广泛流传的《柯南》"规律"(比如毛利小五郎指出的凶手大多是好人)预测凶手和被害人,并定量地探索作者——青山刚昌——在创作角色时的一些"隐藏信念"(hidden belief)。分析漫画的研究我并没有见过,不过还是有不少研究使用数学建模方法识别文学作品的作者 (Madigan, Genkin, Lewis, Argamon, Fradkin, & Ye, 2005; Zhao & Zobel, 2007; Zheng, Li, Chen & Huang, 2006), 或文学风格(比如中国古诗的风格 Yi, He, Li, & Yu, 2004。这些作品大多使用主成分分析、机器学习等方法对文学作品中的词汇、语法、结构和内容进行分析。

本文先介绍朴素贝叶斯模型通过角色特征(性格、行为、与他人关系等)预测其身份(凶手/被害人)的结果,再对一些相关的社会、心理学现象进行讨论。朴素贝叶斯模型建立在已有数据基础上,此处使用长春版漫画单行本1-70卷中共60个事件,以下称"训练数据"。模型先计算出训练数据中角色拥有各种特征(组合)时是凶手或被害人的概率,再以此预测新数据(1-70卷中训练数据之后的共21个事件)中角色的身份。
首先需要收集数据,即1-70卷的事件中的凶手、被害人都有些什么特征。因为我感兴趣的是杀人事件,类似于怪盗基德对决/少年侦探团寻宝这些没有凶杀案发生的事件、自杀事件和凶手一开始就被锁定的事件就被排除了。于是共81个事件被统计,皆有且只有一名凶手和一至两名被害人。涉案角色(除主角、警察等)为3至9不等,平均5人,共404名角色的二十个特征被统计。

这些特征的选择基于个人经验和一些大家熟悉的对剧情或人物的调侃。 比如凶手一开始大多慈眉善目甚至案发后有不在场证明;被害人一般都凶神恶煞让人讨厌,或者在大家说最好待在一起时非要自己待着;还有事后被证明无辜的人中有部分会被毛利大叔错误指认。
这些特征首先被以"0"、"1"编码(表现出某个特征则编码为1,否则为0)。于是每个角色就有了20个代表他们特征的值(由0或1组成),并且也有两个值代表他们是否为凶手或被害人(比如某个人是凶手,那么他的这两个值就是1,0;是被害人就是0,1;都不是就是0,0)。
有了这些值之后就可以通过回归分析看凶手和被害人这两个身份可能被哪些特征预测了,这里我使用了逻辑斯蒂回归(logistic linear regression)。这一步是因为这二十个特征并不一定都有很好的预测能力,预先筛选一下可以让之后的贝叶斯模型更精简。这一步后对"凶手"或"被害人"在.05水平上显著的特征们被留下并进入贝叶斯模型。对凶手有预测能力(包括正相关和负相关)的特征包括"对除主角以外的周围人不友善"、"对周围人友善"、"有不在场证明等有利证据"、"遭遇攻击但未死"、"与死者是恋人或婚姻关系"。
之后我在此基础上又添加了“被害人死后表现出悲伤”、“被小五郎指为凶手”、“有对自己的不利证据”等三个特征。对被害人有预测能力的特征包括"对除主角以外的周围人不友善"、"对主角不友善"、"表现出紧张或惊恐"、"要自己待着",我之后又添加了性别和年龄(50岁以上或以下)连个特征。被害人相关特征在有人被杀前统计,因为对被害人的预测需要在事件发生前做出;相反,凶手相关特征则根据凶手被正确指出前所有角色的表现来统计。
接下来的一步是分别对凶手和被害人建立朴素贝叶斯模型,算出各个可能的特征组合有多大概率对应"凶手"或"被害人"身份。
凶手模型公式如下:
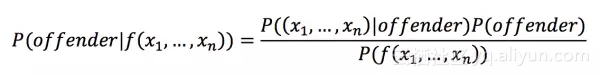
等号左边是我们要求的条件概率,即在一个角色有某些特征时这个角色是凶手的概率。x1,...,xn是各个特征的取值的组合,如"1,0,0,1,1"。P((x1,...,xn)|offender)是所有凶手中出现某个特征组合的概率。P(offender)是个先验概率,对所有角色来说没有区别,因此在实际计算中可忽略。等式右边分母则是某个特征组合在所有角色中出现的概率。
同理,被害人模型公式如下:
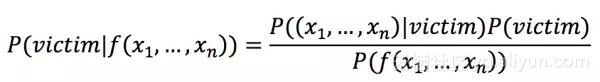
在对全部训练数据中的404个角色进行计算之后,我们就得到了各个特征组合对应的凶手概率和被害人概率。然后就可以把这两个概率应用在新数据(70卷之后的单行本)上了。具体来说,就是先把新数据中每个涉案角色的特征组合统计出来,然后分别计算他们是凶手或被害人的概率。在每个事件中,"凶手"概率最高的人被预测为凶手,"被害人"概率最高的人被预测为被害人。如果出现多于一个概率最高值,则拥有这个值的人都被预测为凶手/被害人。

之后就是计算模型预测准确率并将其与机遇水平(瞎蒙正确率)相比较。那么预测准确率怎么算呢?如果是只预测其中一个人为凶手,那么在每个事件中预测对了就记为100%,错了就记为0;如果预测多于一人(M人,M>1)为凶手,且其中一个正确,则记为(100/M)%,如果没有一个正确则记为0。预测被害人准确率的计算与预测凶手准确率类似,只是被害人有可能多于一个。这种情况下,完全预测正确记为100%,只预测正确其中一人记为50%。预测凶手的机遇水平为(100/A)%,此处A为还活着的人的人数,因为被害人已经被排除了;预测被害人的机遇水平为(100/N)%,N为事件涉案人数。总的来说预测被害人的机遇水平更低一些。
结果如图:
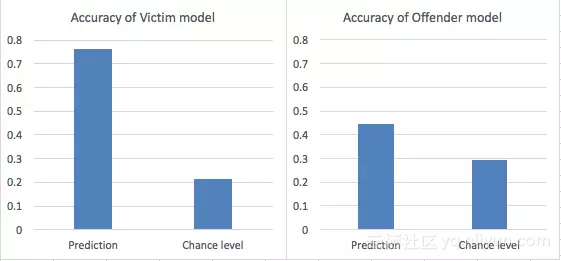
左图为预测被害人的模型准确率与机遇水平,模型讲被害人范围从4.7人(平均值)缩小到1.3人。右图为预测凶手的模型准确率与机遇水平,模型将凶手范围从3.4人缩小到2.2人。
总得来说,通过这些特征预测被害人的准确率高于预测凶手的准确率,这说明青山对被害人的塑造更为脸谱化,而凶手特征则比较多变。从侦探漫画的角度来说也可以理解,毕竟作者不能让读者仅通过一些性格、行为表现就轻易将凶手猜出来。尽管如此,以上模型还是反映出青山在创作凶手角色时的一些隐藏信念,或者说用于"隐藏"凶手的技法,比如凶手在一开始时通常很友好,而不友好或表现出与被害人不和的反而可能是清白的。此外,作者也利用了大家普遍拥有的一个想法——没人会伤害自己——来试图隐藏真凶。若干凶手都在事件过程中伤害自己(虽然没有死)。
更值得注意的是作者塑造被害人时的"脸谱化",它反映了一个在司法领域和社会文化上有很大影响的心理现象——正义世界谬误("just-world" fallacy)。这个概念由Lerner and Simmons 在1966年首次提出。在他们的第一个研究中,被试的任务是观察另一个人(受害者)在学习任务中的表现并对这个人做出评价。被观察的人之所以被称为受害者,是因为其在任务中犯错时会遭受电击。虽然这只是实验的一部分,但至少被试看到被观察者在遭受电击时很疼。
研究者发现,当被试得知并相信被观察者还要在第二轮任务中遭受电击、且自己无力改变被观察者的悲惨命运时,被试对被观察者的评价更低。这反映出人们根深蒂固的"善有善报,恶有恶报"的信念,人们倾向于认为个人得到的结果是由其自身行为造成的,世界是相对正义且公平的,有一种无形且普适的力量在维持世间的平衡 (Hafer & Begue, 2005; Lerner, 1980)。这是因为人们需要证据来相信自己生活在一个正义的世界,从而不会感到时刻受到威胁。 这种信念在很多时候会成为对受害者的二次打击,比如"认为强奸案受害者本身不检点"这种想法在我们的生活中也是不少见。
此外,一味地积极评价受害人也会对犯罪者的审判产生影响。有研究表明,当陪审团相信受害人是一个值得尊敬的人时,他们会多受害人及其家庭产生更多的同情,并倾向于认为犯罪者的罪行更为严重(Greene, Koehring, & Quiat,1998)。直觉上这种情绪会导致犯罪者的量刑更重,事实也的确如此。当被害人被描述得更值得尊重或更有人格魅力时,犯罪者会更可能被判处监禁 (Landy & Aronson, 1969)。
总得来说,人不总是理性的。我们对人、事、物的判断会受到自己固有信念的影响,而我们的决定也会被当前情感所左右。有时候这些"人之常情"并没有大的影响,但有的时候可能会决定另一个人的命运。在会对他人产生影响的时候,理性就显得更为重要。