1.14 并行流
流使得并行处理块操作变得很容易。这个过程几乎是自动的,但是需要遵守一些规则。首先,必须有一个并行流。可以用Collection.parallelStream()方法从任何集合中获取一个并行流:
只要在终结方法执行时,流处于并行模式,那么所有的中间流操作都将被并行化。
当流操作并行运行时,其目标是要让其返回结果与顺序执行时返回的结果相同。重要的是,这些操作可以以任意顺序执行。
下面的示例是一项你无法完成的任务。假设你想要对字符串流中的所有短单词计数:
这是一种非常非常糟糕的代码。传递给forEach的函数会在多个并发线程中运行,每个都会更新共享的数组。正如我们在卷Ⅰ第14章中所解释的,这是一种经典的竞争情况。如果多次运行这个程序,你很可能就会发现每次运行都会产生不同的计数值,而且每个都是
错的。
你的职责是要确保传递给并行流操作的任何函数都可以安全地并行执行,达到这个目的的最佳方式是远离易变状态。在本例中,如果用长度将字符串群组,然后分别对它们进行计数,那么就可以安全地并行化这项计算。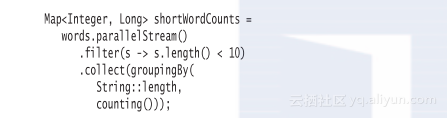
警告:传递给并行流操作的函数不应该被堵塞。并行流使用fork-join池来操作流的各个部分。如果多个流操作被阻塞,那么池可能就无法做任何事情了。
默认情况下,从有序集合(数组和列表)、范围、生成器和迭代产生的流,或者通过调用Stream.sorted产生的流,都是有序的。它们的结果是按照原来元素的顺序累积的,因此是完全可预知的。如果运行相同的操作两次,将会得到完全相同的结果。
排序并不排斥高效的并行处理。例如,当计算stream.map(fun)时,流可以被划分为n的部分,它们会被并行地处理。然后,结果将会按照顺序重新组装起来。
当放弃排序需求时,有些操作可以被更有效地并行化。通过在流上调用unordered方法,就可以明确表示我们对排序不感兴趣。Stream.distinct就是从这种方式中获益的一种操作。在有序的流中,distinct会保留所有相同元素中的第一个,这对并行化是一种阻碍,因为处理每个部分的线程在其之前的所有部分都被处理完之前,并不知道应该丢弃哪些元素。如果可以接受保留唯一元素中任意一个的做法,那么所有部分就可以并行地处理(使用共享的集来跟踪重复元素)。
还可以通过放弃排序要求来提高limit方法的速度。如果只想从流中取出任意n个元素,而并不在意到底要获取哪些,那么可以调用:
正如1.9节所讨论的,合并映射表的代价很高昂。正是因为这个原因,Collectors.groupByConcurrent方法使用了共享的并发映射表。为了从并行化中获益,映射表中值的顺序不会与流中的顺序相同。
警告:不要修改在执行某项流操作后会将元素返回到流中的集合(即使这种修改是线程安全的)。记住,流并不会收集它们的数据,数据总是在单独的集合中。如果修改了这样的集合,那么流操作的结果就是未定义的。JDK文档对这项需求并未做出任何约束,并且对顺序流和并行流都采用了这种处理方式。
更准确地讲,因为中间的流操作都是惰性的,所以直到执行终结操作时才对集合进行修改仍旧是可行的。例如,下面的操作尽管并不推荐,但是仍旧可以工作:

为了让并行流正常工作,需要满足大量的条件:
- 数据应该在内存中。必须等到数据到达是非常低效的。
- 流应该可以被高效地分成若干个子部分。由数组或平衡二叉树支撑的流都可以工作得很好,但是Stream.iterate返回的结果不行。
- 流操作的工作量应该具有较大的规模。如果总工作负载并不是很大,那么搭建并行计算时所付出的代价就没有什么意义。
- 流操作不应该被阻塞。
换句话说,不要将所有的流都转换为并行流。只有在对已经位于内存中的数据执行大量计算操作时,才应该使用并行流。
程序清单1-8中的示例程序展示了如何操作并行流。
程序清单1-8 parallel/ParallelStreams.java




