GPU架构
内容包括:
1.OpenCLspec和多核硬件的对应关系
- AMD GPU架构
- Nvdia GPU架构
- Cell Broadband Engine
2.一些关于OpenCL的特殊主题
- OpenCL编译系统
- Installable client driver
首先我们可能有疑问,既然OpenCL具有平台无关性,我们为什么还要去研究不同厂商的特殊硬件设备呢?
- 了解程序中的循环和数据怎样映射到OpenCL Kernel中,便于我们提高代码质量,获得更高的性能。
- 了解AMD和Nvdia显卡的区别。
- 了解各种硬件的区别,可以帮助我们使用基于这些硬件的一些特殊的OpenCL扩展,这些扩展在后面课程中会讲到。
3、传统的CPU架构

- 对单个线程来说,CPU优化能获得最小时延,而且CPU也适合处理控制流密集的工作,比如if、else或者跳转指令比较多的任务。
- 控制逻辑单元在芯片中占用的面积要比ALU单元多
- 多层次的cache设计被用来隐藏时延(可以很好的利用空间和时间局部性原理)
- 有限的寄存器数量使得同时active的线程不能太多。
- 控制逻辑单元记录程序的执行、提供指令集并行(ILP)以及最小化CPU管线的空置周期(stalls,在该时钟周期,ALU没做什么事)。
4、现代的GPGPU架构
- 对于现代的GPU,通常的它的控制逻辑单元比较简单(和cpu相比),cache也比较小
- 线程切换开销比较小,都是轻量级的线程。
- GPU的每个“核”有大量的ALU以及很小的用户可管理的cache。
- 内存总线都是基于带宽优化的。150GB/s的带宽可以使得大量ALU同时进行内存操作。
5、AMD GPU硬件架构
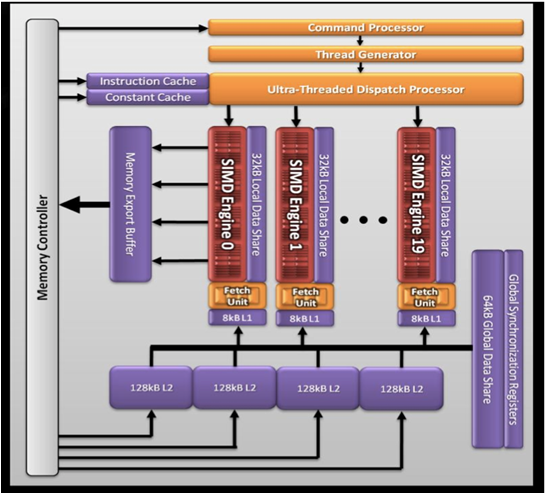
现在我们简单看下AMD 5870显卡(cypress)的架构
- 20个simd引擎,每个simd引擎包含16个simd。
- 每个simd包含16个stream core
- 每个stream core都是5路的乘法-加法运算单元(VLIW processing)。
- 单精度运算可以达到 Teraflops。
- 双精度运算可以达到544Gb/s
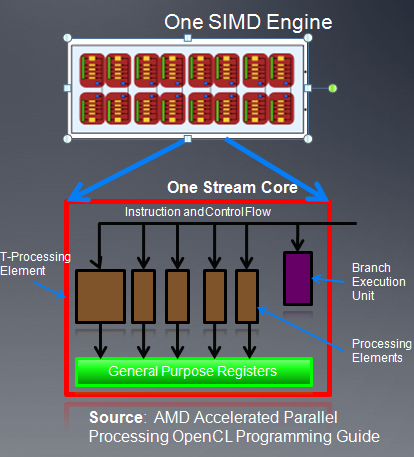
上图为一个simd引擎的示意图,每个simd引擎由一系列的stream core组成。
- 每个stream core是一个5路的VLIW处理器,在一个VLIW指令中,可以最多发射5个标量操作。标量操作在每个pe上执行。
- CU(8xx系列cu对应硬件的simd)内的stream core执行相同的VLIW指令。
- 在CU(或者说simd)内同时执行的work item放在一起称作一个wave,它是cu中同时执行的线程数目。在5870中wave大小是64,也就是说一个cu内,最多有64个work item在同时执行。
注:5路的运算对应(x,y,z,w),以及T(超越函数),在cayman中,已经取消了T,改成四路了。
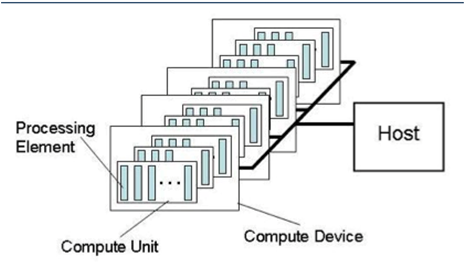
我们现在看下AMD GPU硬件在OpenCL中的对应关系:
- 一个workitme对应一个pe,pe就是单个的VLIW core
- 一个cu对应多个pe,cu就是simd引擎。
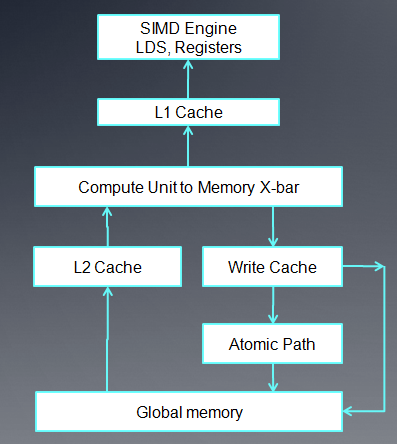
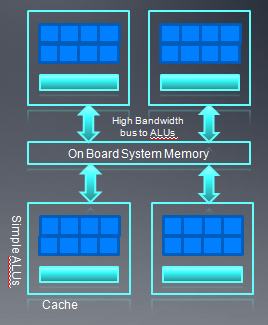
上图是AMD GPU的内存架构:
- 对每个cu来说,它使用的内存包括onchip的LDS以及相关寄存器。在5870中,每个LDS是32K,共32个bank,每个bank 1k,读写单位4 byte。
- 对每个cu来说,有8K的L1 cache。(for 5870)
- 各个cu之间共享的L2 cache,在5870中是512K。
- fast Path只能执行32位或32位倍数的内存操作。
- complete path能够执行原子操作以及小于32位的内存操作。
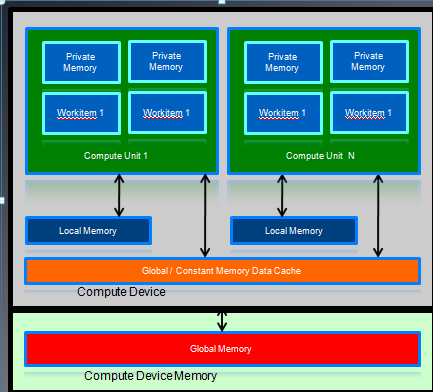
AMD GPU的内存架构和OpenCL内存模型之间的对应关系:
- LDS对应local memeory,主要用来在一个work group内的work times之间共享数据。steam core访问LDS的速度要比Global memory快一个数量级。
- private memory对应每个pe的寄存器。
- constant memory主要是利用了L1 cache
注意:对AMD CPU,constant memory的访问包括三种方式:Direct-Addressing Patterns,这种模式要求不包括行列式,它的值都是在kernel函数初始化的时候就决定了,比如传入一个固定的参数。Same Index Patterns,所有的work item都访问相同的索引地址。Globally scoped constant arrays,行列式会被初始化,如果小于16K,会使用L1 cache,从而加快访问速度。
当所有的work item访问不同的索引地址时候,不能被cache,这时要在global memory中读取。
时间: 2024-10-28 09:04:13