
集成学习是机器学习算法中非常强大的工具,有人把它称为机器学习中的“屠龙刀”,非常万能且有效,在各大机器学习、数据挖掘竞赛中使用非常广泛。它的思想非常简单,集合多个模型的能力,达到“三个臭皮匠,赛过诸葛亮”的效果。集成学习中概念是很容易理解的,但是好像没有同一的术语,很多书本上写得也不一样,越看越模糊。这里我把集成学习分为两个大类,第一大类称为模型融合,与台大机器学习技法课上的blending概念相似,模型融合其实是个再学习的过程。第一步是训练出多个不同的强学习器,然后考虑如何将这多个学习器组合起来,更进一步提高性能。第二大类称为机器学习元算法,这类算法本身就是多模型组合的结果,只是元算法中的基算法(base_algorithm一般会比较弱),称为弱模型的组合,例如RF、GDBT。
一、模型融合
实际中,我们总可以根据实际问题,训练出多个功能强大学习器,为了进一步提高学习器的能力,可以尝试将这些学习组合起来,这个过程就是模型融合。一般来说模型能在一定程度上提高性能,有时使模型的预测能力更加强大,有时增加模型的泛化能力,显而易见的坏处是多模型的学习加上再学习的过程会增加计算的代价。模型融合在竞赛中十分常见,屡试不爽,融合方法恰当,一般能提高成绩。
1.1 常用的获得不同模型的方法
由于不同的训练模型得到不同的模型,例如处理分类的LR、SVM、RF等
由于同一训练模型调节不同参数获得不同的模型,例如GDBT中迭代次数,每个树的复杂度等
有些算法本身就有一定的随机性,如PLA
由于训练数据不同得到不同的模型,如交叉验证、随机抽样
上面这些生成不同模型可以组合生成更多不同的模型,比较常用的是最前面的两个
1.2 模型融合的方法
通过验证(validation)的方式,从第一步中训练出的多个模型中挑选最佳的模型,作为最终的模型。这种方式必须要验证,不同使Ein最小,否则很容易过拟合。
统一融合(Uniform blending),分类时使用一人一票的投票方式,回归时使用多个模型的平均值。这种方式的优点是一般泛化能力会得到加强,但是只能保证比那些模型中最差的模型要好,不能保证能得到比那些不同模型中的最好的模型要好
线性融合(Linear blending),二次学习,使用线性模型将第一步中学习到的学习器组合起来,用得好可以提高模型性能,但是要注意有过拟合的风险。
堆融合(Any blending、stacking),任何其它非线性模型将那些学习器组合起来,有过拟合的风险,注意验证。
模型融合在实际中十分常见,下面是台大在2011KDDCup获得冠军时使用的模型融合方法,先用了any blending (stacking)处于领先群的位置,最后的linear blend使得台大获得冠军。
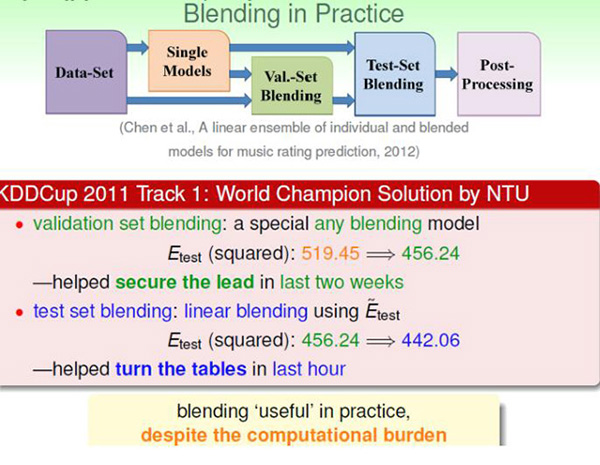
二、机器学习元算法
机器学习元算法分为两类:Averaging methods 和 Boosting methods
Averaging methods 核心是引入随机(对样本、特征属性随机取样)学习产生多个独立的模型,然后平均所有模型的预测值。一般而言,这种方法,会减小方差(variance),不太会过拟合。主要包括bagging、RF。
Boosting methods 逐步加强方法,该方法集合学习多个模型,提高模型的准确率。不同的是,它是基于前面模型的训练结果(误差),生成新的模型,从而减小偏差(bias)。一般而言,这种方法会比上者的准确率高一点,但是也不是绝对的。它的缺点是有过拟合的风险,另外,由于它每个模型是“序列化”(有前后关系)产生的,不易并行化。它的代表是AdaBoost、GDBT。
2.1 Bagging
Bagging 在原始样本中随机抽样获取子集,用随机抽样的子集训练基学习器(base_estimator),然后对每个基学习器的结果求平均,最终得到的预测值。随机获取样本子集的方法有很多中,最常用的是有放回抽样的booststrap,也可以是不放回的抽样。基学习器可以是相同的模型,也可以是不同的,一般使用的是同一种基学习器,最常用的是DT决策树。由于bagging提供了一种降低方差(variance)的方式,所以一般会使用比较强、复杂的基学习器模型(e.g.fully developed decision trees),作为对比在boosting方法中会使用非常弱的基学习器模型(e.g. shallow decision trees)。在sklearn中实现了基于bagging的分类和回归方法,主要设置参数为基学习器的类型、迭代次数(子模型的个数)、获取训练子集的方式。由于bagging训练每个模型可以并行,还可以设置n_jobs训练模型使用的多少个cpu核。
2.2 随机森林(RF)
RF在实际中使用非常频繁,其本质上可bagging并无不同,只是RF更具体一些。一般而言可以将RF理解为bagging和DT(CART)的结合。RF中基学习器使用的是CART树,由于算法本身能降低方差(variance),所以会选择完全生长的CART树。抽样方法使用bootstrap,除此之外,RF认为随机程度越高,算法的效果越好。所以RF中还经常随机选取样本的特征属性、甚至于将样本的特征属性通过映射矩阵映射到随机的子空间来增大子模型的随机性、多样性。RF预测的结果为子树结果的平均值。RF具有很好的降噪性,相比单棵的CART树,RF模型边界更加平滑,置信区间也比较大。一般而言,RF中,树越多模型越稳定。
2.3 AdaBoost
AdaBoost 是一种Boosting方法,与Bagging不同的是,Adaboost中不同的子模型必须是串行训练获得的,每个新的子模型都是根据已训练出的模型性能来进行训练的,而且Boosting算法中基学习器为弱学习。弱学习器可以理解为只比随机猜测好一点,在二分类情况下,错误率略低0.5即可,实际中常使用 small decision trees。AdaBoost中每个训练样本都有一个权重,这些权重构成了一个向量W,初始值都为为Wi=1/N。
Adaboost中每次迭代生成新的子模型使用的训练数据都相同,但是样本的权重会不一样。AdaBoost会根据当前的错误率,增大错误样本权重,减小正确样本权重的原则更新每个样本的权重。不断重复训练和调整权重,直到训练错误率或弱学习器的个数满足用户指定的值为止。Adaboost的最终结果为每个弱学习器加权的结果。使用sklearn中的Adaboot时,主要调节的参数有n_estimator(多少棵树)、max_depth(每棵树的深度。复杂度)或者min_samples_leaf(最少的叶子节点)。
2.4 GDBT
GDBT也是一种Boosting方法,每个子模型是根据已训练出的学习器的性能(残差)训练出来的,子模型是串行训练获得,不易并行化。GDBT使用非常广泛的,能分类,能回归预测。GDBT基于残差学习的算,没有AdaBoost中的样本权重的概念。GDBT结合了梯度迭代和回归树,准确率非常高,但是也有过拟合的风险。GDBT中迭代的残差的梯度,残差就是目前结合所有得到的训练器预测的结果与实际值的差值,不理解可以参考另一篇博客,里面有一个实例介绍如何基于残差来学习预测人的年龄。GDBT的使用也非常的简单,主要调节的参数有确定需要多少棵树(n_estimator)、每棵树的复杂度(max_depth,max_leaf_node)、损失函数(loss)以及学习率(learning_rating)。为了防止过拟合一般学习率会选小一点的(<0.1),learning_rate会影响n_estimator,需要权衡,选择最佳的组合参数。
本文作者:雪姬
来源:51CTO