面对当今大数据存储,设想当mysql中一个表的总记录超过1000W,会出现性能的大幅度下降吗?
答案是肯定的,一个表的总记录超过1000W,在操作系统层面检索也是效率非常低的
解决方案:
目前针对海量数据的优化有两种方法:
1、大表拆小表的方式(主要有分表和分区两者技术)
(1)分表技术
垂直分割
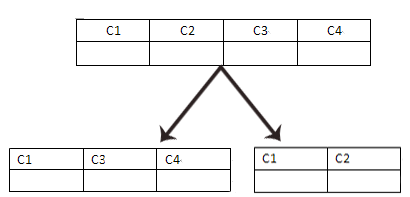
优势:降低高并发情况下,对于表的锁定。
不足:对于单表来说,随着数据库的记录增多,读写压力将进一步增大。
水平分割
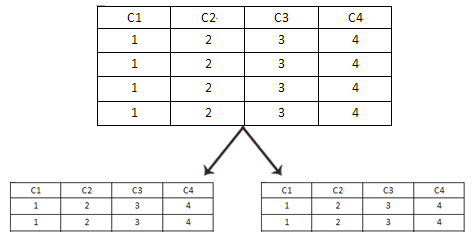
如果单表的IO压力大,可以考虑用水平分割,其原理就是通过hash算法,将一张表分为N多页,并通过一个新的表(总表),记录着每个页的的位置。假如一个门户网站,它的数据库表已经达到了1000万条记录,那么此时如果通过select去查询,必定会效率低下(不做索引的前提下)。为了降低单表的读写IO压力,通过水平分割,将这个表分成10个页,同时生成一个总表,记录各个页的信息,那么假如我查询一条id=100的记录,它不再需要全表扫描,而是通过总表找到该记录在哪个对应的页上,然后再去相应的页做检索,这样就降低了IO压力。
水平分表技术就是将一个表拆成多个表,比较常见的方式就是将表中的记录按照某种HASH算法进行拆分,同时,这种分区方法也必须对前端的应用程序中的SQL进行修改方能使用,而且对于一个SQL语句,可能会修改两个表,那么你必须要修改两个SQL语句来完成你这个逻辑的事务,会使得逻辑判断越来越复杂,这样会增加程序的维护代价,所以我们要避免这样的情况出现。
2、SQL语句的优化(索引)
SQL语句优化:可以通过增加索引等来调整,但同时数据量的增大会导致索引的维护代价增大。
分区优点:
1、减少IO
2、提高读写
3、方便数据管理
分区与分表的区别:
分区是逻辑层面进行了水平分割,对于应用程序来说,它仍是一张表。
分区就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上
1. 实现方式上
(1)mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完整的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构文件。
[root@BlackGhost test]# ls |grep user
alluser.MRG
alluser.frm
user1.MYD
user1.MYI
user1.frm
user2.MYD
user2.MYI
user2.frm
简单说明一下,上面的分表是利用了merge存储引擎(分表的一种),alluser是总表,下面有二个分表,user1,user2。他们二个都是独立的表,取数据的时候,我们可以通过总表来取。这里总表是没有.MYD,.MYI这二个文件的,也就是说,总表他不是一张表,没有数据,数据都放在分表里面。我们来看看.MRG到底是什么东西
[root@BlackGhost test]# cat alluser.MRG |more
user1
user2
#INSERT_METHOD=LAST
从上面我们可以看出,alluser.MRG里面就存了一些分表的关系,以及插入数据的方式。可以把总表理解成一个外壳,或者是连接池。
(2)分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
[root@BlackGhost test]# ls |grep aa
aa#P#p1.MYD
aa#P#p1.MYI
aa#P#p2.MYD
aa#P#p2.MYI
aa#P#p3.MYD
aa#P#p3.MYI
aa.frm
aa.par
从上面我们可以看出,aa这张表,分为3个区。我们都知道一张表对应三个文件.MYD,.MYI,.frm。分区根据一定的规则把数据文件和索引文件进行了分割,还多出了一个.par文件,打开.par文件后你可以看出他记录了,这张表的分区信息,跟分表中的.MRG有点像。分区后,还是一张,而不是多张表。
2. 数据处理上
(1)分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。看下面的例子:
select * from user1 user2 where id=’12’表面上看,是对表alluser进行操作的,其实不是的。是对alluser里面的分表进行了操作。
(2)分区,不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表,还是一张表。数据处理还是由自己来完成。
select * from alluser where id=’12’
3. 提高性能上
(1)分表后,单表的并发能力提高了,磁盘I/O性能也提高了。因为查询一次所花的时间变短了,如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。本来一个非常大的.MYD文件现在也分摊到各个小表的.MYD中去了,因此对于磁盘IO压力也降低了。
(2)mysql提出了分区的概念,我觉得就想突破磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
在这一点上,分区和分表的侧重点不同,分表重点是存取数据时,如何提高mysql并发能力上;而分区呢,则是如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
4. 实现的难易度上
(1)分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式根分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。
(2)分区实现是比较简单的,建立分区表,跟建平常的表没什么区别,并且对开代码端来说是透明的。
分区类型
hash、range、list、key
- RANGE分区:基于一个给定连续区间的列值,把多行分配给分区。
- LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
- HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
hash用在数据相对比较随机的情况下。它是根据表中的内容进行hash运算后随机平均分配,假设这个列是性别,则不适合用hash分区,因为内容要么是男,要么是女,没有随机性。
- KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。 —-很少用到
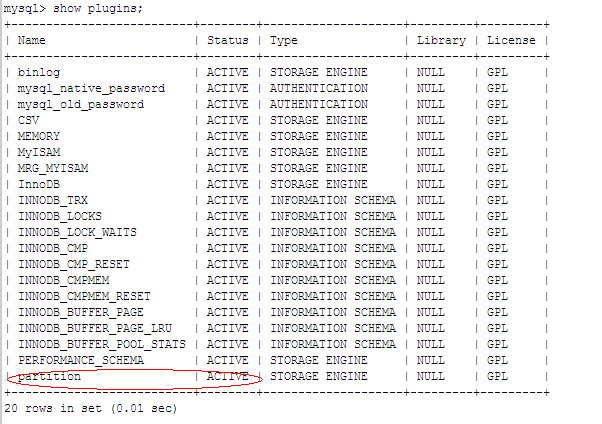
如何查看数据库是否支持分区技术?
创建分区:
mysql> create table t1(id int)partition by hash(id)partitions 3;
Query OK, 0 rows affected (0.03 sec)
【实验】
分别创建一个分区的表和非分区的表,进行性能测试
创建分区表
mysql> create table part_tab ( c1 int default NULL, c2 varchar(30) default null, c3 date default null) engine=myisam
-> partition by range(year(c3))(
-> partition p0 values less than (1995),
-> partition p1 values less than (1996),
-> partition p2 values less than (1997),
-> partition p3 values less than (1998),
-> partition p4 values less than (1999),
-> partition p5 values less than (2000),
-> partition p6 values less than (2001),
-> partition p7 values less than (2002),
-> partition p8 values less than (2003),
-> partition p9 values less than (2004),
-> partition p10 values less than (2010),
-> partition p11 values less than MAXVALUE);
Query OK, 0 rows affected (0.14 sec)
创建非分区表
mysql> create table no_part_tab ( c1 int default NULL, c2 varchar(30) default null, c3 date default null) engine=myisam;
Query OK, 0 rows affected (0.11 sec)
mysql> \d // #由于下面要用到存储过程,这里需要修改结束符为“//”。所谓的存储过程其实也就是众多sql语句的集合。
mysql> create procedure load_part_tab()
-> begin
-> declare v int default 0;
-> while v < 8000000
-> do
-> insert into part_tab
-> values (v,’testing partitions’,adddate(‘1995-01-01′,(rand(v)*36520)mod 3652));
-> set v = v+1;
-> end while;
-> end
-> //
Query OK, 0 rows affected (0.04 sec)
mysql> \d ; // 执行完这个存储过程后,需要将结束符修改回去
上面的存储过程实际上是为了创建大量的数据(800万条)
mysql> call load_part_tab(); // 调用load_part_tab这个存储过程
Query OK, 1 row affected (9 min 18.95 sec)
快速将part_tab里面的数据插入到no_part_tab里面
mysql> insert no_part_tab select * from part_tab;
Query OK, 8000000 rows affected (8.97 sec)
Records: 8000000 Duplicates: 0 Warnings: 0
测试一:
实验之前确保两个表里面的数据是一致的!保证实验的可比性
mysql> select count(*) from part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
+———-+
| count(*) |
+———-+
| 795181 |
+———-+
1 row in set (0.49 sec)
mysql> select count(*) from no_part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
+———-+
| count(*) |
+———-+
| 795181 |
+———-+
1 row in set (3.94 sec)
mysql> desc select count(*) from part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31’\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part_tab
type: ALL //全表扫描
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 798458
Extra: Using where
1 row in set (0.09 sec)
ERROR:
No query specified
mysql> desc select count(*) from no_part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31’\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: no_part_tab
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8000000
Extra: Using where
1 row in set (0.00 sec)
ERROR:
No query specified
结论:可以看到,做了分区之后,只需要扫描79万条语句,而不做分区的,则需要进行全表扫描,故可以看出,做了分区技术后,可以提高读写效率。
测试2:
创建索引,查看语句执行情况
mysql> create index idx_c3 on no_part_tab(c3);
Query OK, 8000000 rows affected (32.68 sec)
Records: 8000000 Duplicates: 0 Warnings: 0
结果分析:
mysql> desc select count(*) from no_part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31’\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NO_part_tab
type: range
possible_keys: idx_c3
key: idx_c3
key_len: 4
ref: NULL
rows: 785678
Extra: Using where; Using index
1 row in set (0.16 sec)
ERROR:
No query specified
结论:为未分区的表创建了索引之后,再次执行相同的语句,可以看到该SQL语句是根据range索引进行检索,而不是全表扫描了。明显效率也提高了。
测试3:
测试做索引与未作索引的读写效率。
mysql> create index idx_c3 on part_tab(c3);
Query OK, 8000000 rows affected (31.85 sec)
Records: 8000000 Duplicates: 0 Warnings: 0
mysql> desc select count(*) from part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31’\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part_tab
type: index
possible_keys: idx_c3
key: idx_c3
key_len: 4
ref: NULL
rows: 798458
Extra: Using where; Using index
1 row in set (0.14 sec)
ERROR:
No query specified
测试未创建索引字段
mysql> select count(*) from no_part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′ and c2=’hello';
+———-+
| count(*) |
+———-+
| 0 |
+———-+
1 row in set (4.90 sec)
结论:可以看到如果没通过索引进行检索所耗费的时间将长于通过索引进行检索。
测试4:删除
mysql> delete from part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
Query OK, 795181 rows affected (14.02 sec)
mysql> delete from no_part_tab where c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
Query OK, 795181 rows affected (15.21 sec)
结论:可以看到,在删除方面,有分区的还是比没分区的快一点。从而体现了其便于数据管理的特点
方便数据管理这点,我通过下面的例子来说明:比如数据库的表t1记录的是今年一整年(12个月)公司的营业额,在未分区的情况下,也就是说数据文件都存放在同一个文件里面,那么假如现在要删除第一个季度的记录,那么需要全表扫描才能得出结果。但如果t1这个表事先做了分区,那么我只需要分别删除1,2,3这三个文件即可。所以从一定程度上,还是方便了管理。
本文出自 “pmghong” 博客,请务必保留此出处http://pmghong.blog.51cto.com/3221425/1301945