1.1 简单的数据并行循环
在顺序处理器程序设计中,需要编写计算某个最终结果所需要的任务和数据操作的程序。通过创建OpenACC,编程人员可以插入编译指令给编译器提供信息,而这些编译指令是关于并行机会和数据在加速器与主机间来回传输的信息。结合编译器,程序员使用注记来创建、调试和优化并行代码,使得程序达到高性能。
OpenACC帮助程序员编写高效的数据和任务并行软件。
数据并行关注跨多个并发执行线程的分布式数据操作。在计算机科学中,线程是串行执行一段代码的线程的缩写。通过使用多个线程,应用程序可以使用并行硬件,例如多核处理器和大规模并行GPU。通过多个线程并发执行,这些并行硬件使得应用程序运行得更快,同时意味着单位时间内可以执行更多任务。
类似地,任务并行关注跨多个并发执行线程的分布式计算任务。同时执行多个任务,也可以让应用程序运行得更快。
如图1-1所示,C++示例accFill_ex1.cpp展示了数据并行,程序动态分配数组status,并且给数组赋值。

这个示例遵循了良好的编程习惯—检查用户输入:确定数组大小大于0。对赋值后的结果进行检查,确保程序退出时数组status中的元素确实成功被赋值为1。通过调用assert()来执行实际的检查,如果条件(sum==nCount)为假将会产生一个核心转储。同时也应该注意在设备并行区域不能调用assert,因为不允许提前退出。
写程序时使用assert()是帮助验证程序正确性的好方法,在调试模式下,断言(assertion)可以很快找到程序错误。调试完成后,在编译时定义NDEBUG来移除断言。因此,一旦调试完成后,assert()不会有任何的运行时或内存消耗。
良好的编程习惯规定需要验证应用程序接口(API)调用是否成功。细心的读者会注意到程序没有检查status的动态内存分配成功与否。为简化代码,忽略了这一项。
“#pragma acc parallel loop copyout(status[0:nCount])”是OpenACC注记,这条注记把accFill_exl.cpp从一个串行程序转变为可能使用几千个并发线程执行的并行程序。
这条注记解释如下:#pragma acc parallel loop。#pragma acc告诉编译器这是OpenACC注记。parallel关键字告诉编译器使用并行构件(construct)规则(相对应的是kernels构件),这会在1.1.1节讨论。loop子句告诉编译器希望并行化C++的for循环。OpenACC注记使用C++范围规则来定义注记应用于哪个代码块范围。这个例子中for循环内的代码将会被并行执行。
copyout(status[0:nCount])。这个子句告诉编译器在OpenACC设备上创建一个数组status,数组索引从0开始,有nCount个元素的数组status。执行完并行区域以后将会把这些元素从设备端拷贝回主机端,因此主机端status的值与设备端一致。
在这个例子中使用copyout()而不是copy(),是为了避免主机端向设备端拷贝不必要的未初始化的数据。
执行串行代码的OpenACC主机端与并行设备共享内存时,在特定的情况下并不需要编译器执行数据拷贝。例如,这个OpenACC示例运行在多核处理器上时并不需要数据拷贝。
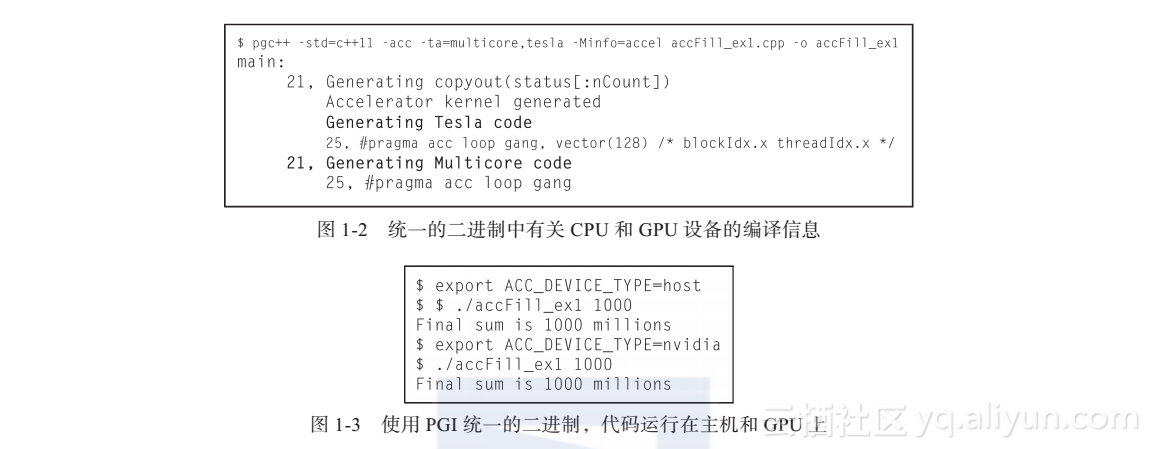
如图1-2所示,使用The Portland Group(PGI)统一的二进制可以把源码编译、运行在中央处理器(CPU)和图形处理器(GPU)。统一的二进制包含多个设备的可执行文件。-Minfo=accel命令行参数告诉编译器输出循环并行化的加速器信息。如黑体所示,产生了Tesla和多核处理器的内核。使用tesla是因为nvidia关键字已经被弃用了。tesla可执行文件可以运行在所有的NVIDIA GPU上。本章使用PGI 16.5编译器。
如图1-3所示,程序在多核x86处理器和NVIDIA GPU上成功执行。使用统一的二进制时,PGI OpenACC运行时检查ACC_DEVICE_TYPE环境变量来确定使用什么设备。
1.1.1 OpenACC内核构件与并行构件对比
OpenACC有两种并行计算构件:之前accFill_ex1.cpp例子中使用的并行构件(parallel construct)和接下来将讨论的内核构件(kernels construct)。
简单来说,OpenACC中的并行构件告诉编译器在接下来区域内的所有操作是一个单独的并行操作,每个线程都将会执行这个并行操作。增加loop子句(如之前的示例)是告诉编译器尝试并且并行化线程中循环内所有的操作,这和OpenMP程序员期望的一样。以CUDA为例,并行构件转换为一个CUDA内核。
安全提示:常见的错误是忘记添加循环指令(例如,只指定#pragma acc parallel),这会错误地告诉编译器接下来范围内的所有操作将会并行执行,这意味着每个并行线程都会执行这个for循环。同样,在语法中也很容易忘记acc,导致循环根本不会并行化。上述是众多编译错误中的两个原因,说明了检查编译器信息和核实每个并行区域在设备上实际运行的重要性。
相反,内核构件能使编译器更灵活地为目标设备生成高效的并行代码,包含将多个循环组合为单个的并行内核或者创建多个并行内核。同时编译器负责确保并行化循环是安全的,这点与并行构件不同,并行构件告诉编译器这么做是安全的。这也意味着编译器会很小心,有时并行化特定循环时需要更多的信息。内核并行化处理有三个步骤:
1.确认可以并行执行循环。
2.将抽象的循环并行性映射到具体的设备并行性上(例如,线程可以运行在多核处理器或适当并行配置的GPU上)。
3.编译器生成并且优化实际的代码来实现选定的并行性映射。
接下来的示例accFill_ex2.cpp使用内核构件在OpenACC设备上并行执行赋值操作和求和计算。如图1-4所示,程序使用内核构件移除数组传输,所有的计算将在设备上执行。

注意这两个例子中C++代码的逻辑是一样的,只有OpenACC语法有差异。
accTask_ex1.cpp中为#pragma acc parallel loop opyout(status[0: nCount])
accTask_ex2.cpp中为#pragma acc kernels create(status[0:nCount])
另外,添加大括号“{”和“}”来定义内核构件的范围。使用create子句在Open-ACC设备上分配status数组空间。
第二个注记#pragam acc loop vector reduction(+:sum)指定了向量归约求和。
简单来说,当目标设备支持向量归约求和时,代码中指定的归约计算数组status中所有元素的和。更确切地说,reduction()子句带操作符(示例中为“+”)和一个或多个标量变量。示例使用sum变量。在OpenACC区域最后,并行结果与原有变量的值相结合。这也就是为什么在归约操作前sum必须初始化为某个值(示例中为0),否则将导致未定义的行为。
vector子句告诉OpenACC编译器可以利用向量并行。
向量指令使用硬件在同一时间内执行多个操作,因而它是另一种形式的并行。现代多核x86处理器的每个核可以向硬件向量单元(或多核向量单元)发送向量指令,使得同一时刻执行多个数据并行操作。例如,AVX-512向量指令集是x86处理器当前最长的向量指令集,每条指令调用可以处理16个并发单精度、32位浮点操作。结果是每个向量单元达到16倍的性能提升。充分利用高端处理器上所有核的向量单元,可以导致很大的性能增益。GPU使用SIMD(单指令多数据)指令来达到类似的性能增益效果,只是在硬件的一个warp(CUDA术语,32个线程的集合)中跨线程地进行向量化,而不是由程序员或编译器显式发送向量指令。
图1-5显示了在多核处理器上向量与并行编程的性能增益。
1.1.2 OpenACC并行的多种形式
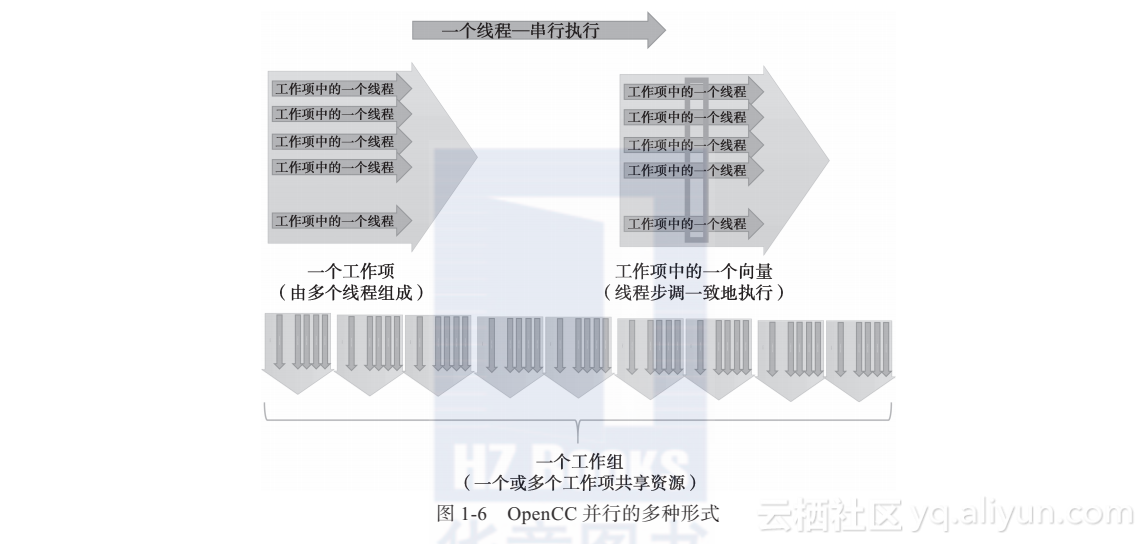
OpenACC执行模型允许用户表达3个层次的并行:工作组(gang)、工作项(worker)和向量(vector)。
如图1-6所示,从顶部开始:
线程:核心并行概念,单个、串行执行的线程,可以运行任何有效的C、C++或Fortran代码。
工作项:可以以SIMD或向量方式一起执行的线程组合称为工作项。(CUDA程序员认为OpenACC中的一个工作项就是一个warp。)
向量:运行向量或SIMD指令时,向量使工作项线程步调一致地运行。
工作组:工作项的组合称为工作组。(CUDA程序员认为一个工作组就是一个CUDA线程块。)工作组彼此独立地执行。
1.1.3 accFill_ex2运行时结果
从下面的PGI编译器报告可以看出,源代码使用create()子句在设备上分配数据空间,主机与设备间不需要拷贝操作。编译器决定GPU和多核CPU设备上都并行化内核区域里的循环(见图1-7)。


接下来的命令显示代码在CPU和GPU上都成功执行。使用ACC_DEVICE_TYPE环境变量来指定运行时设备(见图1-8)。
