MaxCompute 入门
why
在分析海量数据场景下,由于单台服务器的处理能力限制,数据分析者通常采用分布式计算模式。但分布式的计算模型对数据分析人员提出了较高的要求,且不易维护。使用分布式模型,数据分析人员不仅需要了解业务需求,同时还需要熟悉底层计算模型。
举个例子来说,当我们需要统计海量的数据时,常规的做法是我们要先搭建hadoop集群,启动ResourceManager,NodeManager,Namenode等组件,然后部署Hbase。接下来是导入数据到Hbase,最后开始设计并实现MapReduce或者Spark,Flink等job........可能很多人在第一步就已经从入门到放弃了
what
大数据计算服务(MaxCompute,原名 ODPS)是一种快速、完全托管的 GB/TB/PB 级数据仓库解决方案。MaxCompute 向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
MaxCompute 主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。随着社会数据收集手段的不断丰富及完善,越来越多的行业数据被积累下来。数据规模已经增长到了传统软件行业无法承载的海量数据(百 GB、TB 乃至 PB)级别。
how
接下来就亲自实践一下官方给的bank的例子吧,如建表并导入数据
中提到的,先创建bank_data和result_data两个表,并导入数据。接下来我们创建工作流去统计不同学历的单身人士贷款买房的数量。直接cp示例sql后,首先弹出了如下对话框: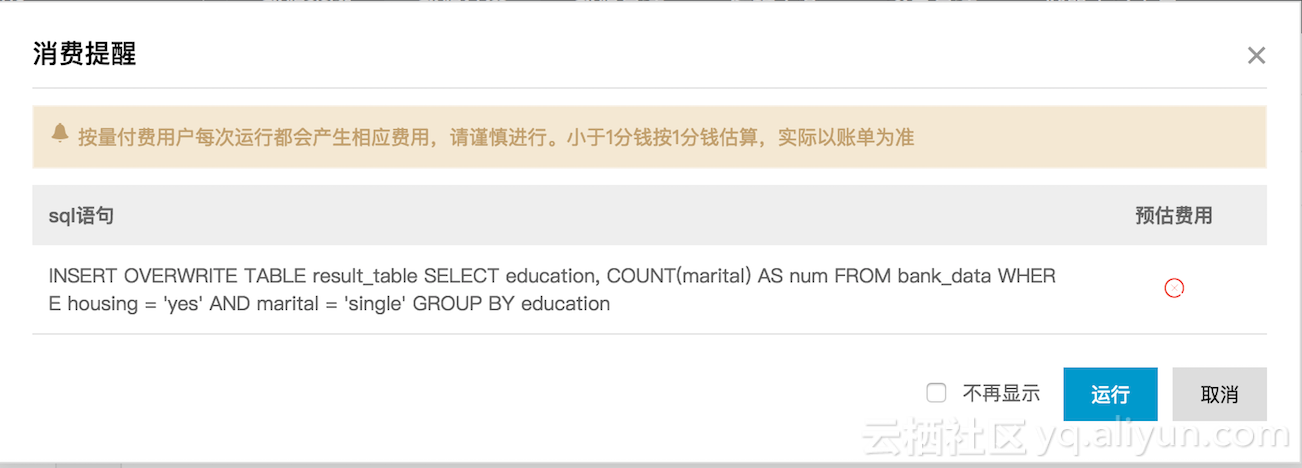
因为选择的是IO后付费,但不知为何预估费用没有显示,不管了,先运行看看,得到如下提示: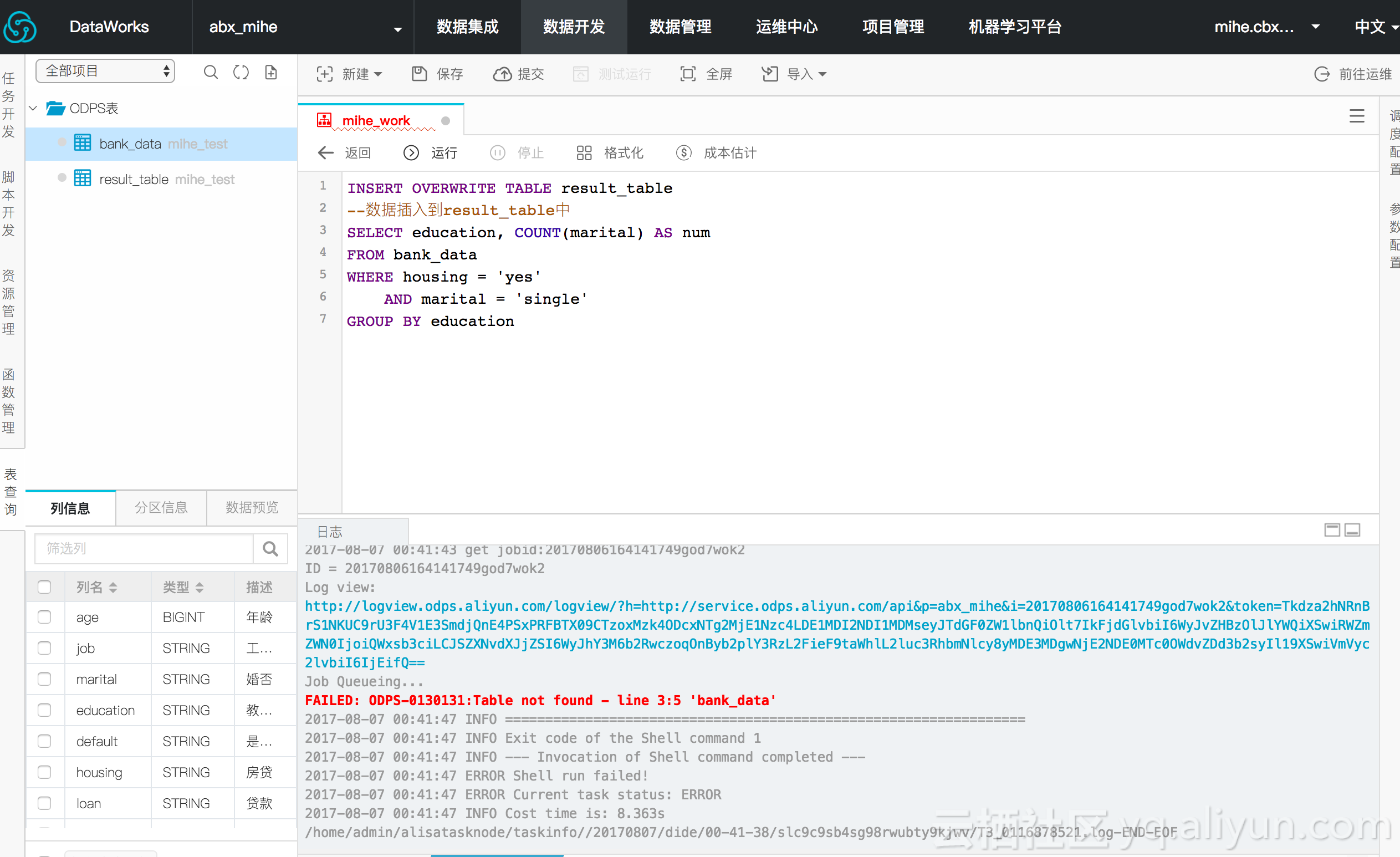
原因是未找到table,仔细看下左侧的ODPS表,原来还有个mihe_test的前缀,修改sql再试:
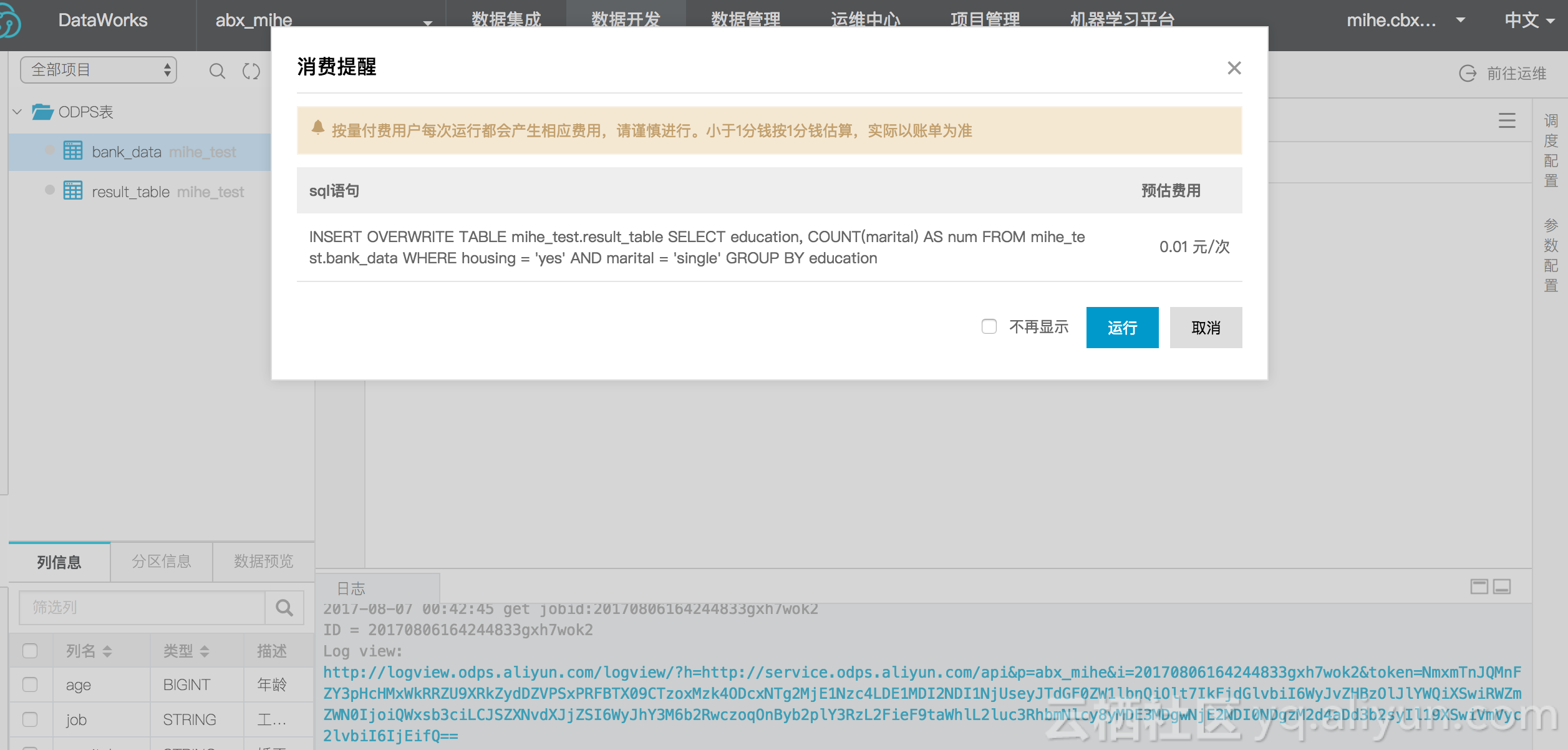
这次给出了预估费用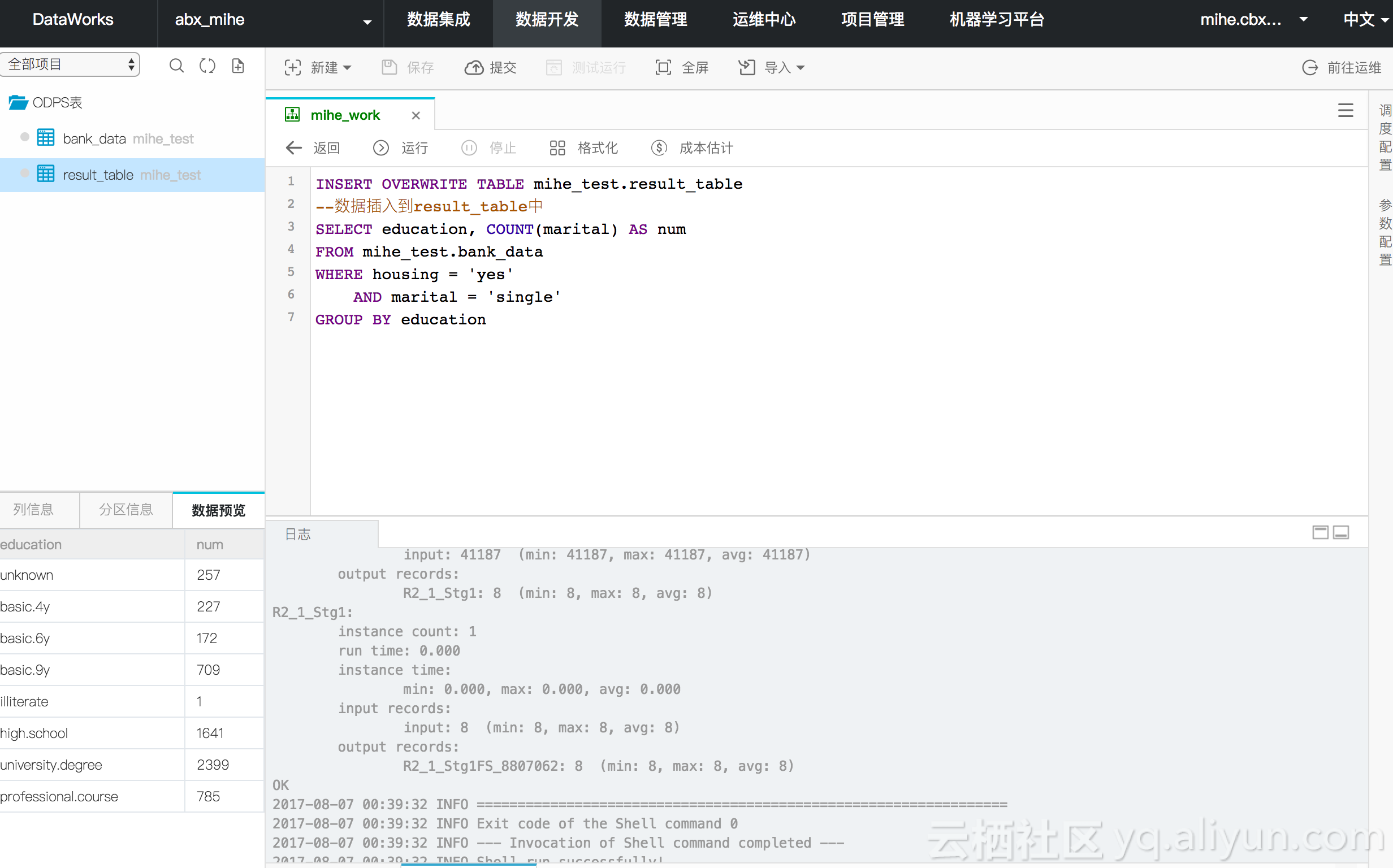
运行成功,我们在resu_table中也看到了结果
这种拖拽式真的很方便
PS:
1. 貌似通过预估费用就可以预判出sql是否正确了?
2. 在创建项目是随便写了个test,提示项目被占用了,但自己的项目列表里没有,后来发现,原来项目名称是全局的,最后加了个前缀解决了。从平台管理的角度来说要保证project name的唯一性无可厚非,但是从用户角度来看,自己的project应该就是在自己的域下面,不应该存在被占用的情况,所以是否可以考虑允许用户随意指定名称,只是管理的时候加个用户的域的前缀?