本文我们将通过对有同样数据量、表结构除分区列其他都一模一样的表,从查询计算、写入、删除数据几个简单操作进行对比,了解MaxCompute分区表和非分区表在使用上有什么差异。
在介绍之前,需要大家先了解MaxCompute分区的概念。
数据准备
分区表:取公共数据集中的表dwd_prouduct_house_basic_info_out(二手房产数据集);
非分区表:执行建表语句:
create table dwd_prouduct_house_basic_info_out_npt as select * from public_data.dwd_prouduct_house_basic_info_out;
创建表的同时将源表的所有数据都复制到新表dwd_prouduct_house_basic_info_out_npt中。
由于create table … as select … 语句创建的表不会复制分区属性,只会把源表的分区列作为目标表的一般列处理,所以新表dwd_prouduct_house_basic_info_out_npt为非分区表。
可以分别执行select count(*) from public_data.dwd_prouduct_house_basic_info_out; 和 select count(*) from dwd_prouduct_house_basic_info_out_npt;查看这两个表的记录数会是一样。
本次操作表的记录数为1147676063条。
计算对比
我们执行一个简单的查询某个分区数据的job:
Select * from public_data.dwd_prouduct_house_basic_info_out where ds= '20170113';--分区表查询
Select * from dwd_prouduct_house_basic_info_out_npt where ds= '20170113';--非分区表查询计算时长对比
计算资源充足的情况下进行操作。
- 分区表里查询使用时间1秒,:
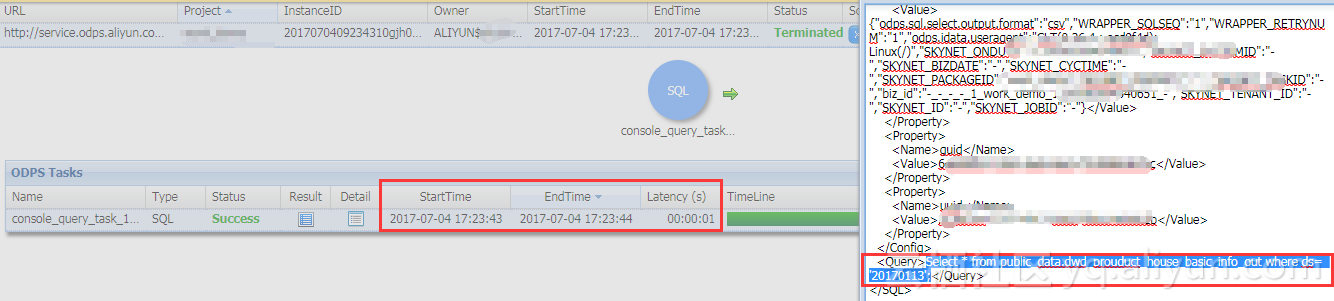 直接在对应分区中取出该分区所有数据。 - 非分区里表查询:
加上job等待时间共1分15秒 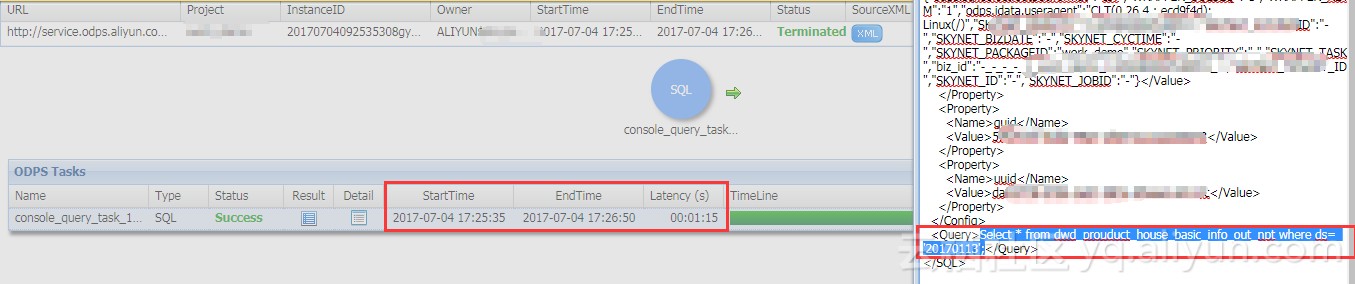 真正执行时长53秒  需要在整个表1147676063条记录中取出满足条件的数据。 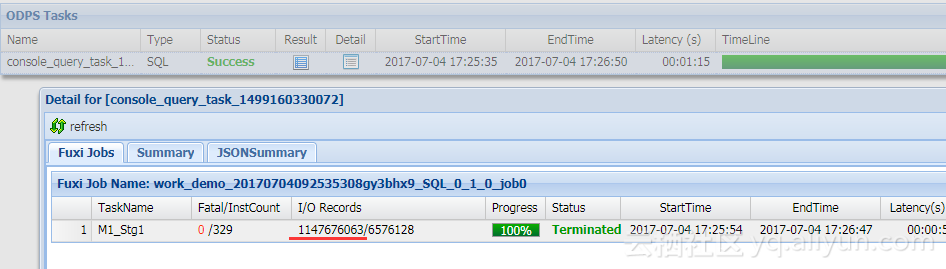
计算费用对比
我们可以直接通过大数据开发套件->“数据开发”工作区中的“成本估计”对两条查询语句进行费用预估,该预估功能采用的计费公式可参考“[计量计费->I/O后付费](https://help.aliyun.com/document_detail/27989.html
)”。
若采用计算预付费模式,可不用在意该计算费用。
下图是通过成本估计功能预估的费用,结果显示在非分区表中查询一样条件的数据会花费更多,当然最终花费还得看最后的账单。
![]()
table size对比
由于MaxCompute存储压缩比不一定完全一致,两个表数据在MaxCompute的size也会有一定的差异。
desc public_data.dwd_prouduct_house_basic_info_out; 分区表执行结果如下图:
![]()
desc dwd_prouduct_house_basic_info_out_npt; 非分区表执行结果如下图:
![]()
写入对比
创建三个表,表结构除了分区列,其他都一致:
- 非分区表,
create table house_test_npt(house_id string , house_total_price string , house_unit_price string , house_type string , house_floor string , house_direction string , house_deckoration string , house_area string , house_community_name string , house_region string , house_city string, ds string) - 以时间为分区的分区表
create table house_test_pt_1(house_id string , house_total_price string , house_unit_price string , house_type string , house_floor string , house_direction string , house_deckoration string , house_area string , house_community_name string , house_region string , house_city string ) partitioned by ( ds string) - 以时间为一级分区,城市为二级分区的分区表
create table house_test_pt(house_id string , house_total_price string , house_unit_price string , house_type string , house_floor string , house_direction string , house_deckoration string , house_area string , house_community_name string , house_region string ) partitioned by (ds string , house_city string)
分别执行3个insert语句,源表取一模一样的数据,即select分句一模一样:
insert overwrite table house_test_npt select house_id,house_total_price,house_unit_price,house_type,house_floor,house_direction,house_deckoration,house_area,house_community_name,house_region,house_city,ds from public_data.dwd_prouduct_house_basic_info_out where ds ='20170114';--写入非分区表
insert overwrite table house_test_pt_1 partition (ds='20170114') select house_id,house_total_price,house_unit_price,house_type,house_floor,house_direction,house_deckoration,house_area,house_community_name,house_region,house_city from public_data.dwd_prouduct_house_basic_info_out where ds ='20170114';--写入一级分区表
insert overwrite table house_test_pt partition (ds='20170114',house_city) select house_id,house_total_price,house_unit_price,house_type,house_floor,house_direction,house_deckoration,house_area,house_community_name,house_region,house_city from public_data.dwd_prouduct_house_basic_info_out where ds ='20170114';--使用动态分区方式写入二级分区表
对比执行过程:
- 非分区表,一个task,耗时41s:
 - 一级分区表,一个task,耗时41s:
 - 二级分区表,第二级分区值为动态输入,2个task,最长task耗时1分31秒:

数据删除操作对比
假设要删除表某一天的数据,由于MaxCompute不支持delete语法,我们需要通过别的方式进行数据删除。
- 分区表只需要通过alter语句drop对应分区即可,如下删除分区为20170112的数据:
ALTER TABLE public_data.ods_enterprise_share_basic DROP IF EXISTS PARTITION (ds='20170112'); - 非分区表,需要将不需要删除的数据查询出来并覆盖写入方式写回表中,增加了计算量。
INSERT OVERWRITE TABLE dwd_prouduct_house_basic_info_out_npt SELECT * FROM dwd_prouduct_house_basic_info_out_npt WHERE ds<>'20170112';