待优化SQL: 

- 我们来分析下这条SQL存在的问题是什么?
每条SQL都要进行limit 分页 1000 ,每次SQL扫描的时候都会多扫描出来1000依次类似 每个SQL1+1000+SQl n 1000扫描的行数越来越多,SQL执行越来越慢 - 那么我们这个时候应该如何进行优化呢?
1.查看表结构:
- 接下来看一下SQL:
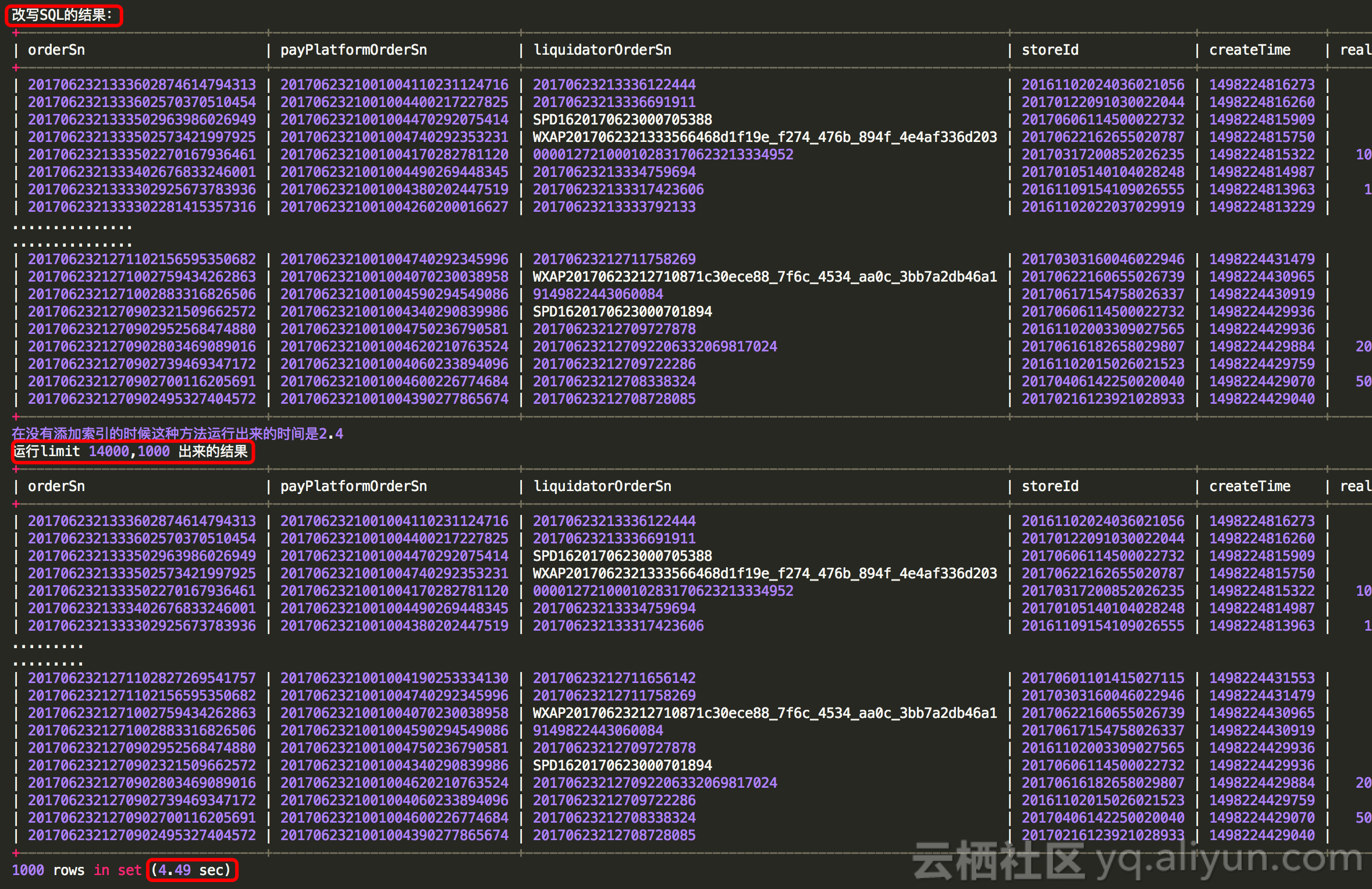
- SQL2:SQL1:limit 13000,1000 SQL 2:limit 14000,1000 SQL3 15000,1000 .......
每次进行limit分页后面就会越来越多,我们怎么优化呢?
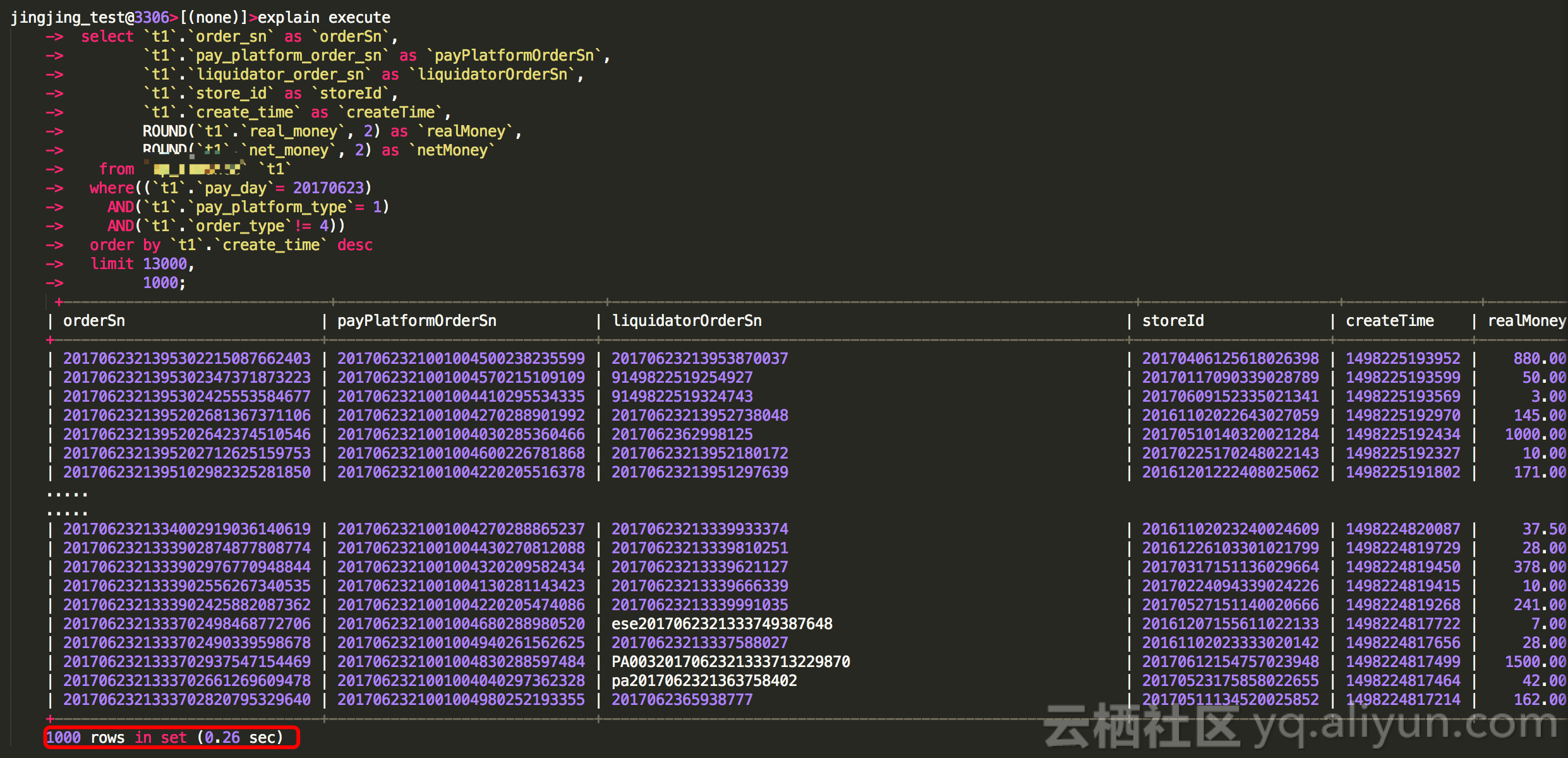
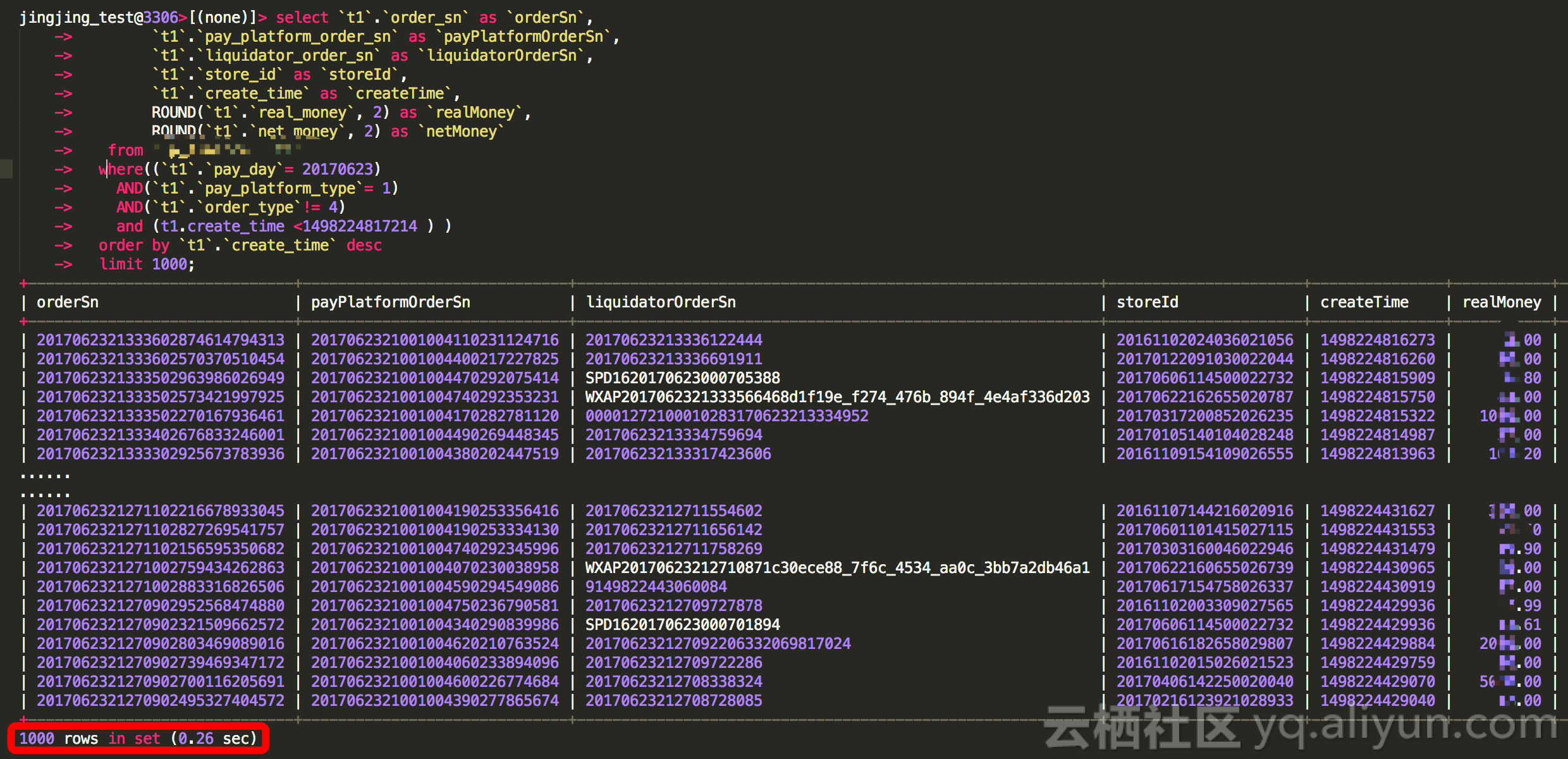
可以进行使用create_time的时候来取,yinw create_time desc 每次取值小于 上次 最后一个分页的值,程序中可以获取到最后一个值
**改写: **
NOTE:执行这条SQL的运行结果:与limit 14000, 1000 结果对比是否正确 注意create_time必须要唯一,要不然数据会出错 - 改写SQL与原始SQL结果对比:
和使用create_time方式的结果一样正确,那么我们可以利用这种方式进行优化此条SQL
在SQL还没有较好的索引的时候就已经快了2ms
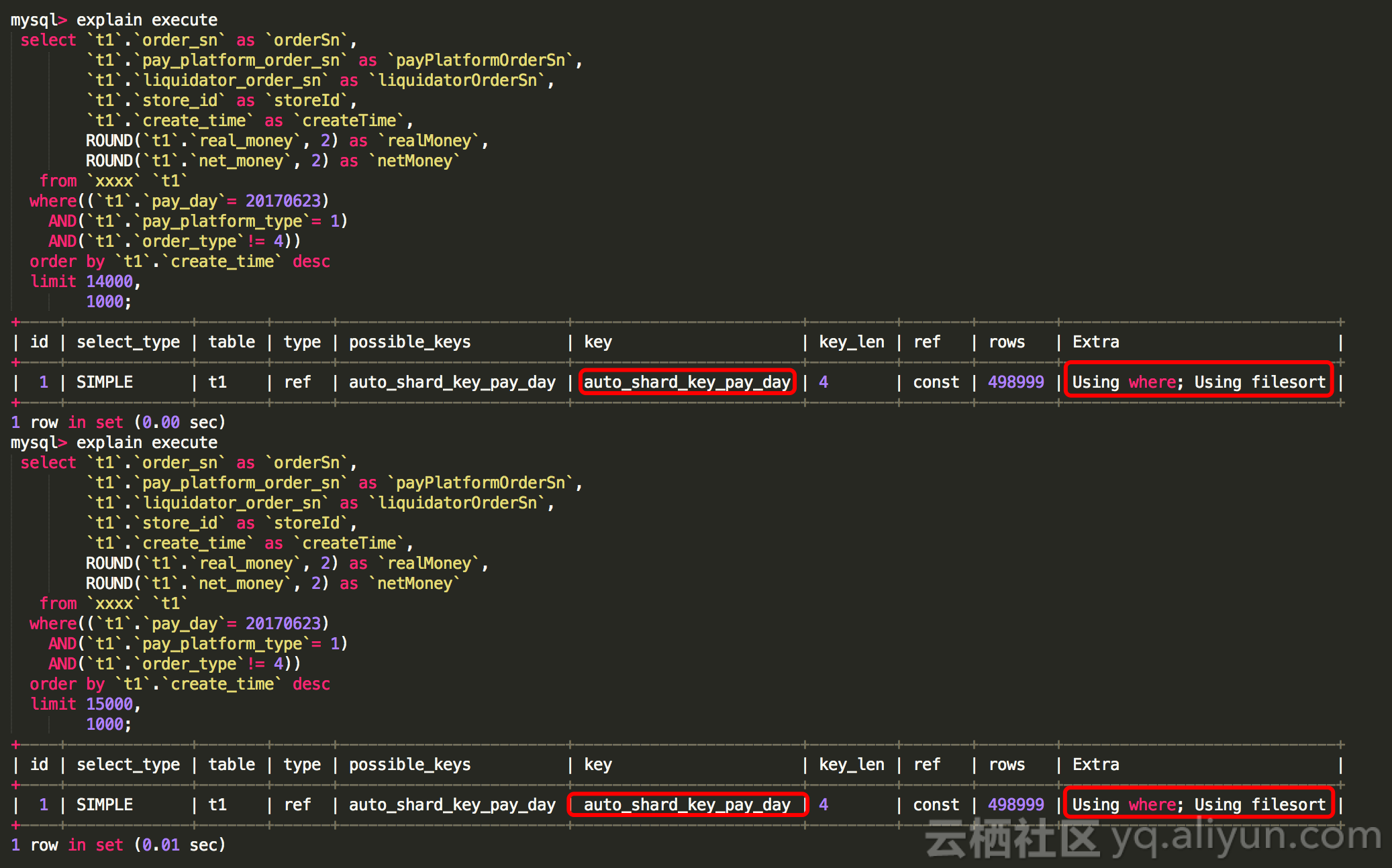
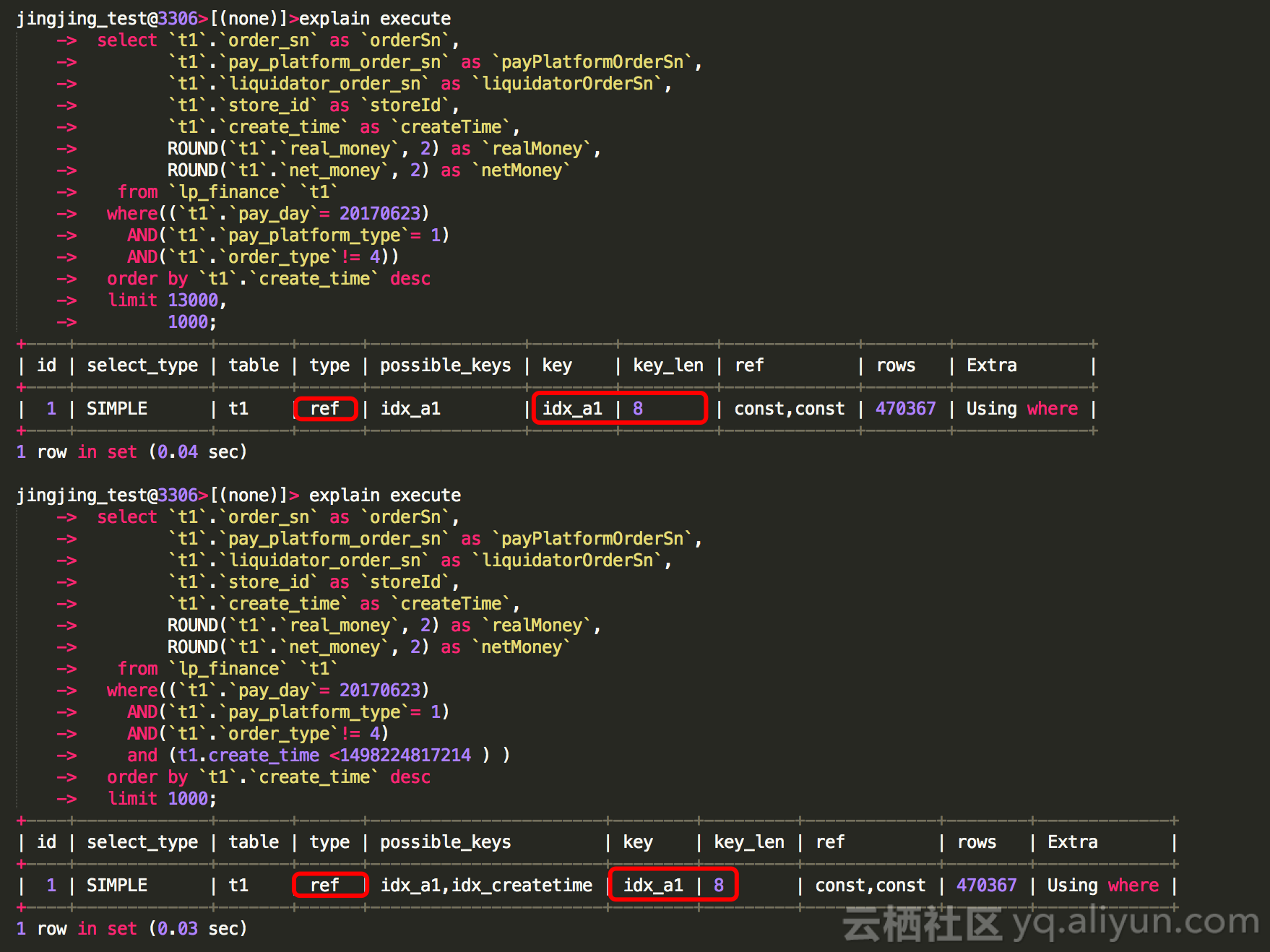
那么这个SQL应该如何添加索引呢? - 没有添加索引之前的执行计划:
从执行计划中 Extra 部分有 Using filesort ,而且rows 有将近50w,说明索引选用的选择率不理想; - 那么如何添加索引呢?
添加索引:
alter table lp_finance add index `idx_a1` (`pay_day`,`pay_platform_type`,`create_time`)
- 执行时间:
- 执行计划:
那么这里面还存在这一个问题:就是type 为 ref
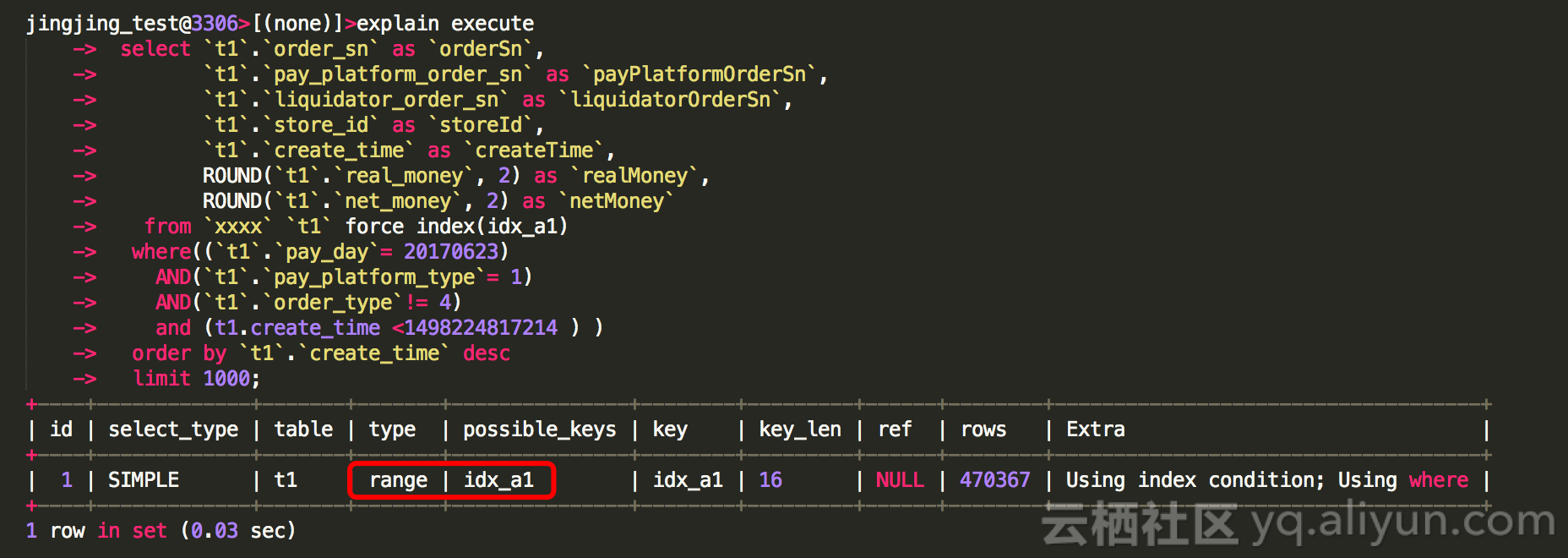
那么我们来强制索引测试下:
这个时候需要思考一个问题,为什么不强制的时候,走的也是 idx_a1 type 为ref 呢?强制了之后就是range 呢? - 下节分享
- 总结:
在当优化limit x,x 。 添加索引是最好的方法,并发量大的时候还是会出现问题,我们应该从根本来解决问题。
如何解决呢?可以利用传参的形式来优化,因为limit x,x MySQL是不知道从哪里开始,是需要从头开始扫描,直到符合lit的位置进行返回来。
解决方法:
1.create_tble
2.主键



时间: 2024-08-03 16:51:27