本文假设你已经了解了Linux Container,CGroup和基本的Namespace概念。
User Namespace是Linux 3.8新增的一种namespace,用于隔离安全相关的标识和属性。使用了user namespace之后,进程在namespace内部和外部的uid/gid可以不一样,常用来实现这种效果:进程在namespace外面是一个普通用户,但是在namespace里是root(uid=0),也就是进程在这个namespace里拥有所有的权限,在namespace外面只有普通用户的权限了。
既然都是解决安全方面问题的,就不得不提另外两个Linux安全方面的功能,另外两个常用的是capabilities和LSM (Linux Security Module),其中capabilities和User Namespace关系密切。通过调用带CLONE_NEWUSER参数的clone方法创建的子进程,自动拥有新User Namespace里所有capabilities。另外,进程通过unshare创建一个新的User Namespace,或者通过setns加入一个已有的Namespace,都自动获取对应User Namespace里所有的capabilities。如果接下来进程通过execve启动了新程序,就要按照capabilities计算规则重新计算新进程的capabilities。
先看一个例子 (from http://coolshell.cn/articles/17029.html)
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mount.h>
#include <sys/capability.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int pipefd[2];
void set_map(char* file, int inside_id, int outside_id, int len) {
FILE* mapfd = fopen(file, "w");
if (NULL == mapfd) {
perror("open file error");
return;
}
fprintf(mapfd, "%d %d %d", inside_id, outside_id, len);
fclose(mapfd);
}
void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/uid_map", pid);
set_map(file, inside_id, outside_id, len);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/gid_map", pid);
set_map(file, inside_id, outside_id, len);
}
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n", getpid());
printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
/ 等待父进程通知后再往下执行(进程间的同步) /
char ch;
close(pipefd[1]);
read(pipefd[0], &ch, 1);
printf("Container [%5d] - setup hostname!\n", getpid());
//set hostname
sethostname("container",10);
//remount "/proc" to make sure the "top" and "ps" show container's information
mount("proc", "/proc", "proc", 0, NULL);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
const int gid=getgid(), uid=getuid();
printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
pipe(pipefd);
printf("Parent [%5d] - start a container!\n", getpid());
int container_pid = clone(container_main, container_stack+STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL);
printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid);
//To map the uid/gid,
// we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent
//The file format is
// ID-inside-ns ID-outside-ns length
//if no mapping,
// the uid will be taken from /proc/sys/kernel/overflowuid
// the gid will be taken from /proc/sys/kernel/overflowgid
(container_pid, 0, uid, 1);
set_gid_map(container_pid, 0, gid, 1);
printf("Parent [%5d] - user/group mapping done!\n", getpid());
/ 通知子进程 /
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
上面的例子创建了一个子进程,其中包含了UTS, PID, MOUNT和USER Namespace。编译并且运行上面的代码
gcc -Wall u.c
sudo /sbin/setcap all+eip a.out
./a.out
运行效果如下
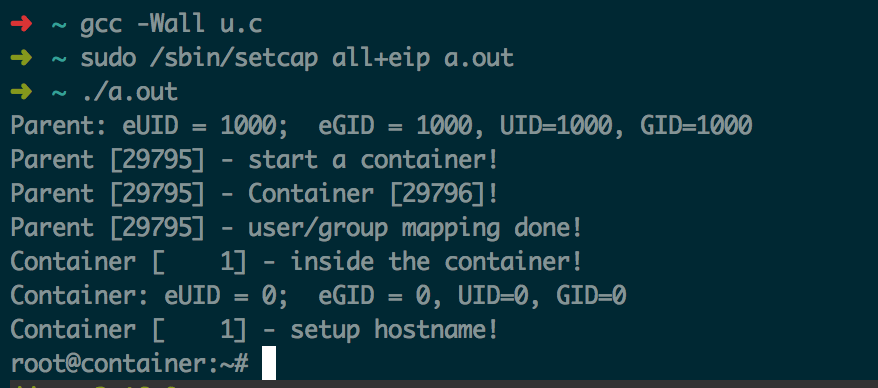
可以看到,在container内部已经是root了。非常神奇的是,原来uid=1000的文件,在container内部自动显示成uid=0,原来uid=0的,自动变成uid=65534 (nobody),很完美。
代码中关键的部分在set_uid_map中,要设置新创建User Namespace和Parent User Namespace(这里例子中是系统默认的Namespace)中uid和gid的映射,只要写进程对应的两个文件即可:
- /proc/PID/uid_map
- /proc/PID/gid_map
这里的PID是运行在User Namespace中的进程id。写入的格式是
id-inside-ns id-outside-ns length
- id-inside-ns: Namespace内部的uid/gid
- id-outside-ns: Namespace外部的uid/gid
- length 映射范围
有人可能主要到 上面的setcap操作,这一步也很关键,创建username也需要特定的capabilities才行,为了方便,这里直接设置为all
User Namespace In Docker
待续