摘要
本文介绍表格存储服务在优化Java SDK性能时的一些经验,作为一个支持海量数据、高并发访问的NoSQL服务,SDK的性能也显得尤为重要。SDK优化这项工作很久之前就已完成,现在将其中的一些经验再在公众号中与大家进行分享。
问题背景
用户通过Java SDK来访问表格存储,在SDK内部也是有开销的,在高并发的场景下这些开销尤其突出。如果SDK的性能很差,用户为了达到更高的QPS,可能就需要使用更高性能的机器或者更多的机器,从而增加用户使用表格存储的成本。我们对SDK进行性能分析,也发现了很多性能问题,可以说原来的SDK有很大的性能优化空间。在发现SDK性能不高之后,我们进行了一系列优化,其中最重要的改动是,使用HttpAsyncClient库替换了HttpClient,从而把同步IO替换成了异步IO,在高并发场景下性能有了显著提升。其他的一些优化,包括使用更高效的String处理方式、使用更高效的工具库、减少可复用对象的构造等,每一项优化对性能都有小幅提高。通过这一系列优化,我们把SDK的性能提升了数倍,在24核机器上,单行读写的QPS从1万多提升到了10万。
异步化
异步化是指使用异步IO替换同步IO来处理HTTP通信,具体来说,我们使用HttpAsyncClient替换了HttpClient(两者都是Apache下的开源项目),重构了SDK内部的处理逻辑,同时提供了同步和异步的接口。SDK提供的同步和异步接口形式是这样的,以GetRow为例:
同步接口:
GetRowResult getRow(GetRowRequest getRowRequest);
异步接口:
OTSFuture getRow(GetRowRequest getRowRequest, OTSCallback callback);
异步接口提供了otsCallback参数并返回otsFuture。用户可以设定otsCallback的onCompleted和onFailed方法,SDK会在请求成功或失败后执行相应的方法。用户也可以调用otsFuture的isDone方法询问请求是否完成,或者调用get方法阻塞的返回请求结果。
为什么要使用异步IO
在同步IO时,一个线程对应一个连接,在该连接上构造请求、发送(blocking)、等待服务端返回(blocking)、接收响应(blocking)、解析并返回结果。对于表格存储服务而言,每个请求的大小是比较小的,相应的就要求QPS能达到比较高的值。以5000QPS为例,假设每个请求的延时为5ms,即1个连接上1秒可以处理200个请求,达到5000QPS就需要25个连接,对应25个线程。如果要求的QPS大于5000,或者每个请求的延时更高,则需要更多的线程,事实上当线程增加时每个请求在SDK端的延时可能也会增加。几十个或上百个的线程会带来频繁的线程切换的开销,同时每个线程都在处理HTTP通信,这个效率也是比较低的。
针对上述场景,使用HttpAsyncClient是非常合适的优化方案,它适合的应用场景就是大量连接、高并发请求的情况。HttpAsyncClient使用了基于Reactor模式的NIO,只用很少的线程(通常每个核一个),对所有的IO事件进行响应,分发到对应的IO会话中。因此不再是以往一个线程对应一个连接的模式了,所有连接和HTTP通信都由HttpAsyncClient管理,其维护着少量的IOReactor线程。
需要格外说明的是,HttpAsyncClient要比HttpClient的性能更好,底层异步化后,即使上层仍是使用同步接口(把异步接口包装成同步接口),也比之前使用HttpClient时性能好很多。即使用异步IO并非仅仅为了提供异步接口,它也可以使整体性能大大提高。
SDK使用异步IO的方式
不管用户是调用SDK的同步接口还是异步接口,该用户线程都要构造出对应的HTTP请求,交给HttpAsyncClient。除了HTTP请求外,SDK还会将consumer(解析HTTP响应)和callback(在consumer之后执行)提交给HttpAsyncClient:
httpAsyncClient.execute(requestProducer, responseConsumer, callback);
具体的consumer和callback都是SDK内部构造的,consumer用于把HTTP响应解析成对应API的结果,如GetRowResult、PutRowResult等,每个api对应一个consumer。callback用于控制一次请求成功或失败后的处理流程,主要涉及重试相关逻辑。因为SDK支持可自定义的重试策略,用户的一次调用可能包含多次的HTTP请求,除第一次外的每次请求都是由callback的failed方法发起的(将该请求提交到一个ScheduledExecutorService中)。
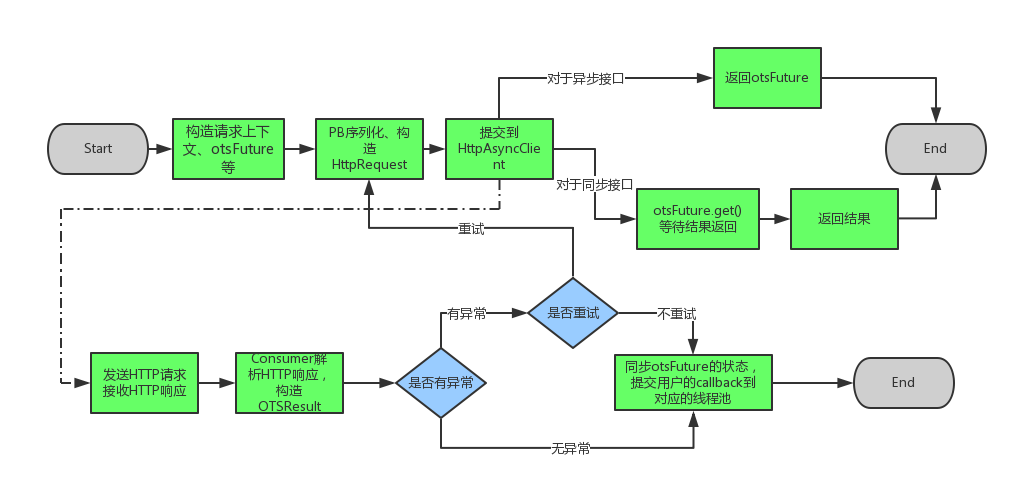
前面提过,用户可以指定的otsCallback,SDK会返回给用户otsFuture,在一次调用完成后会对这两者进行处理。首先,用户调用一次SDK的接口,完成的条件是请求执行成功(无论是否重试过)或者请求执行失败(不需要重试或重试次数耗尽),这个条件的判断是在上述提交给HttpAsyncClient的callback中完成的。一旦一次调用完成(成功或失败),SDK就会同步对应的otsFuture的状态,唤醒blocking在这个otsFuture的get方法中的进程,并将用户指定的otsCallback提交到执行所有otsCallback的线程池中。总之,otsFuture和otsCallback对用户而言都是针对一次调用的,这一次调用中可能包含多次HTTP请求,每次的HTTP响应是通过SDK内部构造的consumer和callback处理的。
SDK的同步接口是对异步接口的包装,与异步接口类似,同步接口也会构造一个otsFuture,只是并不返回otsFuture,而是返回otsFuture.get()。即前面的操作与异步接口相同,只是最后blocking在get方法里等待结果返回。
在性能测试中看到,极限压力下,同步接口的性能只比异步接口低10%左右,相比原来SDK的同步接口,性能提升了数倍。这主要是由于优化后,同步接口和异步接口的底层都是异步IO,在极限压力下,同步接口的缺点是使用了几百个线程,虽然带来了线程切换的开销,但实际处理网络IO的线程是很少的,整体性能下降并不很大。
其他的性能优化项
- 取消了对参数命名的检查:
原来SDK对表名、列名等都做了命名规则检查,实现上使用了String.matches匹配正则表达式,这个性能很低,当列数较多时对性能的影响比较大。因为服务端也要做这个检查,而且大部分情况下用户的命名不会出错,所以去掉了这个检查。 - 减少URI对象的构造:
原来SDK对每次请求都会构造一个URI对象,现在将每个API默认的URI对象保存下来,作为类的成员变量,减少了重复的URI对象的构造。 - 简化HTTP请求的构造流程:
简化了HTTP请求的构造流程,减少了对象间的转换。 - 用Joda Time替换 Java的日期处理:
Java的日期处理性能很差,改用Joda Time进行日期时间的处理。 - 改善MD5在高并发下的性能:
之前每次计算MD5的时候都要调用MessageDegist .getInstance(“MD5”),这里有锁,高并发场景下会影响性能。现在使用prototype模式,每次clone一个对象,避免了锁的问题。 - 在HttpAsyncClient里禁用了cookie:
HttpAsyncClient在处理cookie上会有一些开销,由于我们不需要使用cookie,所以在配置HttpAsyncClient的时候就将cookie禁用了。 - base64的decode/encode采用javaxml的实现:
Apache codec的base64实现效率并不高,改用javaxml的实现。
http://java-performance.info/base64-encoding-and-decoding-performance/ - 减少格式化时间的次数:
保存当前时间的Rfc822格式的字符串,每秒更新一次。 - 设置是否开启响应验证的开关:
默认开启响应验证,会验证头信息完整性、结果是否过期、授权信息是否正确。用户可以选择关闭这一验证,可以显著提高性能。 - 不对header执行String.tolowercase:
原来所有header都插入了一个CaseInsensitiveMap ,里面会对所有header的name执行tolowercase。这个影响性能,而且没有必要,SDK实现上保证了所有header的name都是小写。
增加Logger和Tracer
SDK为每个请求生成了一个traceId,是一个uuid,该traceId也会传递到服务端,用于标识该请求。在以下几种情况下SDK会打印日志,日志中带有traceId信息。
1. 在一次请求的不同阶段打印日志:
SDK会记录每个请求在刚开始执行、HTTP请求的发送与接收、开始重试、完成等阶段的时间,同时会在每个阶段打印一条debug级别的日志。在protobuf序列化完成后,SDK也会打印一条debug级别的日志,包含protobuf的内容。
2. 打印错误日志:
每次HTTP请求完成后,如果返回错误,SDK会打印一条error级别的日志。
3. 记录请求的执行时间,打印慢请求的日志:
SDK记录了一个请求在各阶段的时间,在请求完成时,判断该请求的总执行时间是否超出了一个可自定义的阈值,如果超过了该值,会打印一条warn级别的日志,包含该请求在各个阶段的时间戳。
优化后性能指标
- 在24核单机上进行性能测试,连接真实的服务端,测试能达到的最高QPS,主要指标如下:
- 单行读写,每行10列属性列,每列10~20byte。
- 异步接口:
QPS:100K CPU:95%
此时CPU已经达到极限,网络未打满,流量在90M左右。 - 同步接口(400线程):
QPS:90K CPU:92%
同步接口能达到的最高QPS比异步低10%左右,此时创建了400个线程调用同步接口,线程切换的开销较大。
- 异步接口:
- batch读写或GetRange,每次10行,每行10列,每列10~20byte。
- 异步接口:
QPS:50K CPU:85%
此时网络流量在200M以上,已经被打满。 - 同步接口(400线程):
QPS:35K CPU:58%
可以看到这里同步比异步的QPS低了很多,主要是由于此时同步接口测试的并发度比异步低。同步接口创建了400个线程最大只有400并发,而异步接口并发只受最大连接数限制,使用少量的线程就可以达到更高的并发。测试时batch操作的延时在10ms以上,所以结果也是符合预期的。
- 异步接口:
- 单行读写,每行10列属性列,每列10~20byte。
- 单独测试请求构造部分,在进入HttpAsyncClient处返回,不实际进行http请求。测试PutRow接口,每行3列主键列,10列属性列,每列10byte。
- 单线程:
QPS:33K - 15个线程(24核机器):
QPS:450K
线程数多于15个时,单个线程的效率明显下降,分析主要原因是小对象过多,对整体性能有较大影响。
- 单线程:
用户应该如何使用Java SDK
1.需要创建几个OTSClient?如何配置?
OTSClient(或OTSClientAsync)的接口都是线程安全的,支持多线程同时调用,因此一般情况下,只需要创建一个OTSClient即可。如果要求的QPS非常高,当只使用一个OTSClient时,可能会遇到性能瓶颈,这时使用多个OTSClient,可以提高整体的QPS。在我们的测试中,使用24核机器,单行操作每行不超过1kb的情况下,一个OTSClient的瓶颈大约在40K QPS左右。所以如果用户发现在CPU、网络未达到瓶颈之前,使用一个OTSClient难以继续提高性能时,可以尝试使用多个OTSClient。
OTSClient在创建时可以传入一个ClientConfiguration,里面有两个配置是跟性能密切相关的,分别是ioThreadCount和maxConnections。ioThreadCount配置的是该OTSClient可以使用的IOReactor的线程数,默认是CPU的核心数。一般而言,当只使用一个OTSClient时,使用默认值即可,如果同时使用多个OTSClient,可能要将每个OTSClient的ioThreadCount值调小,以减少整体的线程数。maxConnections配置的是该OTSClient内连接池的最大连接数,该值限制了OTSClient与OTS服务端的最大并发度。该值是可以估算的,maxConnections = maxQPS * latency,以maxQPS = 10 K,latency = 0.01s为例,maxConnections = 10K * 0.01 = 100,即需要100个连接。
在使用完OTSClient后,需要调用其shutdown方法,关闭它所使用的一些线程资源。
2.同步接口的使用方式和优缺点:
SDK的同步接口直接返回对应请求的结果,比如GetRow操作,会返回GetRowResult类型的结果。使用同步接口时,最大并发度=min(线程数,最大连接数)。一般情况下,最大连接数配置的是比线程数多的,所以主要是由线程数决定并发度。使用同步接口的方式很简单,直接调用OTSClient的接口即可。值得注意的是一个OTSClient可以被多个线程并发的调用,不需要每个线程一个OTSClient。一般情况下,全局使用一个OTSClient即可。
同步接口的优点是使用方式简单、不会产生请求堆积,且通过线程数可以控制并发度。其缺点是同步接口依赖线程提高并发,因此在高并发场景下需要使用非常多的线程,会带来频繁的线程切换的开销。特别是当由于网络或者服务端的原因使得请求的延时增加时,就需要更多的线程来提高并发,维持QPS。
3.异步接口的使用方式和优缺点:
使用SDK的异步接口需要创建一个OTSClientAsync对象,并调用其提供的异步接口。每个异步接口都支持传入一个OTSCallback类型的callback,用户可以定义该对象的onCompleted方法和onFailed方法,这些方法会在请求执行成功或失败后执行。在创建OTSClientAsync时,用户可以指定一个ExecutorService用于执行上述的callback,如果不指定,SDK会默认创建一个线程数与CPU核心数相同的ExecutorService来执行callback。除了可以指定callback外,异步接口会返回OTSFuture类型的future。该future提供isDone方法和get方法,isDone方法立即返回请求是否完成,get方法阻塞的返回请求结果,该方法也支持传入一个超时时间。
使用异步接口的优点是可以达到更高的性能,不需要创建非常多的线程来提高并发,使用方式也非常灵活。但其一个缺点是需要避免请求堆积在OTSClientAsync内,如果调用OTSClientAsync发送请求的速度超过了其处理速度,请求就会堆积,堆积会导致进程内存不断上涨以及频繁GC。所以如果要在大压力下使用异步接口,建议在SDK上层进行流控。
结语
表格存储的 Java SDK从最初的1万多QPS优化到10万,可以看到优化的空间是非常大的。异步化是整个优化过程中最重要的一步,异步化之外有两个优化方向,一方面是减少多线程竞争,另一方面就是降CPU,减少计算。在这个过程中,一些Java性能分析工具也起到了很关键的作用,暴露了一些性能热点。