自动驾驶汽车过去只出现在科幻作品中,而现在似乎已经离我们近在咫尺,这得益于近年来计算机视觉、机器学习等技术的高速发展以及计算机硬件处理能力的飞速提升。在这些新技术中,计算机视觉技术的进步对自动驾驶领域起到了极其重要的作用。今天,我们以回顾ICCV2015主题报告的形式为大家简要介绍究竟有哪些计算机视觉技术应用到了自动驾驶领域。
2015年,在计算机视觉领域中的顶级会议ICCV中,组委会针对自动驾驶专题,邀请了来自戴姆勒、丰田、牛津大学、博世公司等世界顶级研究者做了主题报告。下面为大家推荐这次主题报告的网站:https://sites.google.com/site/cvadtutorial15/materials
(其中包括了演讲人的PPT,内容非常充实,有很多他们推荐的种子文章,感兴趣的同学可以参考)
下面简要介绍一下这次主题报告的框架和大致内容,主要分为8个部分:
1) 自动驾驶领域的简要介绍:
自动驾驶的需求,现在分为5个自动化程度等级的定义,简要发展史。随后提出了自动驾驶的基本问题,即:(1)车在哪?(2)车周围有什么?(3)下面会发生什么?(4)车该怎么做?有了这些基本问题,计算机视觉能帮助我们解决什么呢?比如:检测路牌,和周围的车辆展开互动,了解周围发生了什么等等。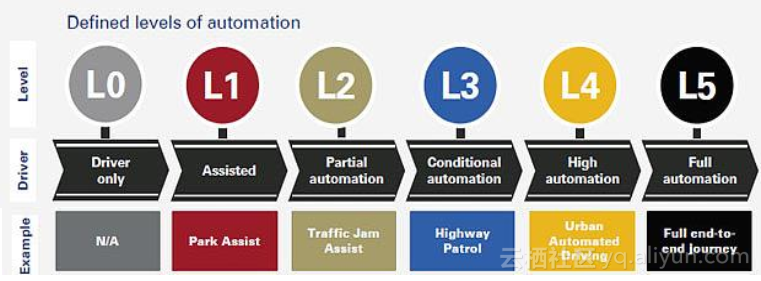
2)双目视觉在自动驾驶中的应用:
由于双目视觉能够获得dense的三维信息,图像可以获得“语意”信息(理解图像哪部分是什么,比如:“公路”,“树丛”等等),而且双目视觉的准确性和鲁棒性优秀,所以被使用在自动驾驶领域。随后,主讲人介绍了双目视觉的原理,在自动驾驶领域中的发展历程。之后,详细介绍了所在的戴姆勒公司所用的一些技术,包括:(1)stixel对真实世界进行“语意”表达;(2)利用卡尔曼滤波进行汽车并线的方法;(3)基于深度学习的物体归类方法; (4)基于CNN的交通灯检测。最后,演讲人列举了一些目前的技术挑战。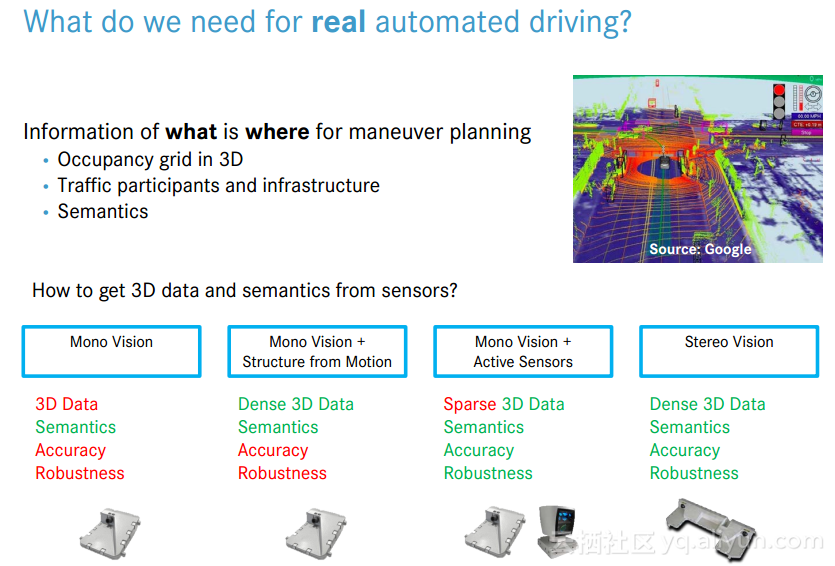
3)多传感器融合在自动驾驶中的应用:
由于自动驾驶对可靠性的要求,而不同传感器的优势又各不相同,所以被用作不同功能。这些传感器包括但不限于:定位系统(GPS, 惯导系统等),3D激光雷达,雷达和相机。演讲者首先介绍了他们(丰田)整个环境感知系统的架构以及每个传感器可能的用途,随后着重介绍了基于视觉的跟踪和传统跟踪方法的异同,以及如何进行数据融合的方法。
4)基于“语意”的环境理解:
首先介绍了几组通过“语意”进行环境理解的数据集,然后按由低到高的顺序,从像素级语意分类,到基于区域的分类,最后到利用深度学习的“语意”分类进行逐步深入的介绍。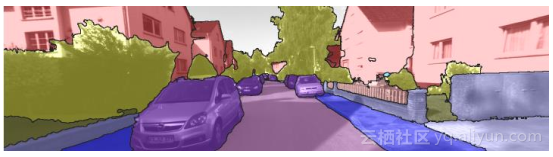
5)机器人为环境自动建图:
将建图过程分为两部分分别介绍:(1)相机相对姿态的确定;(2)全局相机姿态的优化。将第(1)部分又拆解为5步完成,即:特征点检测->特征点匹配->特征点跟踪->飞值检测和剔除->利用有效数据的最优化求解。第(2)部分则介绍了相机姿态基于图论的全局最优化方法,包括常见的闭环检测等。
6)自动驾驶中的定位问题:
首先阐述了定位在自动驾驶中的重要性。然后顺序介绍了基于标志物(如:车道,信号灯等)的定位,传感器融合进行定位,以及如何利用GPS进行粗初始化定位的方法。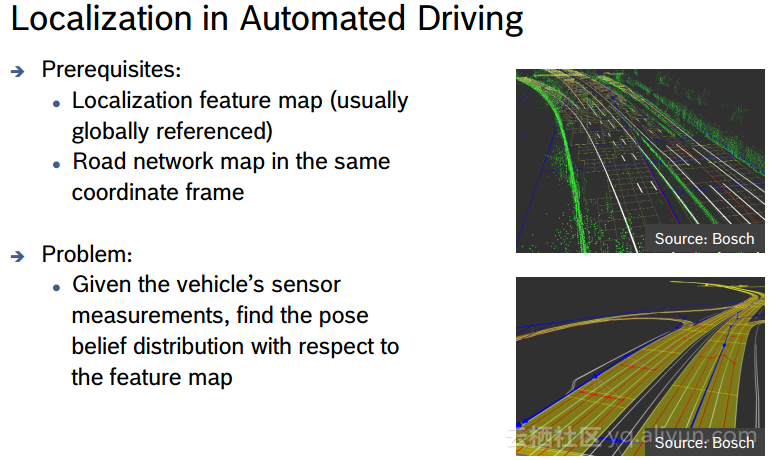
7)相机与其他传感器的时空信息融合:
首先介绍了相机内参的标定工具,然后介绍了相机外参的校正、多传感器的时钟同步、多传感器间的空间校准以及利用特定传感器pair进行特定功能的解决方案。最后,演讲人介绍了其主题在汽车领域的应用。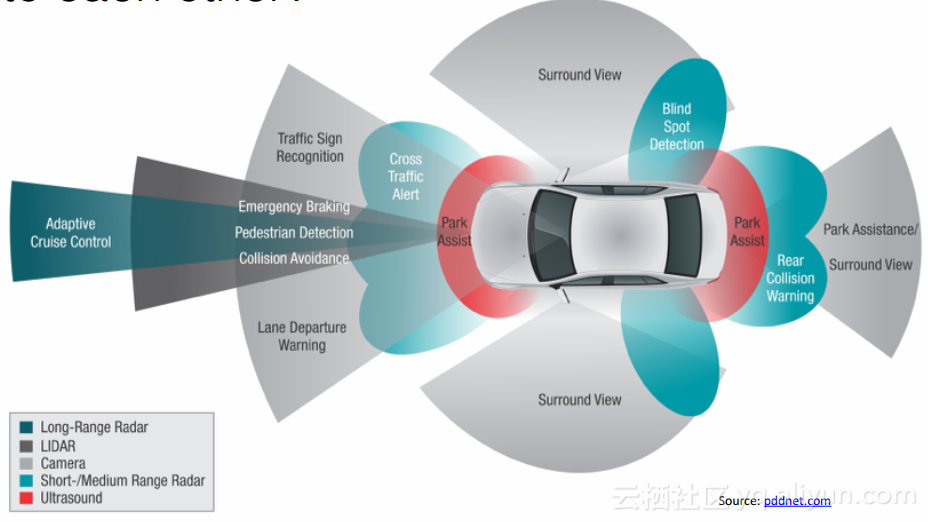
8)NVIDIA深度学习平台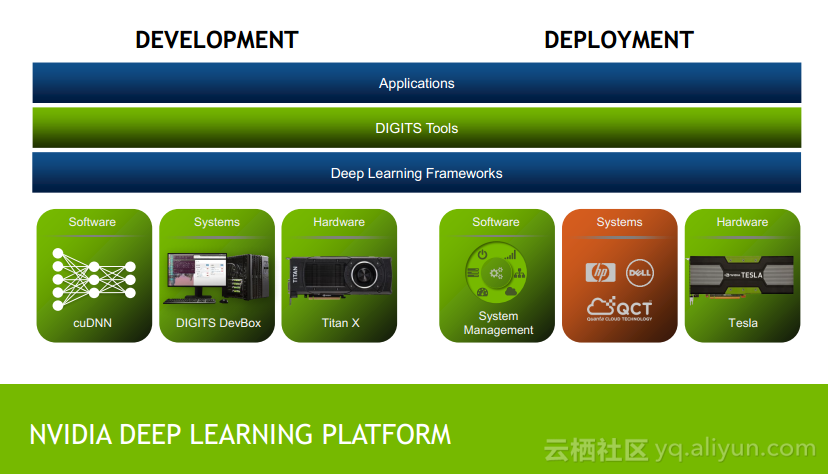
以上是对这次主题报告的粗略总结,水平有限,如有错误还望指正,谢谢~