1.3 Amdahl定律及其扩展
绘制任务运行时间,可以看到并行增加应用程序的扩展行为。并行计算的理论性能:运行在有N个处理单元的并行计算机上,理论上可以获得N倍加速。换一句话说,一个程序运行在10核处理器上可能获得10倍加速(对于固定大小的问题),在支持1000个并发执行线程的GPU上获得1000倍加速。开发人员依据Amdahl定律来讨论并行与串行间的加速比。
用计算机架构师Gene Amdahl来命名Amdahl定律。它不是实际上的定律,但是修改串行程序使其并行执行时,它相当接近模型理论加速比。为使这个近似值有效,在并行化时有必要保持问题规模相同,通常称为强扩展。换句话说,假定修改串行程序使其并行执行,在并行版本代码中程序执行的工作量并没有显著地变化。显然,并行部分可能运行得更快,这取决于硬件能力。因此,使用N个处理器,串行代码并行执行期望的加速比S(N)由程序可并行比例P和不可并行比例(1―P)决定。公式(1-1)显示了这种关系: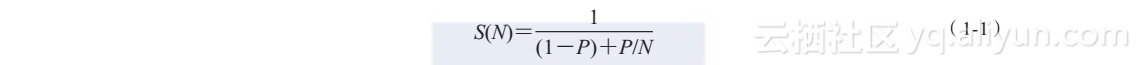
Amdahl定律告诉OpenACC开发人员在并行化程序时有两个目标:
1.表达代码并行部分,使其尽可能快地执行。理想情况下,使用N个处理器有N倍加速。
2.利用任何的技术或手段来减少1―P串行时间。
并行部分代码执行很快使得程序运行时间主要由串行部分代码占据,这是有可能的。这是计算机架构师将强大的顺序处理器(如CPU)与并行处理器和协处理器混合使用的原因之一。
理论上通过增加计数器,accTask.cpp忙工作的任务示例将在所有OpenACC设备上全速运行,因为它被设计成100%计算限制,意味着处理器是限制性能的系统组件。实际应用中通常要复杂很多,其性能可能受到存储器和网络带宽之类的其他因素影响。随着并行性的增加,许多并行应用程序的性能受到限制,因为它们严重依赖于存储器中的数据。因而增加更多的处理单元并不会提高性能,并且可能损失性能,处理单元大部分时间消耗在等待数据上。accFill_ex1.cpp和accFill_ex2.cpp示例都是存储器瓶颈,意味着存储子系统的性能限制了程序性能。
计算机架构的缓存可以帮忙提高性能,在高速缓存存储器中预取和存放经常访问的或热点数据。这就是并行编程人员对局部性和流行为很感兴趣的原因。利用高数据局部性的程序通常运行得更快,因为它们可以用完寄存器或缓冲存储器。accTask.cpp示例就是一个例子,它使用一个寄存器并且在忙循环中没有其他的内存取操作。将数据流出存储器的程序也往往运行得更快,因此数据可以被预取到更快的高速缓冲存储器中。理想情况下,流程序完全不受存储子系统限制,呈现很好的扩展性。局部性和流行为的关键是对每个取出的数据项执行足够的计算来隐藏存储器事务的开销。从内存,跨网络,数据仓库或跨PCI总线取数据时,这点依旧成立。
1.3.1 大O表示法和数据传输
大O表示法是一个方便的方式来描述问题规模如何影响算法某些资源的消耗,例如处理器时间或存储器作为算法输入的函数。通过这种方式,计算科学家可以描述算法的最坏和平均情况运行时行为。可以用大O描述法来比较算法,以帮助理解并行算法的类型。哪些算法可能对每个取出的数据项表现出高计算性,确定适合OpenACC编程的算法。
一些常见的大O增长率如下所示:
O(1):常量时间(或空间)算法,不管输入集合大小始终消耗相同资源。例如,索引向量中的单个元素不随时间或数据集的大小而变化,因此表现出O(1)运行时增长。
O(N):算法资源消耗随着输入问题规模N而线性增长。这对于循环数据集(大小为N)的算法是常见的,其中循环内的工作需要的时间是恒定的。
O(N2):性能与输入数据集大小的平方成正比。典型示例是在输入数据集上使用嵌套循环的算法,表现出O(N2)运行时。深层嵌套迭代通常显示更大的运行时(例如,三层循环导致O(N3),四层循环导致O(N4),依次类推)。
有很多优秀的算法分析书籍,更精确和全面地讲解了大O表示法。其中最流行的一本书籍是<<算法导论>>(Cormen, Leiserson, & Rivest, 2009)。在网络上也有许多谈论和讲授大O表示法和算法分析的资源。
大多数计算领域的科学家和程序员都熟悉BLAS(基本线性代数子程序)库。BLAS是基本线性代数实际上的编程接口。为了保持竞争力,多数处理器供应商提供高度优化的BLAS库。也可使用强大的异构高性能稠密线程代数库,例如田纳西大学创新计算实验室的MAGMA项目。异构计算使用主机处理器(CPU)和很多OpenACC设备类型的计算能力。MAGMA通过使用所有的系统计算能力来获得高性能。MAGMA目前可以免费下载。
根据三个不同的级别,随着数据和运行时需求的增加而构建BLAS。
级别1:需要O(N)数据和O(N)任务的向量-向量操作。例如计算两个向量的内积,或通过常数乘法器缩放向量。
级别2:需要O(N2)数据和O(N2)任务的矩阵-向量操作。例如矩阵-向量乘法,或单个右手三角求解。
级别3:需要O(N2)数据和O(N3)任务的矩阵-向量操作,例如稠密矩阵-矩阵乘法。
假定从主机向OpenACC设备传输N个浮点数值,表1-1说明了每个BLAS级别所要执行的全部任务。
可以看出级别3的BLAS操作应该高效执行,因为对于传输到OpenACC并行设备的每个浮点值执行O(N)任务。任务/数据的分析同样也能应用于非BLAS相关的计算问题。
为了实现高性能需要尽量把数据保存在OpenACC设备和离处理器近的缓冲存储器上,这点是很明确的。在这之后,为了获得高性能需要对每个数据执行尽可能多的计算,就像级别3的BLAS操作。创建一个有许多低算术密度计算的流水线有助于提高性能,但是只有当每个操作使得OpenACC设备足够忙碌,以至可以隐藏任何设备启动延时时,才能提高性能。或者,结合多个例如级别1和级别2 BLAS操作的低密度操作,可能会(有时会显著地)提高性能。Kernel子句可以帮助做到这一点。
之前讨论的可以总结出关于异构模型编程的三条规则:
在OpenACC设备上获取数据并且把数据保存在设备上。
这将尽可能地减少或消除数据传输开销。特别地,OpenACC编程人员应该学习使用present()子句和条件数据传输子句(例如present_or_copy())。当程序运行在共享内存设备(例如多核CPU)上时,允许OpenACC运行时消除数据传输。
给OpenACC设备执行足够多的任务。
快速运行并行代码段的一个挑战是OpenACC设备的启动时间大于或等于运行时间。记住大多数现代OpenACC处理器能够实现多个TF/s(兆浮点/秒)性能。基本上应用程序必须每微秒执行1百万次操作才可以抵消在这些设备上启动并行代码段的开销。
注意数据重用以避免存储器带宽限制。
正如之前讨论的,针对高局部性的数据重用的编程,意味着编译器和硬件可以把
数据保存在最高性能的寄存器和高速缓冲存储器中。OpenACC编译器还可以帮助优化寄存器复用和预取。同样,present_and_*子句可以复用已经传输到设备的数据。
1.3.2 accTask.cpp代码的扩展性
如前所述,accTask.cpp代码被设计为具有极高的局部性参考。实际上,这个代码使用一个寄存器变量,并且没有明显的存储器性能依赖。图1-11显示了在x86 CPU上accTask.cpp单线程版本的运行时间。
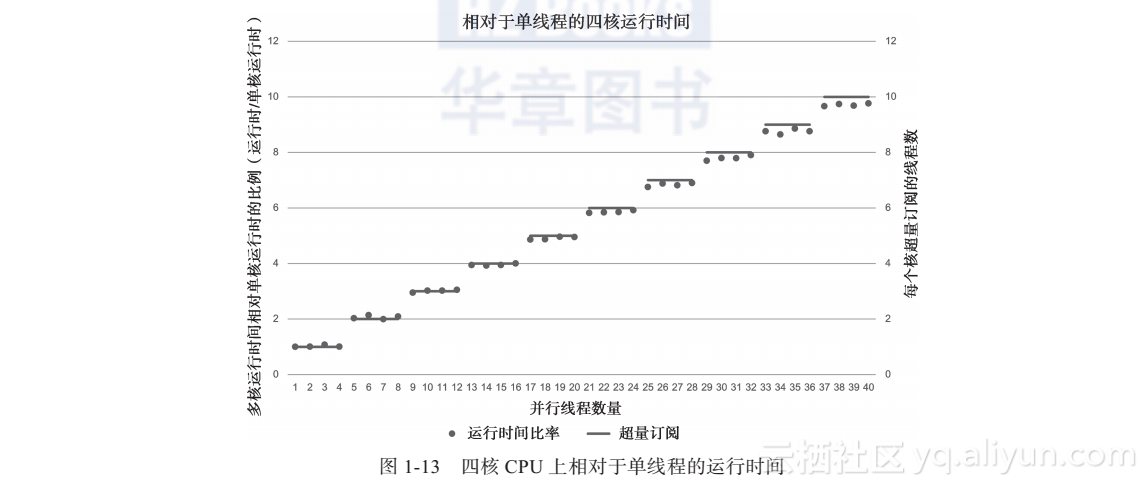
请注意,单线程任务串行执行4个任务时,在Intel四核E5630 2.53GHz的系统上需要大约4倍的单任务时间(如57.4627/14.5115=3.95)。这个比例是近似值,因为在时间测量中存在一些粒度。

使用bash脚本(如图1-12所示)来生成运行时间表,可用来查看运行时间与核数的关系。

图1-13阐明了一个运行时间相对于基于核数的单线程值的阶梯模式。换句话说,如果每个核超量订阅相同数量的任务,运行时间是相同的。例如,硬件核超量订阅2倍任务,运行时间是单线程时间的2倍。继续订阅超过处理核数的任务,依旧可以清楚地看到这个行为。
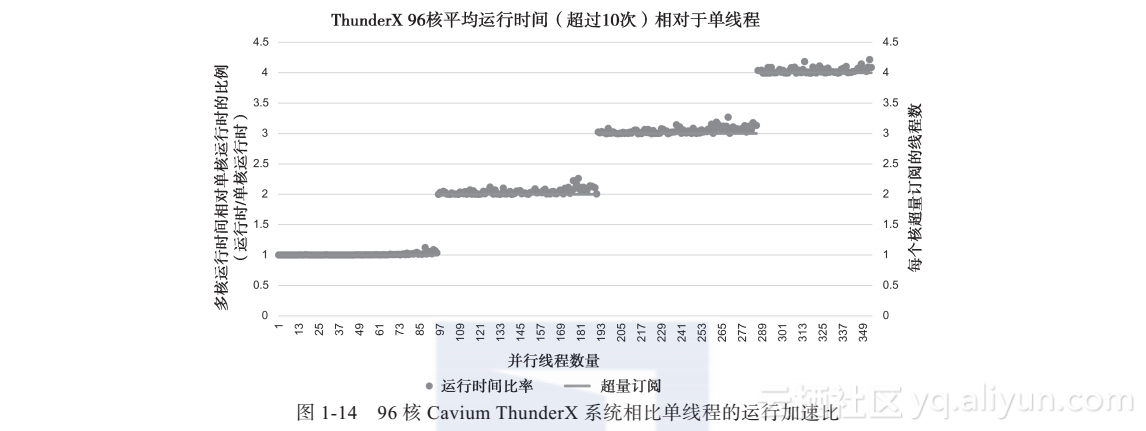
如图1-14所示,使用PathScale Enzo OpenACC编译器编译运行在96核Cavium Thun-derX ARM64系统上的可执行文件,也可以看到类似的扩展性。