1、准备集群搭建环境
使用6台虚拟机来搭建MySQL分布式集群,相应的实验环境与对应的MySQL节点之间的对应关系如下图所示: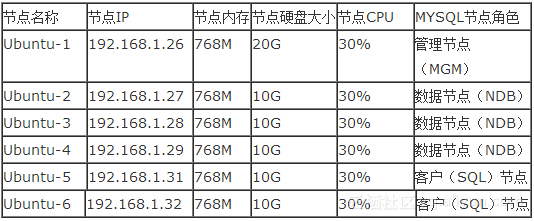
管理节点(MGM):这类节点的作用是管理MySQLCluster内的其他节点,如提供配置数据,并停止节点,运行备份等。由于这类节点负责管理其他节点的配置,应该在启动其他节点之前启动这类节点。MGM节点是用命令“ndb_mgmd”启动的;
数据节点(NDB):这类节点用于保存Cluster的数据,数据节点的数目与副本的数目相关,是片段的倍数。例如,对于两个副本,每个副本有两个片段,那么就有4个数据节点,没有必要设定过多的副本,在NDB中数据会尽量的保存在内存中。数据节点使用命令“ndb”启动的;
SQL节点:这是用来访问Cluster数据的节点,对于MySQL Cluster,客户端节点是使用NDB Cluster存储引擎的传统MySQL服务器。通常,SQL节点使用命令“mysqld-ndbcluster”启动的;
2、准备安装包
在官网上下载mysql的安装包: mysql-cluster-gpl-7.4.11-Linux-glibc2.5-x86_64.tar.gz,并进行解压。
3、集群搭建流程
1]将上述安装包解压出来的文件都移到/usr/local/mysql下;
2]运行script目录下的mysql-install-db.sh脚本,运行命令为./mysql-install-db.sh --user=root--basedir =/usr/local/mysql --datadir=/usr/local/mysql;注意其中用户为root的名称需要跟配置文件my.cnf中的相同;
在管理节点,数据节点,SQL节点上都执行上述安装命令,从而完成对mysql的安装;
4、集群配置与启动
1]在管理节点上需要完成对于集群整体的配置配置:在/var/lib/mysql-cluster/config.ini中实现如下的配置信息: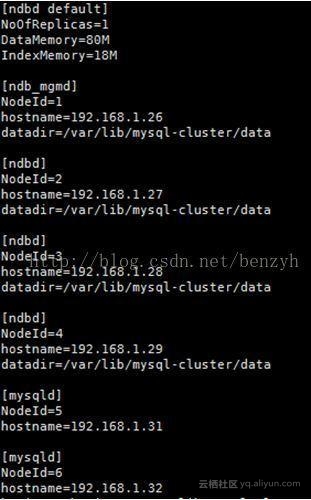
2]在数据节点中需要在my.cnf中完成对于数据节点的相关配置信息,如下: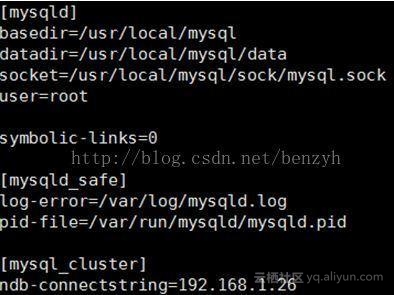
需要指明配置的数据节点的根目录,数据目录,socket连接配置,用户配置,以及对应的管理节点的ip地址配置;将配置完成的配置文件移动到/etc/my.cnf,完成;
3]在SQL节点上完成对于SQL节点的配置信息,同样的是在my.cnf中完成相应配置信息,并将配置文件移动到/etc/my.cnf中,相应的配置信息的设定如下所示: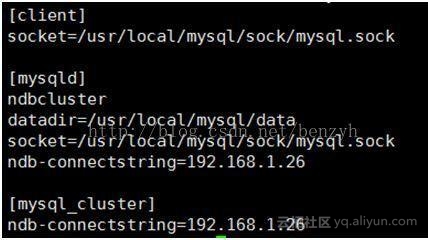
完成以上配置后,就可以启动集群中的各个节点了。
5、集群启动
在启动mysql集群的时候,注意首先要启动管理节点,并依次启动其他等若干个节点,相应的启动步骤如下:
1]在管理节点上,切换到/usr/local/mysql/bin目录下,执行ndb_mgmd -f /var/lib/mysql-cluster/config.ini命令,完成管理节点的启动;
2]在各个数据节点上,切换到/usr/local/mysql/bin目录下,执行ndbd --initial(第一次启动时,否则执行ndbd即可),完成对数据节点的启动;
3]在各个SQL节点上,同样切换到/usr/local/mysql/bin目录下,执行mysqld_safe --user=root完成启动;
4]在管理节点上运行ndb_mgm命令,进入数据库管理的客户端,输入show命令,查看与之相连接的各个节点的状态;
5]在SQL节点上分别进入系统的安全状态,并完成对root用户的密码修改,运行以下指令,进行密码修改:
A use mysql,切换到mysql数据库;
B UPDATE user SET Password = PASSWORD('123456')WHERE user = 'root';从而实现对root密码的修改;
C flush privilege,完成修改;
6]修改使得任意主机都能连得上mysql,进行如下修改,同样安装第5步进入安全模式,并完成相应的修改,如下:
grant all on‘.’to ‘root@'%' identified by '123456';
这样就可以使得任意一个主机都可以通过root用户来登录mysql了;
6、集群测试
在集群上的一个SQL节点上执行创建数据库,并创建一张表,并完成相应的数据插入,如下:
A create database ctest; //创建数据库
B create table test(
id int primarykey; //创建一张表
);
C insert into test (id)values(1); //完成数据插入
登录另外一个SQL节点,并执行SQL查询操作,看数据库中是否已经有数据,如下:
select * from ctest;
如果有数据,表示数据插入成功;
7、关闭集群
1]首先关闭管理节点和数据节点,需要在管理节点上执行命令,如下:./ndb_mgm -e shutdown;
2]然后关闭SQL节点,在SQL节点上执行命令/usr/local/mysql/support-fies/mysql.server stop(其中/usr/local/mysql/是mysql的安装目录).从而关闭SQL节点;