2.3 直接映射高速缓存
最简单的高速缓存组织就是直接映射(direct mapped)或者单路组相联(one-way set associative)高速缓存(短语“单路组相联”的意思在下一节介绍“双路组相联”的时候就清楚了)。TI MicroSPARC的片上数据高速缓存使用的就是这种高速缓存组织。它包含有2 KB的数据高速缓存,组织成128个高速缓存行,每行16字节。在如图2-5所示的这种类型的高速缓存中,在保存数据的部分高速缓存里,以散列算法用地址计算出每行有且仅有的一个索引(也就是说,直接映射关系)。高速缓存可以当作是高速缓存行的线性数组,这些行都以散列算法计算得出的结果作为索引。在搜索期间,索引行中的标记要和地址进行比较以发现是否命中。因此,单有索引还是不够的,因为采用任何类型的散列算法都会有许多不同地址计算出相同的索引结果。在出现一次命中的时候,就从高速缓存行中提取数据,送往CPU。如果标记和地址不匹配,或者有效位没有打开(要记住有效位是和地址一起保存在标记中的控制信息),那么就出现一次缺失,因为在直接映射的高速缓存中,这是能够保存数据的唯一位置。因此没有必要进一步搜索高速缓存。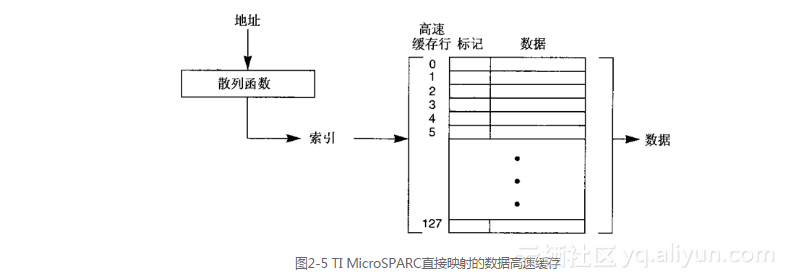
使用直接映射高速缓存机制的其他处理器有Intel Pentium,它用于其外部高速缓存,以及MIPS R2000/R3000/R4000所支持的所有高速缓存。
2.3.1 直接映射高速缓存的散列算法
直接映射高速缓存的高速缓存散列算法必须将一个来自CPU的给定地址转换为高速缓存中一行的索引值。因为散列算法的计算是在硬件中完成的,所以它必须既简单,速度又快。对于降低成本和获得快速实现来说,简单性是必不可少的。速度非常重要,因为需要索引在适当的高速缓存行上启动读取周期。在比较高速缓存标记,查明是否有一次命中之前,必须完成上面所有的步骤。由于有这些限制因素,所以在高速缓存中使用的散列算法很少会采用算术运算,因为这些操作会花费很长的时间。
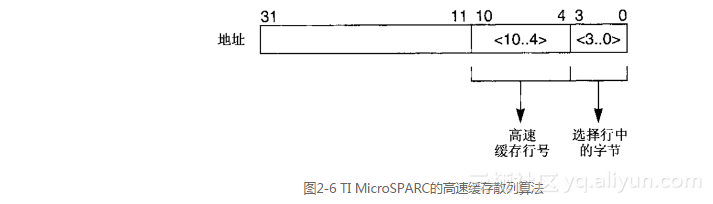
最常用的高速缓存散列算法是取模(modulo)函数,这种函数利用了这样的事实,即在直接映射高速缓存中的行数往往是2的幂。这就使得散列算法只要从地址中选出若干位,选出的位数正好等于高速缓存行数以2为底的对数,就能直接用它们来作为索引。例如,考虑TI MicroSPARC上的数据高速缓存,它有128(27)行,每行16字节。这个配置的散列算法应当从地址中选出“位<10..4>”(从第4到第10个位),使用这7个位从高速缓存的128行中选出一行(参见图2-6)。因为每一行高速缓存有16字节,所以该地址的低4位将选择CPU寻址的高速缓存行中的若干字节。因为高速缓存总共有2 KB,所以我们能够看到这种选择索引的方法会让所有模2048的地址都索引到高速缓存中相同的行(所有和“位<10..4>”匹配的地址都生成相同的索引)。这叫做取模散列算法(modulo hashing algorithm)。
此外,产生相同索引的地址被认为有相同的颜色。如果一个高速缓存的大小是页面大小的倍数,则该高速缓存就被认为其颜色和高速缓存中的页数一样多。如果一组存储页面的地址散列到高速缓存内同一组的高速缓存行上,那么称这组存储页面有相同的颜色。高速缓存颜色是一种用来区分页面如何索引高速缓存的概念。它的用途将在7.2.3节中进一步讨论(参见图7-8,该图给出了相对于存储器中页面的高速缓存颜色)。
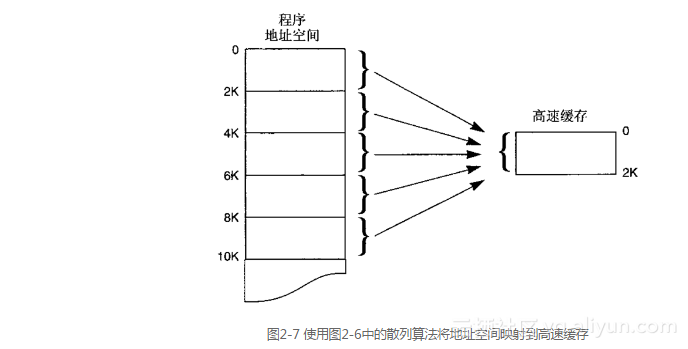
图2-7描述了程序的地址空间是怎样映射到高速缓存的存储器上的。因为在“位<10..4>”中拥有相同位模式的所有地址都会索引到高速缓存中相同的行,所以地址0、2048(2 KB)、4096(4 KB)、6144(6 KB)等都将索引或者映射到高速缓存中的第0行,而地址16、2064(2 KB + 16)、4112(4 KB + 16)、6160(6 KB + 16)等都映射到第1行上。正如2.2.1节所阐述的那样,标记将会解决歧义的问题,因为它们指出了被高速缓存的数据的地址。
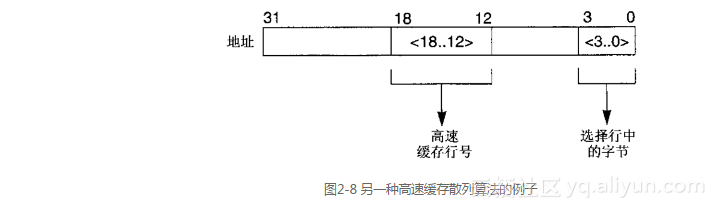
虽然取模散列算法是最常用的方法,但是用来选择高速缓存行的位可以取自地址中的任何部分。为了看到取模散列方法的优点,下面的例子将使用如图2-8所示的另一种散列算法。这两种散列算法之间的区别在于程序中的地址是如何索引高速缓存的。在第一个例子(图2-6)中,连续的程序地址映射到高速缓存中的连续位置,而图2-8中的算法则导致那些在“位<18..12>”中有相同值的整个地址范围都映射到相同的高速缓存行上。因此从0x0到0xfff的所有地址都索引到高速缓存中的第0行,而从0x1000到0x1fff的所有地址都索引到第1行,依此类推。效果如图2-9所示。
虽然实现这样的映射关系是可能的,但是我们不使用它,因为它导致了高速缓存利用率的低下(这里只给出举例说明)。例如,完全处于从0x0到0x1fff地址范围内的一个小程序让其所有的引用都映射到了高速缓存的头两行上。当这个程序正在执行的时候,只使用了2 KB高速缓存中的32字节。在这样一种情况下,可能会有很低的命中率,而从高速缓存感觉不出来性能增益。
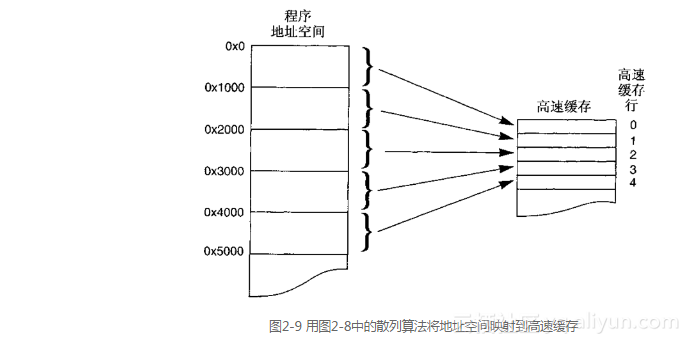
通过对比,读者可以看到图2-6所示的散列算法提供了一种地址到高速缓存的良好映射关系,能够把空间局部性扩展到最大。出于这个原因,它就是所有使用散列算法的高速缓存存储系统而选择的算法。
2.3.2 直接映射高速缓存的实例
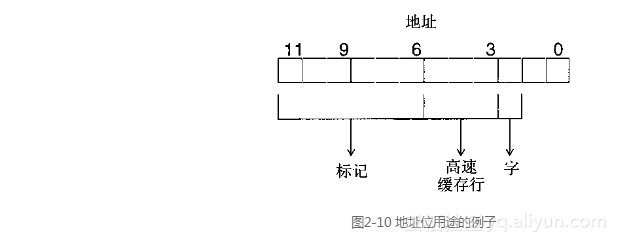
现在我们将迄今为止所介绍的所有概念联系起来,以展示一个查找操作如何发生的完整例子。对于这个例子来说,假定我们有一个字长为4字节、带有12位地址的系统。系统包含的直接映射高速缓存每行8字节,共计8行(为了简化示例,选择了12位的地址和一小块高速缓存。注意,始终都使用八位组的记法)。因为一行中有8字节,意味着以“位<2..0>”选择高速缓存行内的字节,而仅以第2个位就能选择行内的字,因为每行有8字节,即2个字。根据前面的讨论,最好的散列算法是使用“位<5..3>”作为高速缓存行的索引。索引一个8行的高速缓存需要3位,直接选择上述的几位选择高速缓存行内的字节,这样做能基于局部引用来充分利用高速缓存。地址中剩下的位则用于和高速缓存的标记进行比较(参见图2-10)。
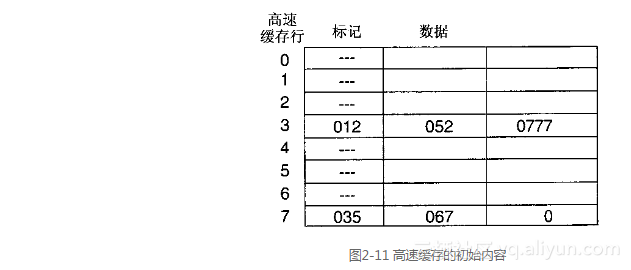
对于这个例子来说,我们假定高速缓存的初始内容如图2-11所示。在这个配置中,标记部分的符号“---”表示这一行无效。在高速缓存行中数据部分的两个字被一条竖线分隔开了。在高速缓存行中的字采用高字节结尾的顺序,这意味着地址最小的字位于高速缓存行的左端。
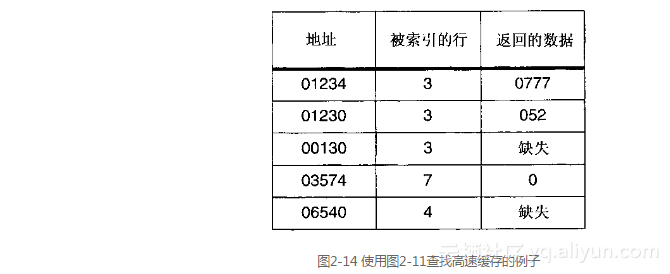
举第一个例子,CPU将发出一次读取地址01234的操作。散列算法选择地址中的“位<5..3>”,它们给该地址一个行索引值3(参见图2-12)。
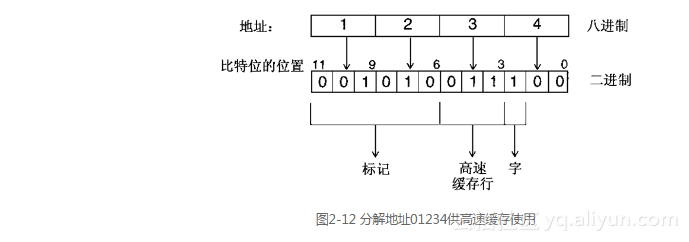
因为这是一个直接映射高速缓存,所以这个索引只和一行有关,如果这个地址的数据都在高速缓存中,那么数据就保存在这一行里。高速缓存控制硬件获得索引值,并且读取高速缓存行3的内容。它发现有一个有效标记,并且把这个标记同地址中的标记部分(位<11..6>,即012)相比较。地址中的标记部分和被索引的高速缓存行中的标记相吻合,因此就出现一次命中。现在,高速缓存控制器必须从高速缓存行中的数据部分选择正确的字。因为地址中的第2个位被设置了,而CPU想要让高端的字保存在高速缓存行的右边,因此想要的字是0777。
这里要理解的一件重要的事情是,对于高速缓存的标记来说没有必要包含完整的地址,因为根据地址在高速缓存中的位置就能推算出地址的一部分。这一点之所以重要是因为它减少了高速缓存行中的总位数,从而也就降低了高速缓存的成本。一般而言,标记只包括地址中散列算法不使用的位。在这个例子中,“位<5..3>”选择出了可以用来保存数据的唯一的高速缓存行。于是,用来构成高速缓存行索引的位可以从标记中省略。类似地,因为该高速缓存行包含8字节,所以地址中的低3位(<2..0>)也不需要保存在标记中。因此,在标记中只需要保存“位<11..6>”。
举第二个例子,考虑当CPU试图从地址0130读取数据时会发生什么情况。散列算法选择“位<5..3>”用于索引,如图2-13所示,这几位又等于3。
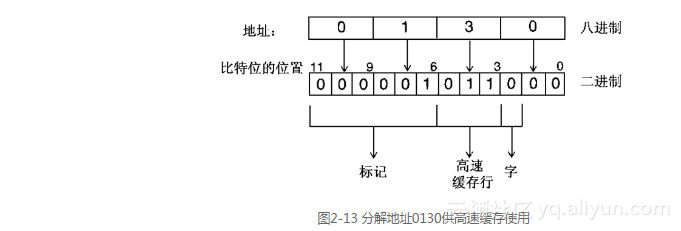
读取高速缓存行3,并且将来自地址的标记01同高速缓存中的标记012进行比较。它们并不匹配,所以就发生了一次缺失。现在必须把地址发送到主存储系统来检索数据。接着,主存储器内从地址0130开始的两个字载入到有索引的高速缓存行中。因为第2位是0,所以需要的是双字中低端的那个字,于是高速缓存行左半部分中的字被返回给CPU。
再举最后一个例子,读取地址06540会造成一次缺失,因为被索引的行(高速缓存行4)没有包含有效的标记,这会自动导致一次缺失。
图2-14总结了前面的几个例子,还给出了其他几个例子。
2.3.3 直接映射高速缓存的缺失处理和替换策略
当出现一次高速缓存缺失的时候,必须从主存储器读取数据然后返回给CPU。数据还要载入高速缓存,以便在近期内再次引用它时可以立即得到。如果高速缓存行比一个字大,就要从主存储器中多读几个字,以便在高速缓存中载入完整的一行。此时就会造成邻接字被预取(prefetched),从而充分利用了局部引用特性。要读取完整的一行,高速缓存可能需要额外的存储器周期,也可能不需要,这取决于主存储系统的设计。为了获得最佳性能,主存储系统应该以高速缓存行的大小为单元传送数据,这称为突发模式(burst mode)的传送。这种模式能让完整的高速缓存一行在一次存储器操作中传送。没有突发模式,传送必须以更小的单元来执行,从而增加了开销。
一旦主存储器提供了所需的数据,就必须在高速缓存中找到一个位置保存它。这个位置必须经过挑选,以便散列算法在以后的查找操作期间能正确地定位高速缓存的行。在直接映射高速缓存中,这个位置是通过采用散列算法计算行中首字的地址,从而得到该行将会保存在高速缓存中什么地方的行索引值。最初检查的和发生缺失时找到的结果始终都是同一行。新行必须保存在这个位置,因为如果把它保存在高速缓存中的其他行,以后引用时就不能通过索引找到它。这是直接映射高速缓存唯一可能采用的替换策略。
如果缺失操作期间被替换的高速缓存行以前并不是有效行,那么就可以将新行的数据载入到这一行中,并且设定标记,指出数据的地址。该行的有效位也设为ON。如果这一行以前保存着不同地址的有效数据,那么这些数据就会被丢弃,并用新行替换它们。如果采用写回高速缓存机制,而且修改了原来的数据(参见2.2.5节),那么在替换它之前必须将它写回存储器,从而不会丢失修改过的数据。
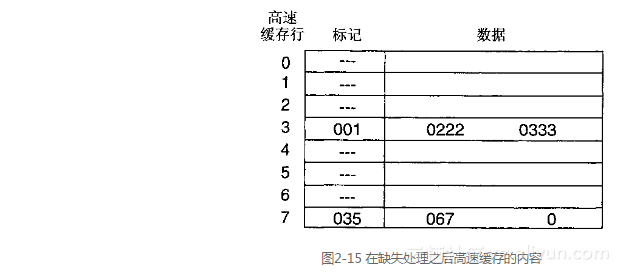
举一个例子,再次考虑2.3.2节里的例子和图2-11描绘的高速缓存。如果CPU试图读取位于00130的字,那么就会发生一次缺失,因为高速缓存内的行3缓存的是从地址01230到地址01237的数据。如果主存储器在地址00130处保存的值为0222,在地址00134处保存的值为0333,那么在处理缺失之后,高速缓存将被更新为图2-15所示的内容。
新标记和新数据替换了原来的标记和数据,高速缓存内其余的行则保持不变。CPU最初请求的数据0222在新行写入高速缓存的同时返回给CPU。
2.3.4 直接映射高速缓存的总结
在直接映射高速缓存中,主存储器内数据的地址和高速缓存内可能保存该地址的位置或行之间具有一一对应的关系。数据在高速缓存内是通过散列该地址来定位的,计算得出了高速缓存中可以保存该数据的唯一一行的索引。直接映射高速缓存既可以使用写直通策略,也可以使用写回策略。
直接映射高速缓存是实现起来最简单的高速缓存,因为在读或者写操作期间只可能有一个搜索命中的位置。这就简化了控制逻辑,从而让实现的成本更低。遗憾的是,这也是直接映射高速缓存的缺点,因为许多不同的地址都被散列到了同一行上。对于一个带有病态引用模式的程序,其中局部引用的数据或者指令地址都产生了相同的索引或者总是位于一小组索引的集合中,这样的程序就无法从高速缓存获益,因为命中率将非常低。在这样的情况下,高速缓存行在被再次命中之前总是被替换掉,所以这种情形称为高速缓存颠簸(cache thrashing)(这个名字来源于虚拟存储调页系统中出现的相同现象)。下面一节介绍对直接映射高速缓存所做的一种改进,以此减少颠簸,提高命中率。