一切源于一个实验,请看下面的例子:
表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
我往两个表中插入了30w的数据(插入的时候性能差别InnoDB比MyISAM慢)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
返回结果:

一次查询就会差别这么多!!InnoDB和MyISAM,赶紧分析分析为什么。
首先是使用explain来进行查看
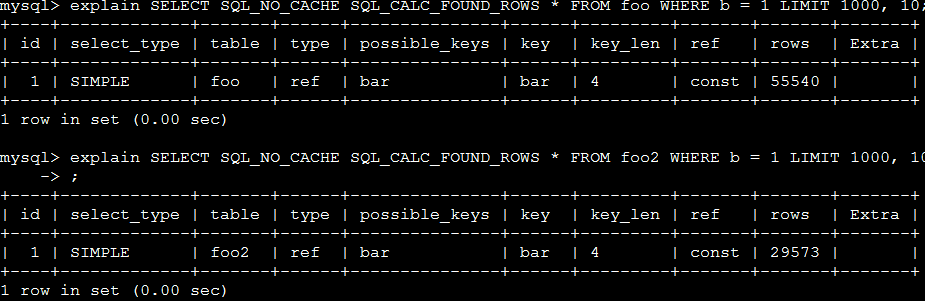
确定两边都没有使用index,第二个查询查的rows,并且MyISAM的查询rows还比InnoDB少这么多,反而是查询慢于InnoDB!!这Y的有点奇怪。
没事,还有一个牛掰工具profile
具体使用可以参考:http://dev.mysql.com/doc/refman/5.0/en/show-profile.html
使用方法简单来说:
|
1 2 3 4 5 |
|

这个数据中就可以看到MyISAM的Sending data比InnoDB的Sending data费时太多了。查看mysql文档
http://dev.mysql.com/doc/refman/5.0/en/general-thread-states.html
Sending data
The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.
Sending data是去磁盘中读取select的结果,然后将结果返回给客户端。这个过程会有大量的IO操作。你可以使用show profile cpu for query XX;来进行查看,发现MyISAM的CPU_system比InnnoDB大很多。至此可以得出结论是MyISAM进行表查询(区别仅仅使用索引就可以完成的查询)比InnoDB慢。
至于再往下的为什么,我想就需要看源码了..于是,就此打住。
附带一篇文章,里面还有status的用法
http://hi.baidu.com/thinkinginlamp/item/8d038333c6b0674a3075a1d3