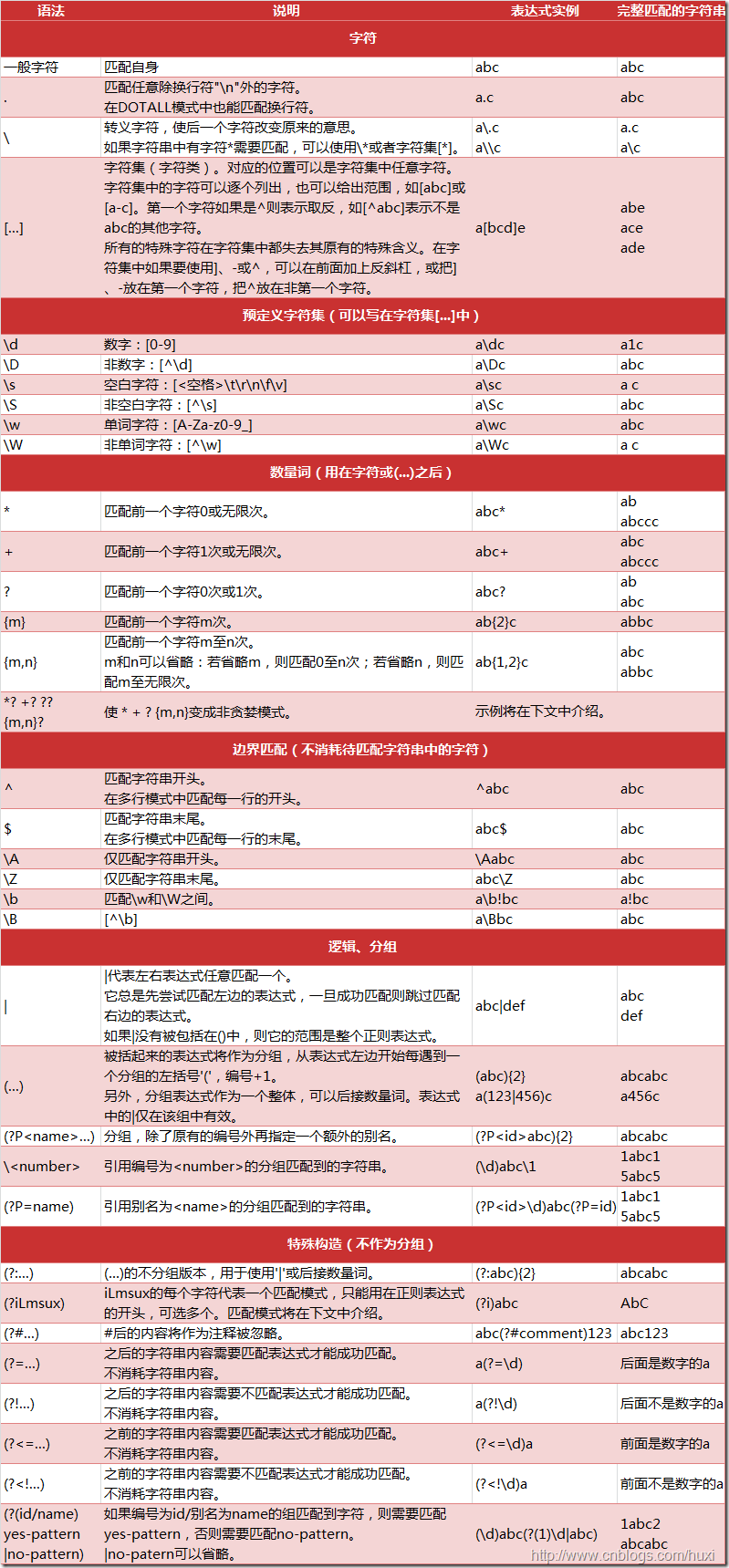
1.什么是正则表达式的贪婪与非贪婪匹配
如:String str="abcaxc";
Patter p="ab*c";
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c)。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab*c)。
2.编程中如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
量词:{m,n}:m到n个
*:任意多个
+:一个到多个
?:0或一个
demo
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest {
public static void main(String[] arg){
String text="(content:\"rcpt to root\";pcre:\"word\";)";
String rule1="content:\".+\""; //贪婪模式
String rule2="content:\".+?\""; //非贪婪模式
System.out.println("文本:"+text);
System.out.println("贪婪模式:"+rule1);
Pattern p1 =Pattern.compile(rule1);
Matcher m1 = p1.matcher(text);
while(m1.find()){
System.out.println("匹配结果:"+m1.group(0));
}
System.out.println("非贪婪模式:"+rule2);
Pattern p2 =Pattern.compile(rule2);
Matcher m2 = p2.matcher(text);
while(m2.find()){
System.out.println("匹配结果:"+m2.group(0));
}
}
}
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
string pattern1 = @"a.*c"; // greedy match Regex regex = new Regex(pattern1);
regex.Match("abcabc"); // return "abcabc"
非贪婪匹配:在满足匹配时,匹配尽可能短的字符串,使用?来表示非贪婪匹配
string pattern1 = @"a.*?c"; // non-greedy match Regex regex = new Regex(pattern1);
regex.Match("abcabc"); // return "abc"
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
参考文章:
http://www.cnblogs.com/xudong-bupt/p/3586889.html
本文出自 “点滴积累” 博客,请务必保留此出处http://tianxingzhe.blog.51cto.com/3390077/1723247
时间: 2024-11-03 11:17:43