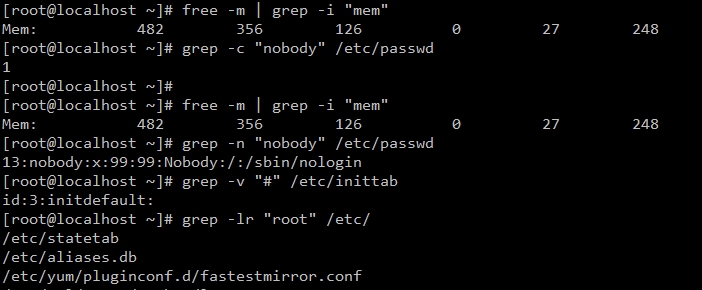
1、grep命令:查找文件里符合条件的字符串
一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来
语法格式: grep [options]
-i:ignore-case 忽略大小写差别
-c:count 只打印匹配的总行数,不显示匹配的内容信息
-n:line-number 在匹配的行前面打印行号
-v:revert-match 反检索,只显示不匹配的行
-r:recursion递归地,读取每个文件夹下的所有档案
-l :不显示平常一般的输出结果,只显示符合的文件名称
2、awk命令:一个强大的文本处理工具,逐行扫描,从第一行到最后一行
使用语法:awk 'pattern{action}' filename
pattern:正则表达式
action:输出语法
你可以省略pattern和 action之一,但不能两者同时省略,当省略pattern时没有样式匹配,表示对所有行(记录)均执行操作,省略action时执行缺省的操作——在标准输出上显示。
语法格式:awk [ -F re] [parameter...]
-F re:允许awk更改其字段分隔符
parameter: 该参数帮助为不同的变量赋值
-v:定义变量
-f:指定脚本文件
三种调用方式:
1、awk命令行
2、使用-f选项调用awk程序,例如:awk -f progfile file ,其中progfile是指定一个文本文件
3、利用命令解释器调用awk程序,需要在awk脚本声明调用方式,例如:#!/bin/awk -f
命令行方式使用内容过滤:
[root@test ~]# awk '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#显示分隔符指定列(1列),分隔符默认是空格,$1是显示分隔符前面一列
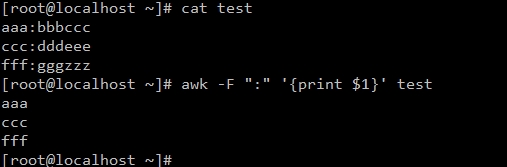
#显示test文件中匹配123的行
[root@test ~]# awk '/123/ {print $1}' test
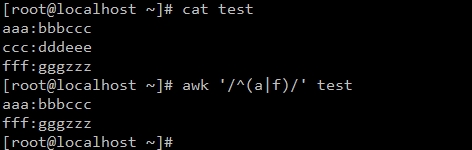
#显示所有以a或f开头的行
4、sed命令:一种在线编辑器,它一次处理一行内容
处理时,把当前处理的行存储在临时缓冲区中,称为'模式空间'(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
常用参数:
i 插入
s 替换
e 多点编辑
d 删除
a 追加到行后面
g 全部替换,无g只替换每行第一个
q 退出
#将所有包含aaa替换为jjj
sed 's/aaa/jjj/' test
#把这行注释去掉,替换文本
sed -i 's/#ServerName www.example.com:80/ ServerName 192.168.0.202:80/g'
将所有包含/var/www/html/替换为/opt/web/,分隔符'/'可以用别的符号代替,比如 ',' '_' '|' 等
sed -i s/\/var\/www\/html/\/opt\/web/' /etc/httpd/conf/httpd.conf
等同于:
sed -i 's_/var/www/html/_/opt/web/_' /etc/httpd/conf/httpd.conf
#插入一行到391行,包括特殊符号'/'
sed -i '391 s/^/AddType application\/x-httpd-php .php.html/' httpd.conf
#只打印第一行数据
sed -n '1p' /etc/passwd
#打印包含root的行,禁止默认输出
sed -n '/root/p' /etc/passwd
#删除13行
sed -i '13d' /etc/passwd
#删除13行到最后一行
sed -i '13,$d' /etc/passwd
#将包含uucp的行删除
sed -i '/uucp/d' /etc/passwd
5、find命令:查找具有某一特征的文件(例如文件权限、文件属主、文件长度、文件类型等
用法:find [path] [options] [条件]
Path:查找路径
Options:选项
例如:
-name:按照文件名查找文件
-mtime:按照文件的更改时间来查找文件,后跟-n、+n来表示多少天内和以前
-user:按照文件属主来查找文件
-group:按照文件所属的组来查找文件
-type:查找某一个类型的文件,诸如:b(块设备)、d(目录)、l(符号链接)、f(普通文件)
-size:根据文件大小来查找文件
#在根目录查找更改时间在5日以内的文件
find /tmp -mtime -5
#在/var目录下查找更改时间在3日以前的文件
find /var/ -mtime +3
#查找系统中所有文件长度为0的普通文件,并列出他们的完整路径
find / -type f -size 0 -exec ls -l {} \;
#查找/var/log目录中更改时间在7日以前的普通文件,并删除他们
find /var/log/ -type f -mtime +7 -exec rm {} \;
#找出用户test拥有的文件,并将他们拷贝到/root/test目录中
find / -user test -exec cp {} /root/test \;
6、sort命令:对文件中的各行进行排序
sort命令将逐行对文件中的内容进行排序,如果两行的首字符相同,该命令将继续比较这两行的下一字符,如果还相同,将继续进行比较.
格式:sort [选项] 文件
主要选项:
-r:倒序排序,默认是升序。
-n:按数值大小进行排序
-k:KeyDefinition 指定排序关键字。
-t:Character 指定 Character 作为字段分隔符
-d:使用字典顺序排序。比较中仅考虑字母、数字和空格
-f:将小写字母与大写字母同等对待
-u:去掉重复的行,使文件中的每一行唯一
7、uniq命令:删除文件中的重复行
文件经过处理后在它的输出文件中可能会出现重复的行。例如,使用cat命令将两个文件合并后,再使用sort命令进行排序,就可能出现重复行。这时可以使用uniq命令将这些重复行从输出文件中删除,只留下每条记录的唯一样本。
格式:uniq [选项] 文件
主要选项:
-c:显示行号
-d:只显示重复行。
-u:只显示文件中不重复的各行。
8、cut命令:显示文件中每行的指定内容
格式:cut -d 分隔字符 [-cf] fields
-d:后面接的是分隔字符,默认情况下为Tab;
-c:后面接的是第几个字符
-f:后面接的 是第几个区块
#列出/etc/passwd文件中的所有用户,按照升序排列
cut -d : -f 1 /etc/passwd | sort
#显示/etc/passwd文件下uid为0的用户名以及uid。
cut -d : -f 1,3/etc/passwd|grep ':0$'
正则表达式'$'表示以字符结尾,'^'表示以某字符开始。
9、tr命令:从标准输入删除或替换字符,可以看为sed简化软件
常用选项的tr命令格式为:
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个。
#将小写字符转换成大写
tr 'a-z' 'A-Z' < file
#将文件中删除所有空字符
tr –d ‘\0’< file
#删除文件中shell字符
cat test | tr -d 'shell'
#将文件中所有abc字符替换efg并另存为新文件
cat test | tr 'abc' 'efg' >new file
10、其他文本处理命令
cat:从头开始显示内容,并将所有内容输出
常用参数,-n显示输出的行数编号
tac:从最后一行倒序显示内容,并将所有内容输出
head:默认显示头10行,-n指定显示多少行数
tail:默认显示最后10行,-n指定显示多少行数,-f实时显示内容
more:分屏查看文本文件
less:和more类似,但可以往前翻页
nl:显示时输出行号
wc:计算文件的字节数、单词数和行数
常用参数:-c统计字节数,-l统计行数,-m统计字符数