OpenCL内存对象:
OpenCL内存对象就是一些OpenCL数据,这些数据一般在设备内存中,能够被拷入也能够被拷出。OpenCL内存对象包括buffer对象和image对象。
buffer对象:连续的内存块----顺序存储,能够通过指针、行列式等直接访问。
image对象:是2维或3维的内存对象,只能通过read_image() 或 write_image()来读取。image对象可以是可读或可写的,但不能同时既可读又可写。

该函数会在指定的context上创建一个buffer对象,image对象相对比较复杂,留在后面再讲。
flags参数指定buffer对象的读写属性,host_ptr可以是NULL,如果不为NULL,一般是一个有效的host buffer对象,这时,函数创建OpenCL buffer对象后,会把对应host buffer的内容拷贝到OpenCL buffer中。
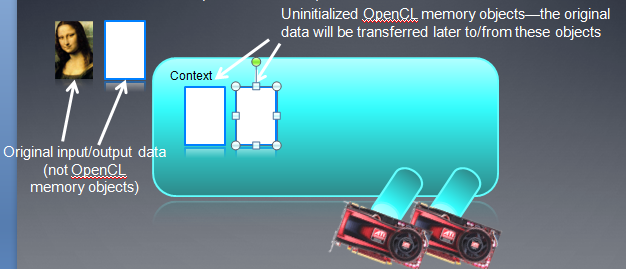
在Kernel执行之前,host中原始输入数据必须显式的传到device中,Kernel执行完后,结果也要从device内存中传回到host内存中。我们主要通过函数clEnqueue{Read|Write}{Buffer|Image}来实现这两种操作。从host到device,我们用clEnqueueWrite,从device到host,我们用clEnqueueRead。clEnqueueWrite命令包括初始化内存对象以及把host 数据传到device内存这两种操作。当然,像前面一段说的那样,也可以把host buffer指针直接用在CreateBuffer函数中来实现隐式的数据写操作。

这个函数初始化OpenCL内存对象,并把相应的数据写到OpenCL内存关联的设备内存中。其中,blocking_write参数指定是数拷贝完成后函数才返回还是数据开始拷贝后就立即返回(阻塞模式于非阻塞模式)。Events参数指定这个函数执行之前,必须要完成的Event(比如先要创建OpenCL内存对象的Event)。

OpenCL程序对象:
程序对象就是通过读入Kernel函数源代码或二进制文件,然后在指定的设备上进行编译而产生的OpenCL对象。

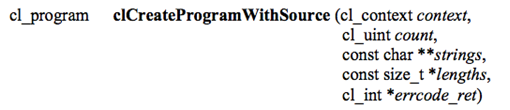
这个函数通过源代码(strings),创建一个程序对象,其中counts指定源代码串的数量,lengths指定源代码串的长度(为NULL结束的串时,可以省略)。当然,我们还必须自己编写一个从文件中读取源代码串的函数。

对context中的每个设备,这个函数编译、连接源代码对象,产生device可以执行的文件,对GPU而言就是设备对应shader汇编。如果device_list参数被提供,则只对这些设备进行编译连接。options参数主要提供一些附加的编译选项,比如宏定义、优化开关标志等等。
如果程序编译失败,我们能够根据返回的状态,通过调用clGetProgramBuildInfo来得到错误信息。
加上创建内存对象以及程序对象的代码如下: