机器学习能发现数据下隐藏的各种客观规律,对提高产品的智能化程度,提升用户满意度等方面有很大的帮助,这里不再赘言。那么怎么实现一个机器学习系统,并和大数据的开发套件上的调度结合起来实现自动化呢,本文就一些测试数据做一个例子。
场景假设
我这里用著名的鸢尾花数据集作为测试数据。那就假设我是一个植物研究院,希望根据已经有的一些花的数据和分类,判断新收集上来的样本的花的类型(类似的,企业数据里可以判断用户会不会买,会不会投诉甚至流失)。这里用的算法就先简单一些,用朴素贝叶斯。
使用场景是,假设我们的项目里已经有一些历史的花的数据,每天训练可能还会有一些更新。希望针对这些训练数据,做出一个算法模型,预测新采集到的花的类型。
数据准备
我Iris表存放当天的全量训练集。而预测集,用Iris_daily表做每天增量同步。具体每天配置增量同步的方法,可以参考这个例子。比如1月18日凌晨做的计算,会计算1月17日的全量数据。那就把17日的数据放到ds='20170117'这个分区里。
表结构如下
odps@ >desc iris_daily;
+------------------------------------------------------------------------------------+
| TableComment: |
+------------------------------------------------------------------------------------+
| CreateTime: 2017-01-18 13:31:40 |
| LastDDLTime: 2017-01-18 13:31:40 |
| LastModifiedTime: 2017-01-18 13:39:45 |
+------------------------------------------------------------------------------------+
| InternalTable: YES | Size: 1960 |
+------------------------------------------------------------------------------------+
| Native Columns: |
+------------------------------------------------------------------------------------+
| Field | Type | Label | Comment |
+------------------------------------------------------------------------------------+
| sepal_length | double | | |
| sepal_width | double | | |
| petal_length | double | | |
| petal_width | double | | |
| category | string | | |
+------------------------------------------------------------------------------------+
| Partition Columns: |
+------------------------------------------------------------------------------------+
| ds | string | |
+------------------------------------------------------------------------------------+
--浏览一下前几条数据:
+--------------+-------------+--------------+-------------+------------+------------+
| sepal_length | sepal_width | petal_length | petal_width | category | ds |
+--------------+-------------+--------------+-------------+------------+------------+
| 5.1 | 3.5 | 1.4 | 0.2 | Iris Setosa | 20170117 |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris Setosa | 20170117 |
| 4.7 | 3.2 | 1.3 | 0.2 | Iris Setosa | 20170117 |
+--------------+-------------+--------------+-------------+------------+------------+
模型训练
我们先在机器学习产品里搭建一个算法。看一下效果。画布区的配置可以参考下面截图(这里需要说明的是,在机器学习画布区里测试的时候yyyyMMdd测试的时候业务期是今天,但是实际上企业上我们都是今天跑昨天的数据,业务期也是昨天的,可以在画布区把任务先配置成"ds=@@{yyyyMMdd-1d}",到后面嵌入到大数据开发套件前再改成ds=@@{yyyyMMdd},):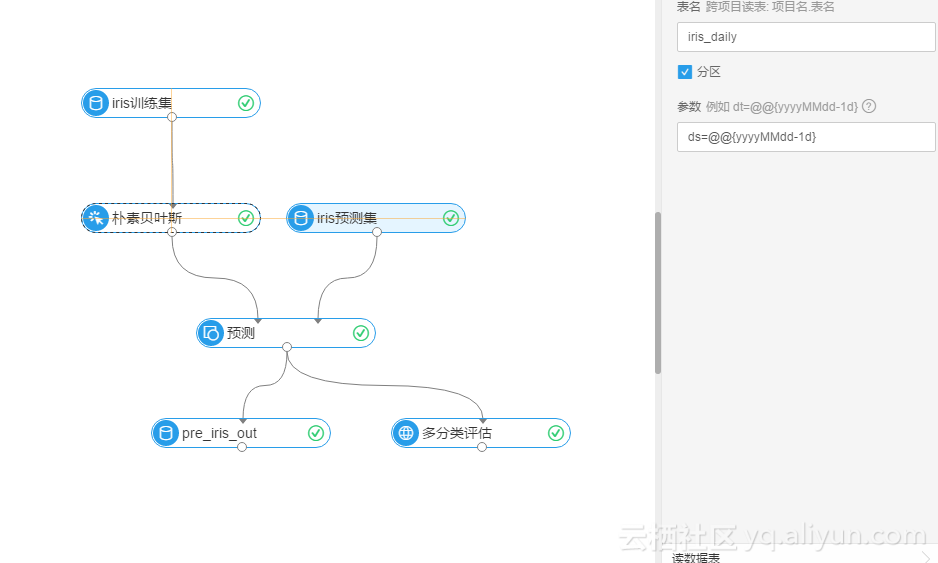
朴素贝叶斯的配置如图: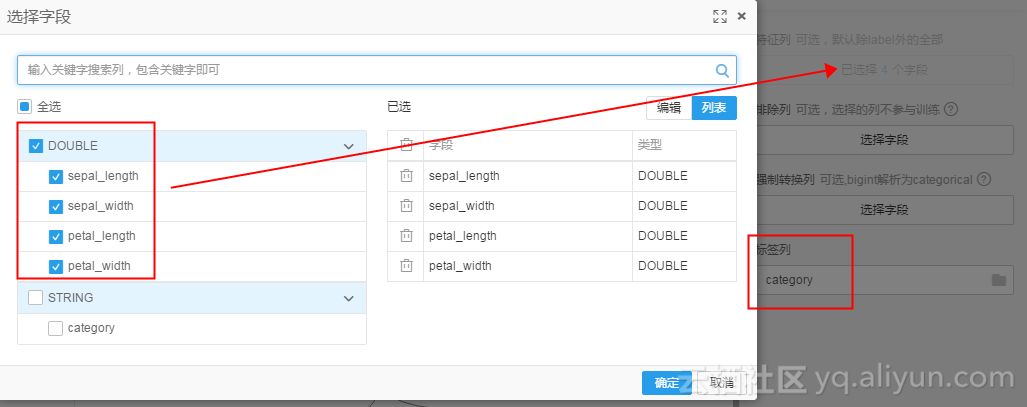
咱们先跑一次这个模型,可以看到预测的结果如图: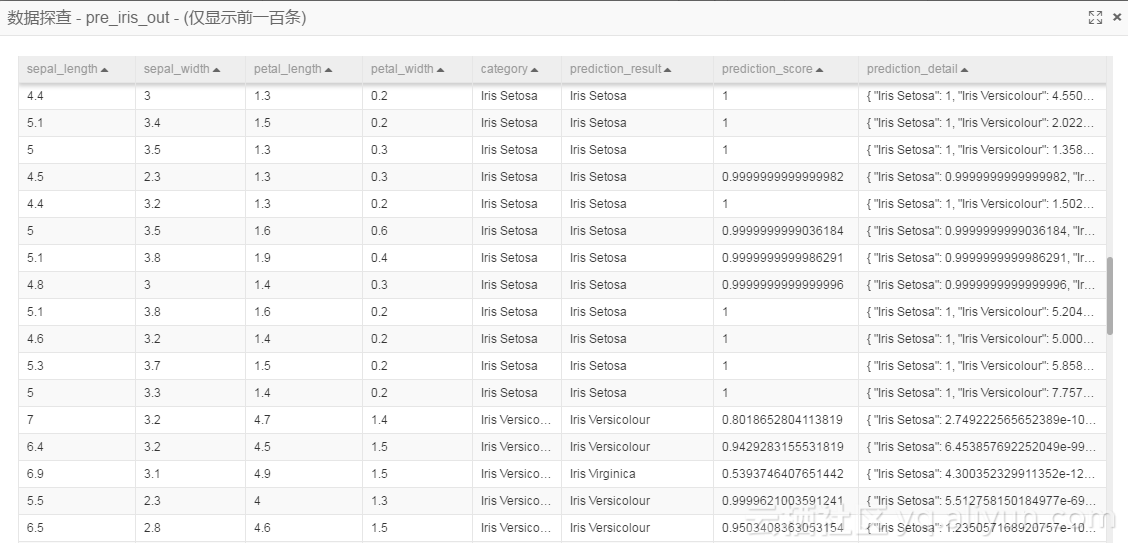
Iris Setosa的数据和其他的2个分类的区分度比较大,所以预测都是准的。但是Iris Virginica和Iris Versicolour之间区别不大,甚至有一些交集,就会有一些临界点的数据容易预测不准。下图来自机器学习产品的散点图模块。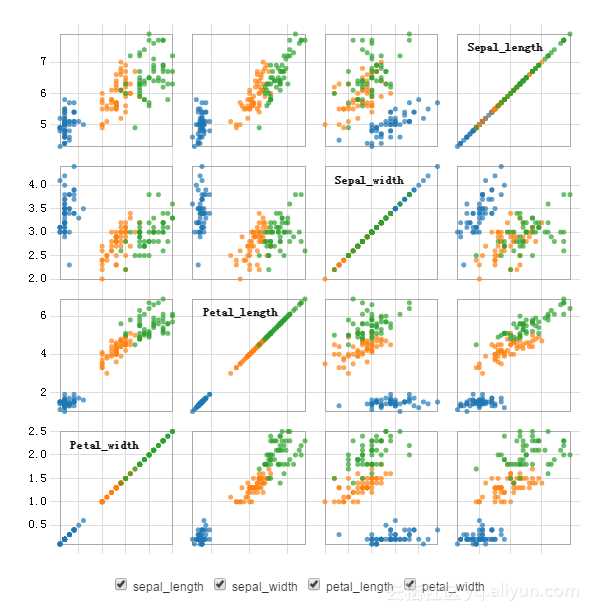
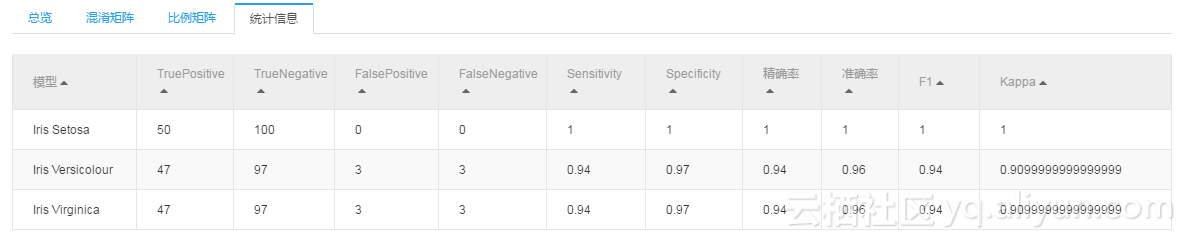
训练的结果咱们也看下(这里就截了混淆矩阵和统计信息):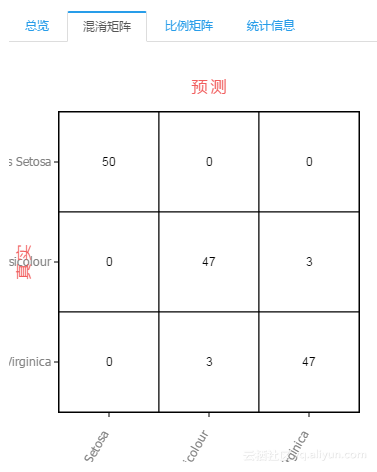
至此机器学习实验的配置结束。如果觉得这个例子有点简单,还没能理解机器学习的配置方法,可以在创建实验的时候使用模板来创建,里面已经把数据、实验配置都弄好了,更容易理解算法的用法。
定时调度
毕竟我们不能每天去手工跑一次实验,我们可以用大数据开发套件创建一个任务,把数据的前文提到的数据导入、后续的导出等串起来。
我们需要先创建一个工作流,在工作流里配置任务,如图: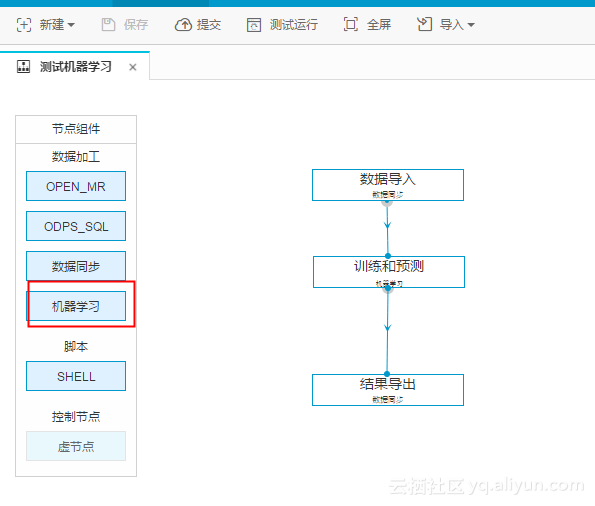
对于机器学习组件,我们双击组件,进去选择之前配置的实验即可。后续的任务的测试,发布流程和大数据开发套件里的其他组件的用法是一样的。
其他
可能大家在机器学习的控制台有看到一个在线预测的功能,这是一个后续会推出的新功能。我们看到现在我们的预测是离线算好的。如果是实时预测不是更Cool嘛。比如前面提到的购买行为、用户投诉行为的预测,都需要较好的时效性。后续通过在线预测的功能就可以实现这个功能啦~
看到这里,可能你还有一个疑问,为什么我不用更加常见的企业个性化推荐场景做例子呢?自己使用底层产品自己搭建固然可以,但是更好的方法是使用已经有的产品,省的自己重复造轮子,把资源更多地投入到业务上。所以可以参考推荐引擎,或许更加适合你。
本文使用的产品涉及大数据计算服务(MaxCompute),地址为https://www.aliyun.com/product/odps
机器学习 https://data.aliyun.com/product/learn
配合大数据开发套件 https://data.aliyun.com/product/ide 完成的。
如果有问题,可以加入我们的钉钉群来咨询