一、Hadoop介绍
Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。
Hadoop由两部分组成,分别是分布式文件系统(HDFS)和分布式计算框架MapReduce。其中分布式文件系统(DFS)主要用于大规模数据的分布式存储,而MapReduce则构建在分布式文件系统之上,对于存储在分布式文件系统中的数据进行分布式计算。
优点:
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
1、HDFS架构图

HDFS的架构总体上采用了m/S(master/slave)架构,主要有以下几个组件组成:Client、NameNode、Secondary NodeNode和DataNode。
(1)Client
Client(用户)通过NameNode和DataNode交互访问HDFS中的文件。Client提供一个类似POSIX的文件系统接口工用户调用。
(2)NameNode
整个Hadoop集群中只有一个NameNode.它是整个系统的中枢,它负责管理HDFS的目录树和相关文件 元数据信息。这些信息是以“fsimage(HDFS元数据镜像文件)和Editlog(HDFS文件改动日志)两个文件形式存放在本地磁盘,当HDFS重启时冲洗构造出来的。NameNode还负责监控各个DataNode的健康状态,一旦发现某个DataNode损坏,则将DataNode移出HDFS并重新备份其上面的数据。
(3)Secondary NameNode
Secondary Namenode 最重要的任务并不是为NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode,为了减轻NameNode压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由Secondary NameNode完成。
(4)DataNode
每个Slave节点上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,block默认大小为64MB(GFS也是64MB)。当用户上传一个大于64MB的文件时,该文件会被切成若干个block,分别存储到不同的DataNode(更容易分布式处理);同时为了数据可靠,会将同一个block以流水线的方式写到若干个(配置中默认为3)不同的DataNode上。
JobTracker:hadoop的Map/Reduce调度器,负责与TackTracker通信分配计算任务并跟踪任务进度。
TaskTracker:hadoop调度程序,负责Map,Reduce任务的具体启动和执行。
2、环境描述:
| 操作系统:CentOS6.3_x64 | IP地址 |
| MASTER:Namenode、jobtracker | 192.168.0.202 |
|
SLAVE1:Datanode、tasktracker SLAVE2:Datanode、tasktracker |
192.168.0.203 192.168.0.204 |
| 配置/etc/hosts记录,主机名相互ping通。 | |
| MASTER.COM | 192.168.0.202 |
|
SLAVE1.COM SLAVE2.COM |
192.168.0.203 192.168.0.204 |
3、Hadoop组件介绍
| Hadoop两个组件 | Hadoop两个节点 | Mapreduce两个引擎 |
| HDFS:分布式文件系统存储 | Name Node:集群中仅一个,提供数据服务,记录存储数据目录分布信息、分块信息 | job trackers |
| Mapreduce:海量数据分析计算 | Data Node:为HDFS提供存储数据块 | task trackers |
4、安装前准备
关闭IPTABLES和SELinux:
|
1 2 |
|
|
1 2 |
|
三个节点创建相同的用户hadoop,Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;2个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行;在Hadoop启动以后,Namenode是通过SSH来启动和停止各个datanode上的各种守护进程的,所以就必须要配置无密码登陆。
二、配置每台java环境
|
1 2 |
|
添加环境变量:
|
1 2 3 4 5 6 7 |
|
三、创建用户和配置密钥对认证
1.三个节点都要创建hadoop用户,而且uid一样并设置密码
|
1 2 |
|
2.登陆到master创建密钥对
|
1 2 3 4 |
|
3.登陆两台slave创建.ssh目录
|
1 |
|
4.登录master将公钥上传到两台slave并重命名为authorized.keys
|
1 |
|
5.用root登陆两台slave修改ssh启用密钥对认证
|
1 2 3 4 5 6 7 8 |
|
6.验证登陆
|
1 |
|
四、安装Hadoop并将配置完整复制到slave机器上
1.下载:http://www.apache.org/dist/hadoop/core/hadoop-1.2.0/
|
1 2 |
|
2.为了方便,使用hadoop命令或者start-all.sh等命令,添加环境变量:
|
1 2 3 4 5 6 |
|
五、修改集群配置(hadoop/conf)
1.配置masters和slaves主从节点
vi master:去掉localhost,加入master机器的IP:192.168.0.202
vi slaves:去掉localhost,加入slave所有机器的IP:192.168.0.203 192.168.0.204
2.vi hadoop-env.sh
|
1 |
|
3.vi core-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
参数说明:
fs.default.name: 主节点名字和端口
hadoop.tmp.dir:存放master临时文件,需要手动创建,以后不能删除,不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
fs.checkpoint.period: snn检查nn日志的时间周期,这里是60秒,生产环境建议12小时
4.vi mapred-site.xml
|
1 2 3 4 5 6 |
|
参数说明:
mapred.job.tracker:master的主机(或者IP)和端口
5.vi hdfs-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
参数说明:
dfs.data.dir:DataNode存放块数据的本地文件系统路径
dfs.name.dir:NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
dfs.replication:数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:
此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
配置结束,使用scp命令把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
|
1 |
|
六、启动hadoop
1.先格式化一个新的分布式文件系统(hadoop namenode -format)
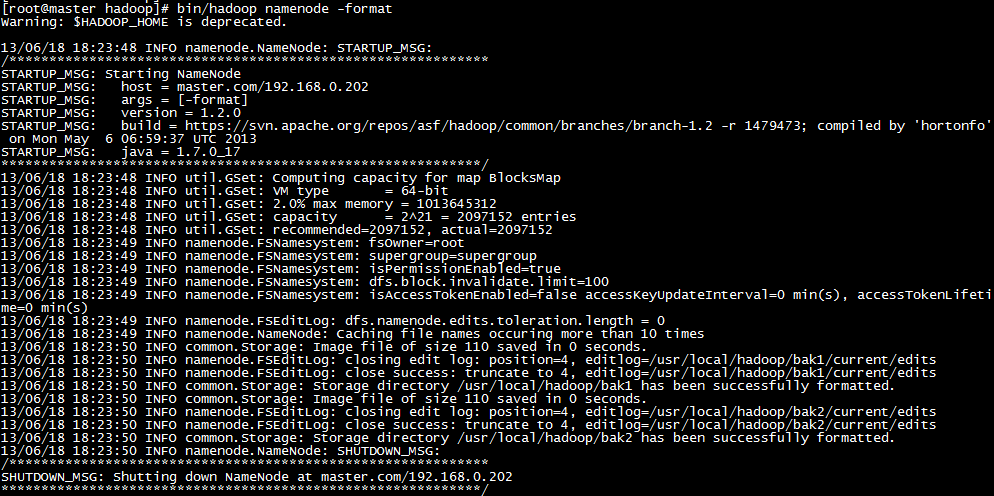
2.启动hadoop节点(start-all.sh)

执行完后可以到master机器上到/usr/local/hadoop/hdfs/data1、/usr/local/hadoop/hdfs/data2、/usr/local/hadoop/name1和/usr/local/hadoop/name2四个目录。在主节点master上面启动hadoop,主节点会启动所有从节点的hadoop。
3.关闭hadoop节点
stop-all.sh
主节点关闭hadoop,主节点会关闭所有从节点的hadoop。Hadoop守护进程的日志写入到logs下。
七、测试
1.查看端口是否开启
netstat -tupln | grep 9000
netstat -tupln | grep 9001
2.访问master(NameNode)和slave(JobTracker)启动是否正常http://192.168.0.202:50070和50030
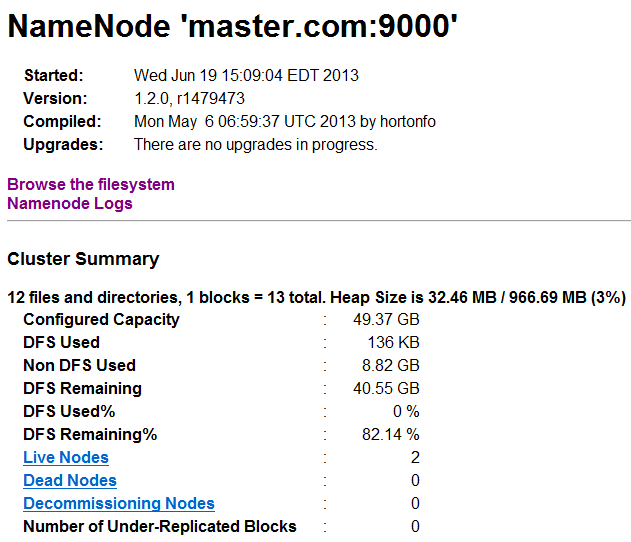
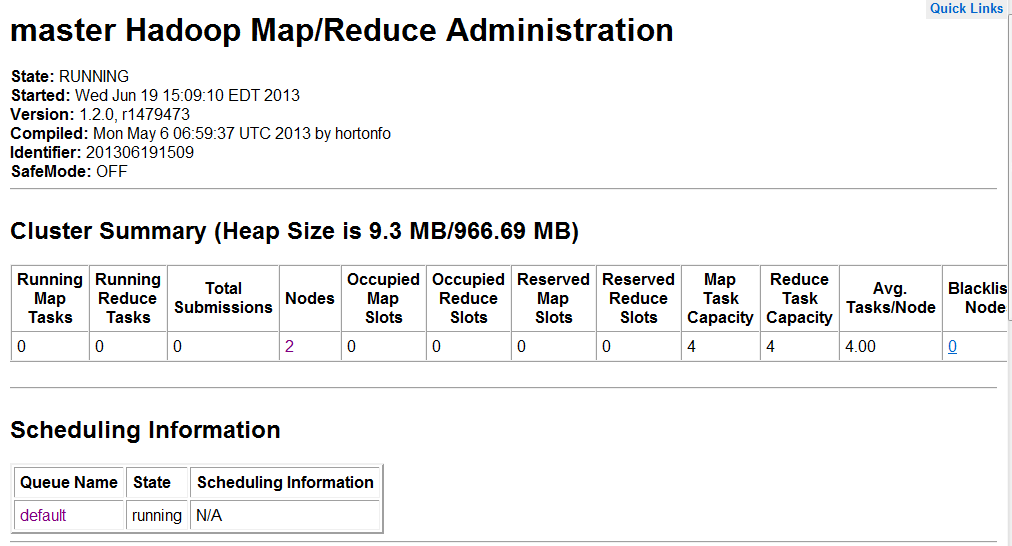
3.jps查看守护进程是否运行
master显示:Job Tracker JpsSecondaryNameNod NameNode
slave显示:DataNode Jps TaskTracker
4.查看集群状态统计信息(hadoop dfsadmin -report)
master和slave输入信息:

八、常用命令
|
1 2 3 4 5 6 7 8 |
|
九、添加一个新的节点
1.在新加的节点上安装hadoop,
2.修改hadoop/conf/master文件,加入 NameNode主机名,
3.在NameNode节点上修改hadoop/conf/slaves文件,加入新加节点主机名,
4.建立到新加节点无密码的SSH连接
5.运行启动命令:start-all.sh
6.http://master.node:50070,查看新增加的DataNode