2.7 案例分析:使用链路状态数据库
OSPF网络设计解决方案(第2版)
在本章之前的内容中,我们已经学习到了如何使用LSA在OSPF路由器之间发送有关链路的信息。这些LSA被存储于路由器内部的一个数据库中,并且一条LSA将作为该数据库的一条记录。
图2-16给出了本节案例分析所使用的OSPF网络拓扑。
例2-6显示了在HAL9000路由器上使用show ip ospf database命令的输出条目。
![]()
注意这里的输出并未包含图2-16中其他区域的信息(即只有区域0的条目),这是因为路由器HAL9000是一台骨干路由器,它的所有接口都位于区域0中。例2-7是在路由器Tokyo上使用相同命令得到的输出,你可以对比查看例2-6中路由器HAL9000的输出。
![]()
注意
在许多情况下,人们经常把链路状态数据库称为拓扑数据库。从严格意义上来说,这种命名是不正确的,因为作为描述OSPF v2的RFC 2328文档明确定义了上述数据库的名称,即链路状态数据库。
如例2-7所示,每一条LSA条目所包含的信息都拥有相应的含义,这些信息如下所示(示例中高亮显示的部分)。
标题和概述——Cisco 路由器在显示的 LSA 条目上方给出了有关这些LSA条目的简要介绍信息。首先显示了当前路由器的OSPF RID,用于告知用户正在查看的是哪一台路由器;然后显示了和数据库对应的OSPF路由进程的进程号。Cisco路由器可以运行多个相互独立的OSPF实例(进程)。
区域信息——回顾之前的内容,像ABR这样的路由器可以为OSPF的每个区域各自维护一份独立的链路状态数据库(LSDB)。示例中这一信息显示了LSA的类型和LSDB所属的OSPF区域。
Link ID——LSA的名称,不同类型LSA的Link ID的取值也不同。
ADV router——使用RID来标识产生该LSA的通告路由器。
Age——LSA的生存时间,单位为秒。
Seq#——LSA的序列号,该序列号包含在LSA中。数据库使用序列号来判断LSA是否为旧的或重复的。
Checksum——用于校验LSA的正确性。
Link count——发送该LSA的路由器运行了OSPF的接口的数量。这一字段仅在1类路由器LSA中存在。
图2-17显示了拥有8台路由器的网络。这些路由器都运行了OSPF,并且接口关联了不同的开销值(图中使用粗细线条进行区分)。
![]()
在上图中,注意每条链路的接口出方向都标示了相应的开销值。例如,从RtrA直接去往网络中心RtrE的开销为4;但是如果从RtrE直接去往RtrA,其开销值为5。因此,这里的开销值是基于接口的,并且应用于出方向。
OSPF基于图2-17所给定的网络拓扑建立了一份链路状态数据库。另外,假设网络中所有的路由器都属于同一个OSPF区域,则每一台路由器所拥有的链路状态数据库是相同的。本例中的区域为区域0。
注意
为了提高可读性,下面的内容对图2-17中路由器的名称进行了缩写,如RtrA缩写为RA,RtrB缩写成RB,以此类推。
表2-4列出了图2-17所示的OSPF网络内每台路由器的链路状态数据库。该表由不同的部分组成,每一部分代表了图2-17中各台路由器的链路状态数据库的内容。Router ID一栏标明了每台路由器,并且链路状态数据库是根据OSPF以自己为树根建立数据库的顺序组织的。紧接着的Neighbor一栏包含了根路由器所直连的其他所有路由器(也就是根路由器的邻居)。最后一栏Cost,指示了从根路由器到达邻居的开销。
例如,路由器A(RA)拥有3个邻居:B、D和E,到达B的开销为2,到达E的开销为4。
![]()
![]()
此时,距离网络到达收敛状态还相差甚远,因此接下来需要执行完整的SPF计算过程。路由器所运行的SPF算法实际上是由Dijkstra算法演变而来的。执行该算法的前提是需要路由器已经建立了一份链路状态数据库,如表2-4所示。下面的步骤描述了SPF算法的过程。
1.首先,路由器将自己作为SPF树的根,以便开始创建对应的SPF树数据库(见图2-6)。当路由器成为根,则去往最近的邻居——自己的路径开销为0。
2.将链路状态数据库中描述去往根路由器邻居的所有条目都添加到候选数据库(candidate database)中1。
注意
候选数据库是OSPF在执行SPF运算过程中所建立的临时数据库。该数据库具备可操作性,用于加速SPF条目的计算并帮助获得最终路由。
3.在候选数据库中,从根路由器去往每一台路由器的开销都已经通过计算得出。因此,在候选数据库中去往给定目的路由器且拥有最低开销的条目将被放置到树数据库(tree database)中。如果从根到同一目的路由器拥有两条或更多相同开销的条目,那么随机选择一条2。
注意
树数据库是根路由器在候选数据库上运行SPF算法的结果。当算法运行完成后,SPF树数据库中将包含最短路径(也就是最终的路由条目)。
4.对已经被加入到树数据库中的路由器的邻居 ID 进行检查。除了那些已经存在于树数据库中的邻居 ID 条目以外,将链路状态数据库中描述剩下的路由器邻居的信息添加到候选数据库中。
5.如果候选数据库还拥有条目未被移至树数据库或丢弃,那么转至步骤3。当候选数据库为空时,SPF 算法停止。当 OSPF 区域内的每一台路由器的条目都进入了树数据库后,即表明SPF计算执行完毕并成功。
表2-5总结了为图2-17所示的网络应用Dijkstra算法,并以RA为SPF树根来建立最短路径树的过程和结果。
表2-5中,每一行代表了网络收敛所经历的各种过程。其中第一列给出了候选数据库的条目;在计算完成后,这些条目将会移至树数据库中或者被丢弃。Description一列对所每一个步骤的执行进行了解释3。
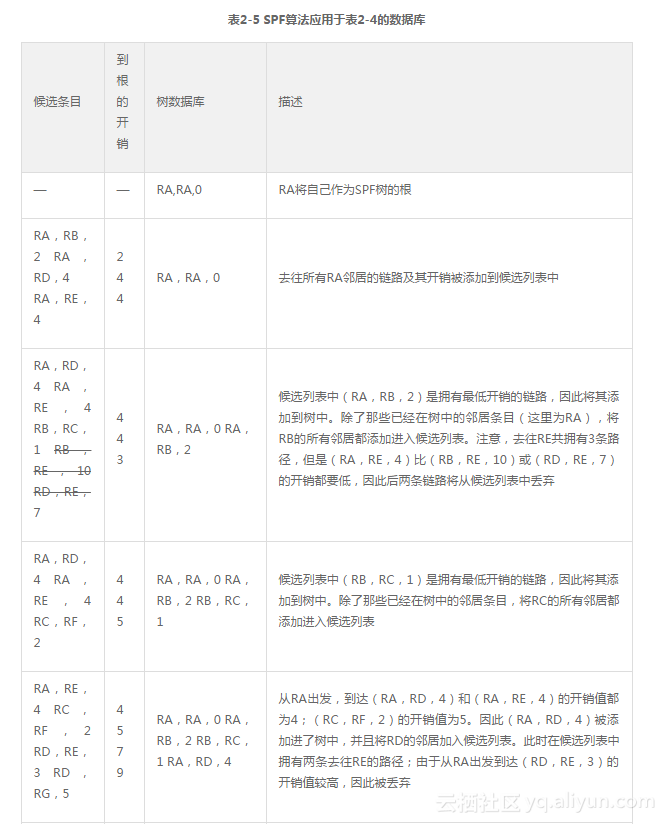
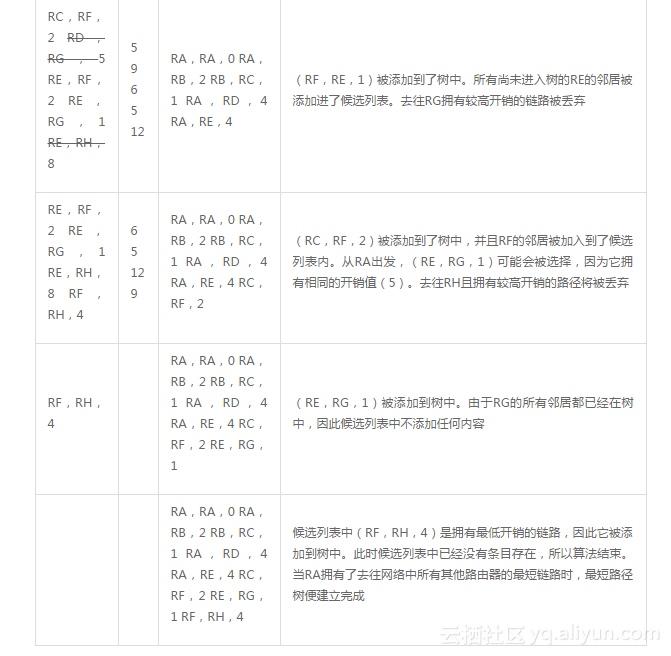
候选列表中(RF,RH,4)是拥有最低开销的链路,因此它被添加到树中。此时候选列表中已经没有条目存在,所以算法结束。当RA拥有了去往网络中所有其他路由器的最短链路时,最短路径树便建立完成
图2-17中的RtrA在表2-5中列出的链路状态数据库上运行 SPF 算法,得到最终为RtrA所创建的最短路径树,如图2-18所示。当每台路由器都通过运算得到了自己的最短路径树后,它们便可以根据最短路径树获知其他路由器的链路信息,并非常容易地为 SPF 树添加末节网络。根据这些信息,路由器便能够将条目添加进路由表。
![]()
1译者注:在某些资料中候选数据库也被称为TENT列表。
2译者注:在某些资料中,树数据库也被成为PATH列表。
3译者注:表2-5中使用了(路由器1,路由器2,开销)的三元组来表示一段链路。例如,(RA,RB,2)表示从RA到RB的链路的开销为2。