关于Ceph的名篇。Ceph是现在很火的一个存储系统,不同于HDSF主要是面向大数据应用,Ceph是立志要做一个通用的存储解决方案,要同时很好的支持对象存储(Object Storage),块存储(Block Storage)以及文件系统(File System) 。现在很多Openstack私有云的存储都是基于Ceph的。Ceph就是基于这篇论文做得。
摘要
很明确的指出了Ceph的使命:
We have developed Ceph, a distributed file system that provides excellent performance, reliability, and scalability.
以及关键方法和技术:
Ceph maximizes the separation between data and metadata management by replacing allocation tables with a pseudo-random data distribution function (CRUSH) designed for heterogeneous and dynamic clusters of unreliable object storage devices (OSDs).
We leverage device intelligence by distributing data replication, failure detection and recovery to semi-autonomous OSDs running a specialized local object file system.
A dynamic distributed metadata cluster provides extremely efficient metadata management and seamlessly adapts to a wide range of general purpose and scientific computing file system workloads.
然后就是性能
Performance measurements under a variety of workloads show that Ceph has excellent I/O performance and scalable metadata management, supportingmore than 250,000metadata operations per second.
介绍:
先把NFS和传统OSD的问题说了一下。
然后介绍Ceph:
We present Ceph, a distributed file system that provides excellent performance and reliability while promising unparalleled scalability.
这句是一个关键:Our architecture is based on the assumption that systems at the petabyte scale are inherently dynamic: large systems are inevitably built incrementally, node failures are the norm rather than the exception, and the quality and character of workloads are constantly shifting over time.
Ceph的架构如下:
系统介绍:
Ceph分3部分:
the client, each instance of which exposes a near-POSIX file system interface to a host or process;
a cluster of OSDs, which collectively stores all data and metadata;
A metadata server cluster, which manages the namespace (file names and directories) while coordinating security, consistency and coherence (see Figure 1).
如下图所示: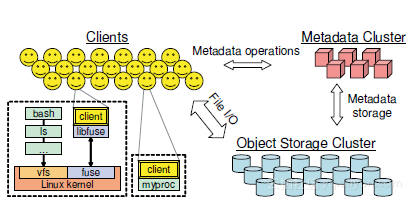
主要做法:
Decoupled Data and Metadata
Dynamic Distributed Metadata Management
Reliable Autonomic Distributed Object Storage
后面几章是对每部分具体实现的介绍,没有什么太高深的公式和理论,大家一般都能看明白,挺有意思的。
原文链接:
http://www.ece.eng.wayne.edu/~sjiang/ECE7650-winter-15/topic5B-S.pdf
如果下不了可以去百度学术上再搜一下。