Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.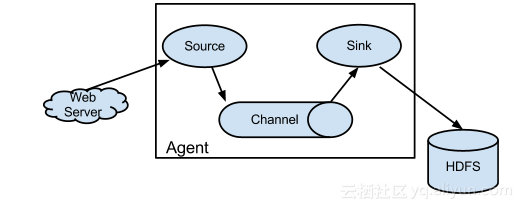
安装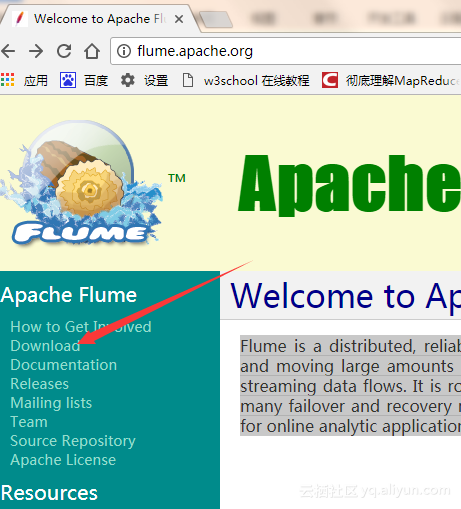
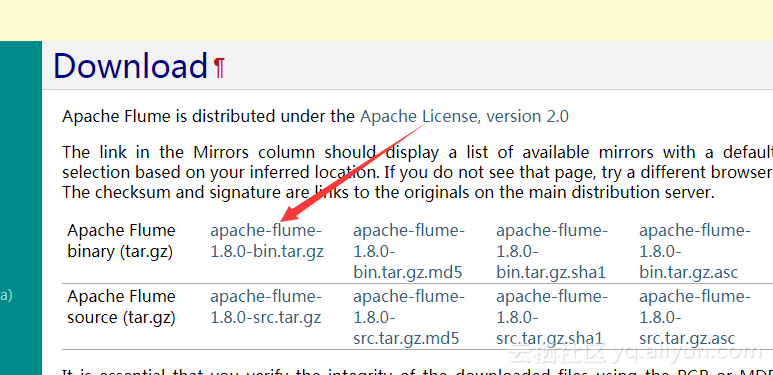
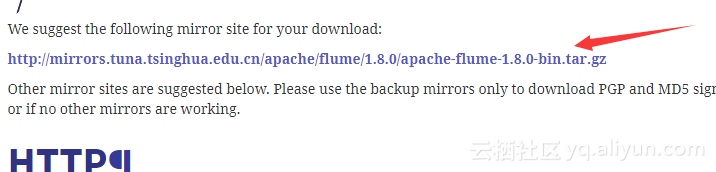
将下载的flume包解压到你要保存的目录下
修改flume-env.sh(在Flume文件下的conf里)
cp flume-env.sh.template flume-env.sh
解注释JAVAHOME
JAVA_HOME=/usr/lib/jvm/java-XXX
修改配置文件
添加flume以及bin目录到/etc/profile里
使用flume-ng version验证是否安装成功
时间: 2024-11-02 03:10:22