本文讲的是微服务的持续集成,四步“构建”一个代码世界,大师Martin Fowler对持续集成是这样定义的:持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。
今天我们就来聊一聊微服务的持续集成。
目录
一、持续集成之构建
二、持续集成之部署
三、持续集成之测试
四、持续集成之发布
五、总结
一、持续集成之构建
当微服务产生后,持续集成也不得不考虑起针对这种可以独立部署的服务,当有十多个微服务同时运行甚至更多的时候,如何建立起与之的映射,即微服务、CI构建与源码的映射变得极为重要,如果还像简单软件那样集中管理是否还行得通,那可能会是一场灾难?在如此复杂的背景下,优良的持续集成方案同样也会给我们带来焕然一新的便利体验。
在此,我们就先了解下微服务架构下的三种持续集成构建模式。
1. 一个代码库、一个CI构建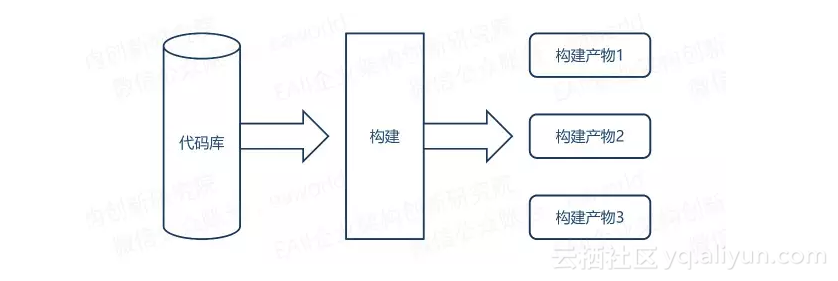
这种方式就是将所有的微服务放在同一个代码库中,并且使用一个CI构建。这么做唯一的好处就是只需要管理一个代码库,但随之而来的麻烦会让你应接不暇。每当我们修改一个服务中的一行代码后,我们必须重新构建所有的服务,所有的构建产物都是在同一个构建中完成。
事实上其他的服务完全没有重新构建的必要,这样大大延长了上线速度。而在众多构建物中要找出保证能够让你修改生效的服务来部署,也是足够让人头疼了,这导致最终让我们选择重新部署所有代码。再试想一下,所有人共享一个CI构建,每个人的修改都有可能造成CI的构建失败,想要将这个CI构建成功稳定下来,头痛又升级了。
在众所周知的谷歌使用的就是一个代码库,然而他们采用了自己的版本管理系统“piper”来管理超过20亿行代码的超级大库,所以对于更多的小公司来说,谷歌就是一个特例。
2.一个代码库、多个CI构建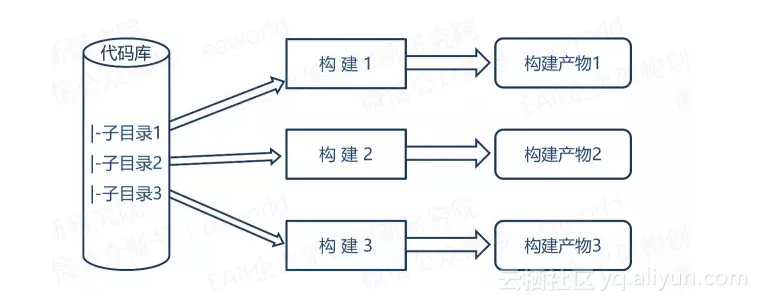
在这种方式中,代码库还是那个代码库,不过在代码库中我们创建了多个子目录,每个子目录对应一个CI构建。现在的很多项目中都会采取这种持续集成,这让我们可以比较方便的同时提交对多个服务的修改。
然而,来让我们琢磨一下这种方式依旧会存在的弊端,随着代码修改的增加,无可避免的会在不经意间造成服务耦合度的增加,当部分代码出现问题的时候受到影响的很可能是多个构建。
3. 多个代码库、多个CI构建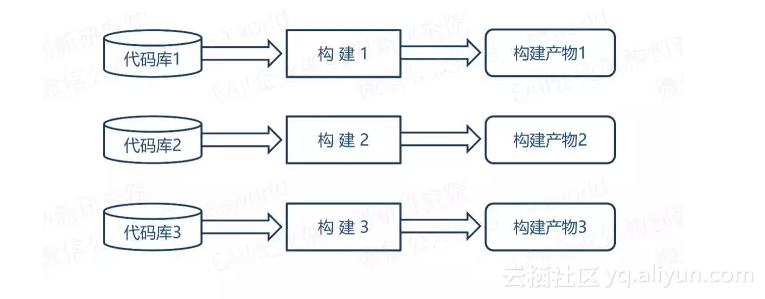
每个微服务都有一个对应的代码库,每个代码库对应一个CI构建。这时候每个微服务变得独立,修改运行部署不再相互依赖,大大降低了耦合度,方便了代码的管理和维护。另外多代码库还给我们带来另一个好处,就是共享问题,当你只有一个代码库的时候,如果想要共享,那必然所有代码都必须共享,拆分多个代码库,这样根据自己情况,你可以选择性的共享代码。当然,你又要说了,跨服务的修改变的麻烦了啊。没错,这也不是一个十全十美的方案。
对于很多采用CVS或者SVN的代码库来说,可能第二种方案已经习以为常。而对于Git代码库,划分多个代码库更加合理更加易于管理。
针对微服务架构,我们采用了多个代码库多个构建的方案。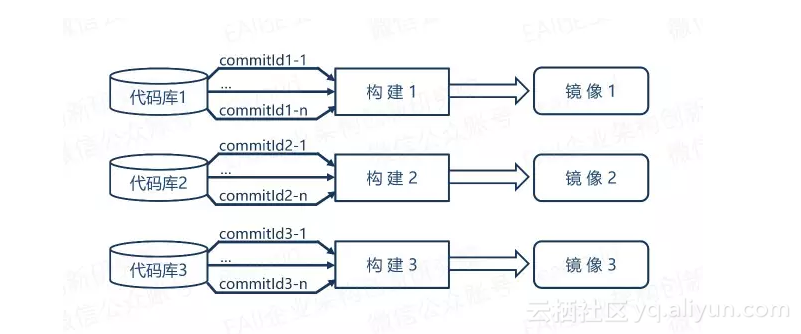
当我们创建一个微服务时,会产生一个git代码库,虽然我们每个微服务可以创建多个版本,但是我们是不可以同时编辑多版本的,因为我们开发代码是在git库master支线上,当一个版本发布后我们会给这个发布的版本打一个分支,这时候我们才能编辑新的版本。
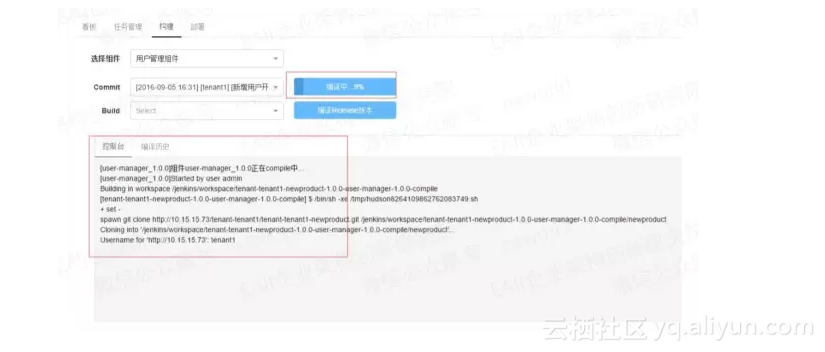
所以我们的CI构建就映射到一个微服务版本中,每个微服务代码提交代码库时会产生一个commitId,通常我们会针对这个commitId来进行一次构建,因此代码库分治也一定程度上避免了commitId不能与某个微服务对应的问题。对于微服务的持续集成,每次构建编译结束,产物可以是一个完整的镜像。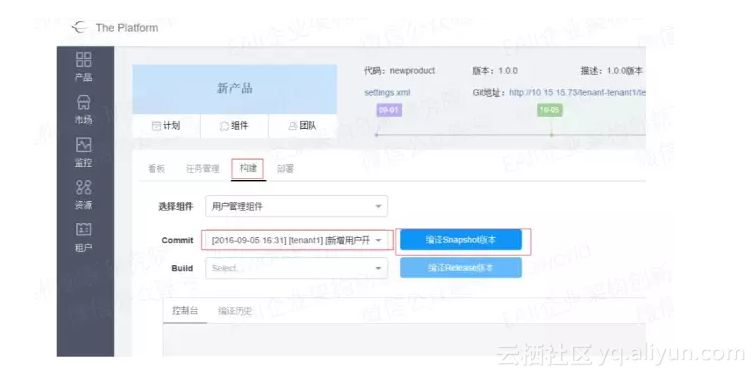
对于微服务持续集成这里可以分为snapshot版本的构建和release版本的构建。
Snapshot版本可以理解为日编译,以及开发和测试期的编译构建,构建时要选择对应commitId的代码进行构建。
Release版本就是产品发布前的编译构建,需要选择具体的build号,每次Snapshot版本编译完成都会生成build号。
二、持续集成之构建
微服务的开发我们通常会遇到一个比较麻烦的问题,在每个微服务中不可避免会有众多的配置项,也许每当我们换一个环境,就会有这样那样的不同微服务的配置需要修改,这不仅是一个工作量的问题,这也会给操作人员带来烦躁感,甚至出现遗漏某些配置的修改。
在部署的环节,可以做一个配置项的功能,在页面中修改或增删每个微服务的配置项,这样给每次微服务的部署提供了极大的便利。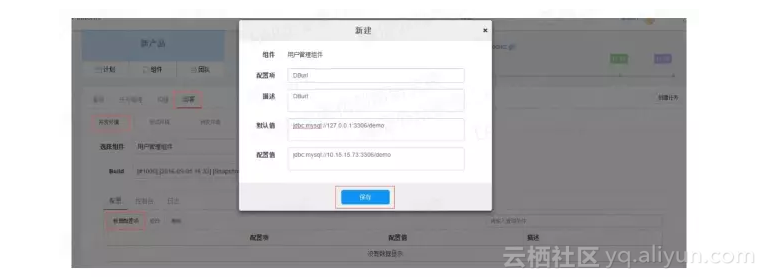
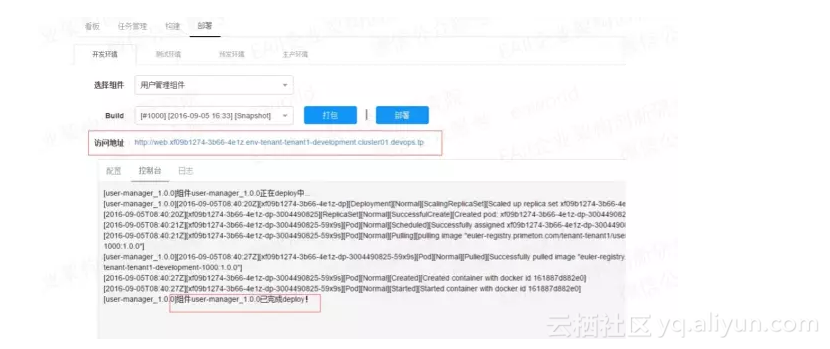
选择Build号,对产品进行打包操作。打包时会显示打包进度及控制台信息。打包成功后部署,部署时会显示部署进度及控制台信息。部署成功,页面会显示访问地址,开发人员可以点击访问地址进行自测。
三、持续集成之测试
在敏捷软件测试中,将测试的类型分为四种:验证测试、单元测试、探索性测试、非功能性测试。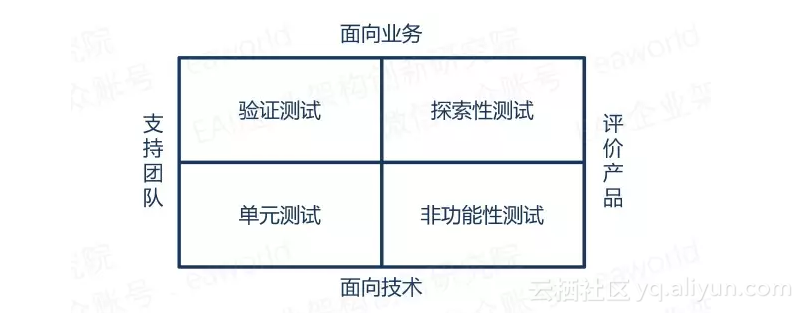
验证测试:是否实现了正确的功能?
探索性测试:可用性测试,如何破坏系统功能
单元测试:是否正确实现了功能?
非功能性测试:响应时间、可扩展性、性能测试、安全测试
处于象限顶部的测试是面向业务的测试,大部分的验证测试以及探索性测试都习惯于手工测试,而处于象限底部的面向技术的测试,则大部分都可以形成自动化测试。这里我们着重说的是自动化测试么毕竟在微服务的道路上,不能解决自动化的问题,无法很好的体检微服务架构带来的好处。更多关于测试类型的内容可以参考《敏捷软件测试》。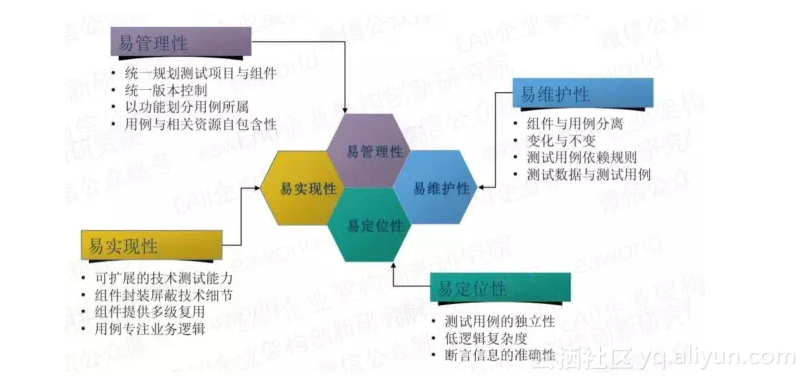
自动化测试毕竟不同于手工用例,我们从四个方面定义了自动化测试的设计原则与方法:
易管理性
统一规划、统一版本控制的规范要求;
易实现性
采用分层设计,测试基础服务层、测试能力支撑层、测试组件层、测试用例层,支持多种技术的测试能力,测试组件复用,用例专注业务逻辑;
易维护性
组件与用例分离、区分变化与不变、测试用例原则上不互相依赖、测试数据容易维护;
易定位性
测试用例独立、低复杂度、要求断言信息的准确性。
更多关于微服务自动化测试的内容可以详见《DevOps之自动化测试》和《微服务流程自动化测试》,今天主要说一下mock给持续集成持续测试带来的便利。
首先我们来看下微服务下的持续测试流程。
开发人员自测通过,在任务管理中,选择已经完成的功能单任务,已经编译过会显示相应的Build号和编译日期,自测完成任务状态更改为“已完成”。
项目经理查看计划单任务中相关功能是“已完成”状态,在计划任务中增加任务编译信息,并修改计划单任务的状态为“测试”,并创建测试单任务,可以指派给相应测试人员。
测试人员查看分派给自己的测试单任务,记录任务编译中的Build,修改状态为“进行中”,测试人员首先需要将测试环境与发开环境同步,即在测试环境打包部署与测试任务中发开环境相同的构建。
测试人员发现测试缺陷后创建缺陷单任务,指定给相关的开发人员,验证通过则将任务状态改为“验证通过”。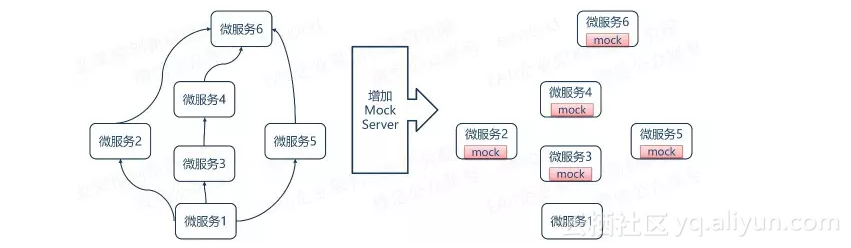
MockServer的设计思想在于将接口的操作和数据的操作分离,在实现桩程序时,只考虑对各种通信接口的包装,而将【条件】和【结果数据】的构造交给使用者。这样,同样一个桩程序,只要是基于相同的通信协议,就可以模拟出任意的行为,就像mock对象可以模拟任意对象的行为一样。
对于微服务框架而言,在开发或者测试一个微服务领域的时候,对其它微服务领域的实现细节是不可知的。但是,我们在测试各个微服务领域的SPI以及Service的时候,却又需要在启动依赖的微服务领域系统。导致我们做单元测试的时候,如果想要跑完测试用例,就必须要把依赖的所有系统启动起来。
这个时候,如果结合Mock Server,用mock data模拟微服务间的交互数据,就可以绕开对其他微服务领域系统的依赖。提高测试覆盖率以及效率。
四、持续集成之发布
持续集成的发布:确定开发、测试SignOff,创建预发任务,验收计划,验收产品版本,打Tag,发布上线。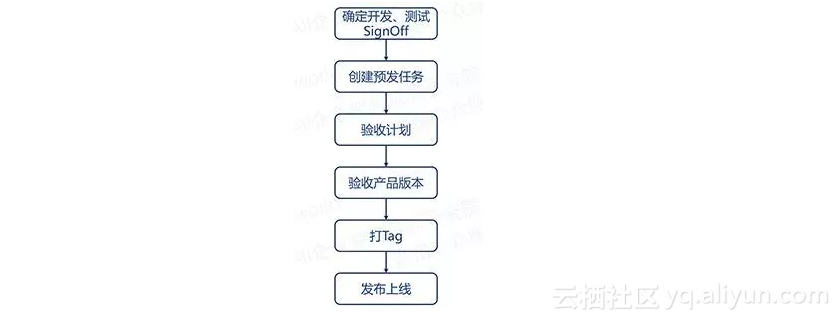
这里需要提到的是在很多时候我们发布前都会去锁定代码库,但是在当前的过程中不需要。
开发人员开发代码的时候将代码库中master的代码fork到本地工作空间,经评审后提交master代码库,每次对于代码库的更改会产生commitId,每次构建时选择相应commitId对应状态的代码进行编译构建,每次构建完成产生build号,而我们的预发编译可以选择某个build号对应状态的代码进行打包部署。而我们每次发布版本后都会打一个新分支。故此不用再锁定代码库。
五、总结
当微服务的出现,你是否觉得多代码库的git库更利于代码的管理呢?针对git库的结构你是否觉得多代码库多构建的方式更好呢?部署配置的灵活性在微服务的交互上是否变得更加灵活了呢?发布中不用再封闭代码库是不是减少了维护成本呢?相信你或许在我的文章中已找到了自己的答案。