排查和诊断需要统计工具?
排查和诊断过程,就是数据处理过程。
有时候只要处理过程探索到一个信号出现了就足以确定致因和解决问题了,至少也会得到进一步的线索。比如,客户ECS并发访问量上不去,如果发现对进程能打开多少文件描述符有限制。那么,我们差不多就确定了致因,对于如何解决问题也有了答案。
我们可以把上面排查和诊断的过程规范化为基于数据回答问题的过程。对这个过程,我们的预期是找到一个信号,这个信号可以确定致因,同时也对解决问题给出线索或者依据。比如,上面的例子,我们就是基于ECS的系统日志、业务日志和运行时信息来回答“为什么并发量上不去”问题的过程。过程的结果是我们找到了进程能打开文件描述符数量受限这个信号。
如果就问题和致因信号关系而言,上面提到的例子是简单的。因为问题和信号出现与否有关,是非此即彼的关系。简单计,我们把这种关系称之为“二进制关系”。也就是说,信号出现,就会导致问题。这种情况下,简单的cat、grep命令探索数据,搜寻确认信号出现与否就足够了。但是,如果问题和信号之间的关系不是这种非此即彼的二进制关系,比如,是和信号出现的频率有关系。这种情况下,如果信号往往是在数天甚至几周内都有出现,即使我们基于经验能够把信号和问题联系起来,可能也不易让客户接受我们的排查和诊断过程以及结论,而且仅凭经验,也有不小的误判概率。
更为复杂的情形可能是问题和数据中某些信号集合的某些整体的特征相关。这些特征不使用工具统计汇总就无法被识别和确认。比如,与某个信号在一分钟内连续出现的频率有关,而与一分钟内出现的、总的次数关系不大。这种情形下,直接的观察是很难处理的,尤其是数据量比较大时。因此,我们需要工具改善排查和诊断过程。
对于因果之间没有简单对应关系的情形,抽象模型和处理方式,无论是理论还是实践,都是种类繁多。这里我们只介绍和引入传统的统计手段。
什么是R以及为什么选择R?
大多数编程语言,在其是否图灵完备的意义上,是没有区别的。但是,不同语言提供的抽象支持,在生产力和软件工程方面却相差悬殊。比如,把一个文件的内容输出到终端上,使用cat命令,估计简单了解过UNIX环境的工程师都可以;但是用汇编语言来做,估计得难道一大片。
那么,什么是R呢?学究一点,R是以统计处理为其领域的编程语言和平台。通俗一点,R是一个统计工具。就是说,R是围绕着统计来提供其抽象的,正如C++、Java、和Ruby是围绕对象来提供抽象的。
但是,对于诸多统计软件平台,就易用性和学习曲线而言,诸如SPSS和SAS等商用软件无疑是占有优势的。而开源软件,也不止R一家。比如Python社区就提供了多种实现供选择。而且现在还有Figaro,自称
Figaro is a probabilistic programming language that supports development of very rich probabilistic models and provides reasoning algorithms that can be applied to models to draw useful conclusions from evidence. Both model representation and reasoning algorithm development can be challenging tasks.
那么,我们为什么选择R这个平台呢?
首先,R是S语言的一个开源实现,S出身AT&T。因此R可以和UNIX经典工具等适配使用。
除此之外,在某种意义上,你可以把R看成是实现了M-expression的Scheme的一种实现。你在函数式编程里看到的各种玄妙都可以在R中尝试一番。
再者,R提供了强大的绘图能力。一图胜千言,尤其是在和客户交流时。
最后一点,有众多的以R为主题的出版书籍;google内部大规模使用了R;微软在其产品里直接支持R。
因此,R是个不错的选择。其作为语言既有命令式语言的语法,又有函数式编程的核,又因其目标领域是统计,因此又能改变你的思考方式 ,加之重量客户的投入,可以预期你的投资很有保证。如果正在提升自己,或者计划提升自己,为什么不选择R呢?
如何安装、启动和退出R以及安装R包?
R作为开源软件,支持Windows、MacOS和Linux等主流平台,但是官方安装手册只提供了编译安装方式。其实,对于Linux和MacOS,都有软件包管理软件可用,直接通过这样的工具安装即可。
安装
比如,对于MacOS,只要部署了homebrew可用,可以这样安装
brew cask install r-app
对于Linux系统,如果是RHEL-like系统,比如,Fedora或者CentOS(在较新的Fedora中请使用dnf替换yum;CentOS中需要部署EPEL的源),可以这样安装
yum -y install R
对于Debian/Ubuntu,可以这样安装
apt-get -y install r-base
对于Windows(其实也包括MacOS和Linux),其官方网站提供了预编译的二进制包,直接下载安装即可。当然,微软自己也提供了增强版本,感兴趣请到MRAN下载。
除了R,这里也推荐RStudio,R的IDE, 直接下载安装就好。
启动和退出R
鉴于被困在不熟悉的软件中无法退出都成了头条,为了避免恶劣的第一印象,我们对于如何退出R,特意说明下。
其实,如果使用的是图形界面,那么你如何操作浏览器窗口,就怎么操作R的图形界面就好。如果是使用的是终端界面呢?
进入R
R
退出R
q()
使用上面的退出方式,R会要求确认是否保存工作区。如果你想不确认就退出,那么你不想保存,那么
q(save="no")
如果想要保存,那么
q(save="yes")
安装R包
由Perl其,流行的脚本语言都有一个类似CPAN的站点,R也不例外。因此,我们可以按需从CRAN下载、安装需要的包。
在使用图形界面时,可以选择恰当的菜单,填入相应的包名称即可。细节请参考图形界面的帮助页。对于终端用户,可这样处理
install.packages(c("ggplot2", "lubridate"))
R在排查和诊断过程中的位置
R在排查和诊断过程中的位置,可以用韦恩图表示如下。额外说明下这里的“黑客技术”不是指脚本小子或者骇客技术。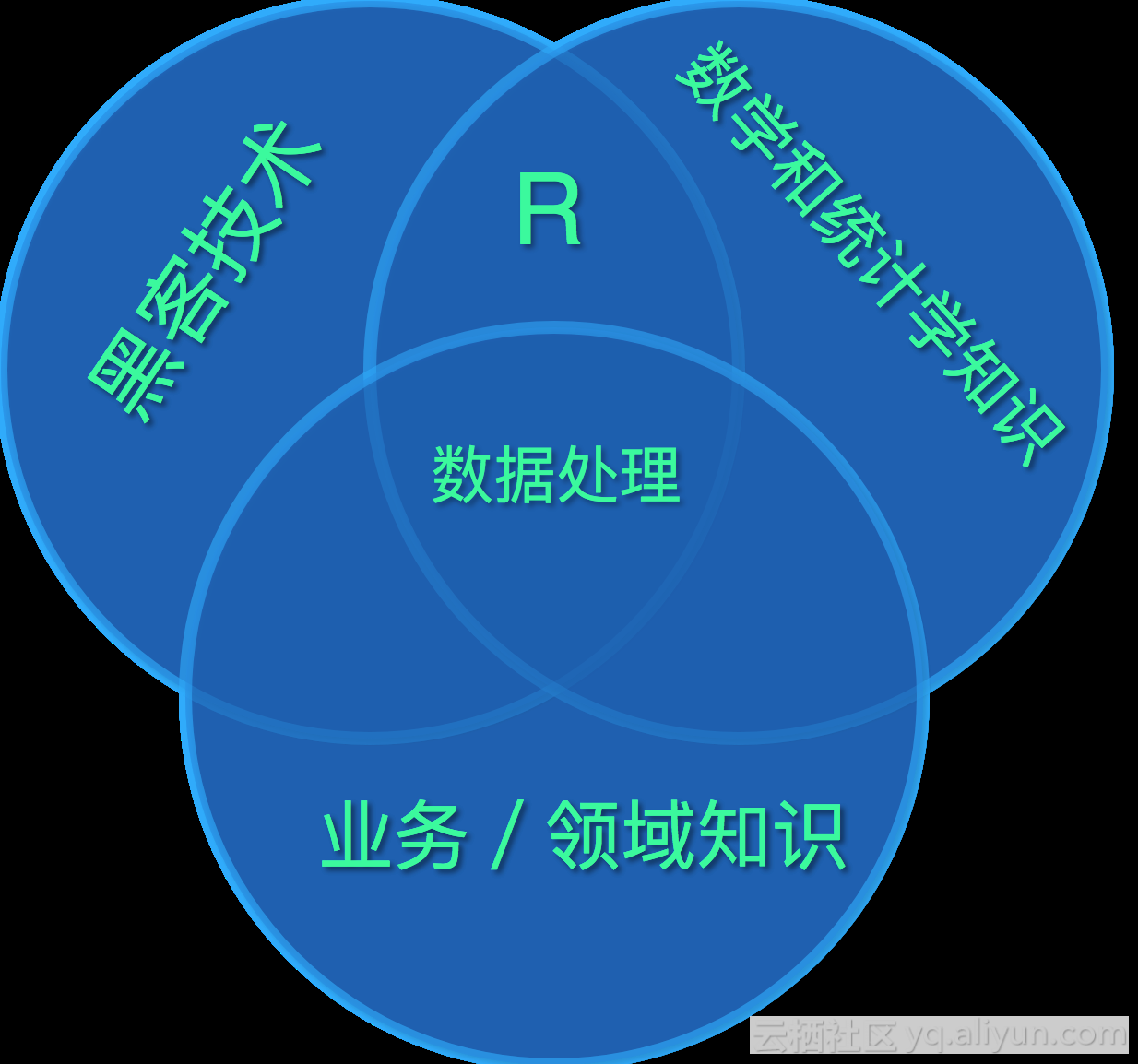
热身准备
安装必需的R包
接下来我们用两个实际排查的case来介绍R。在开始之前,因为后续需要,我们要先安装两个R包。启动R后,请在R中执行如下命令
install.packages(c("ggplot2", "lubridate"))
这两个包,ggplot2用以绘图,lubridate用以处理日期时间。
没有为处理时间日期熬过夜的人不足以论技术。
内容说明
我们用两个实际case来说明R在排查和诊断中的用途以及如何使用之。如何处理的第一个case,我们给出详细步骤。第二个case,从简。
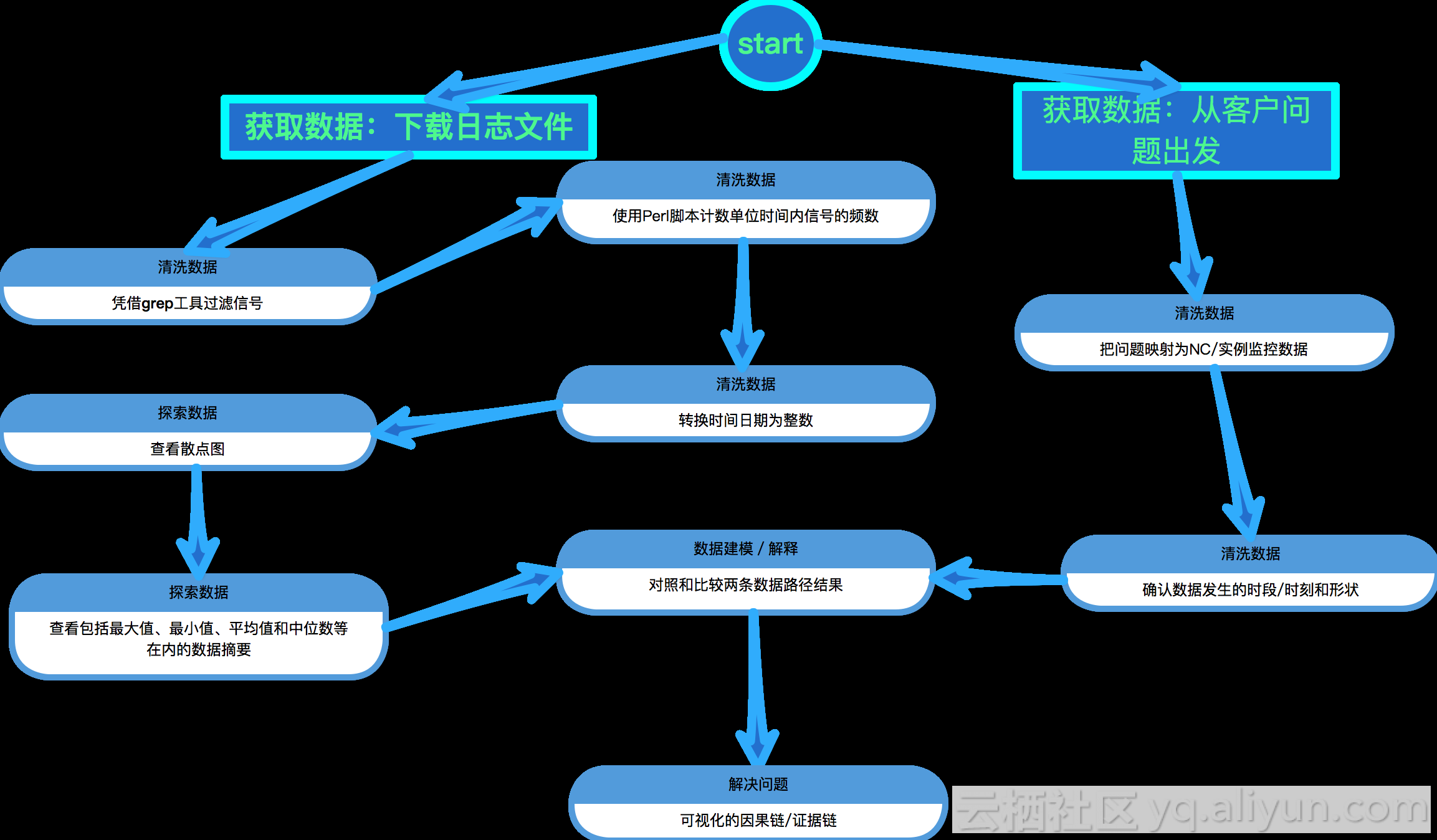
处理流程
通用的数据处理
数据处理,我们以OSEMN为框架
- obtaining data/获取数据
- crubbing data/清洗数据
- exploring data/探索数据
- modeling data/建模数据
- interpreting data/解释数据
具体处理流程
我们把上述通用的处理流程改造如下,后续我们就使用之
第一个case:症状和初步排查
补充说明
因客户误操作,排查用的实例被突然释放了。因此,整个排查过程实际上前后是在两台不同的实例上进行的。这是为什么在此case中,后续部分步骤和数据有时会提到到两台实例。
症状
客户:
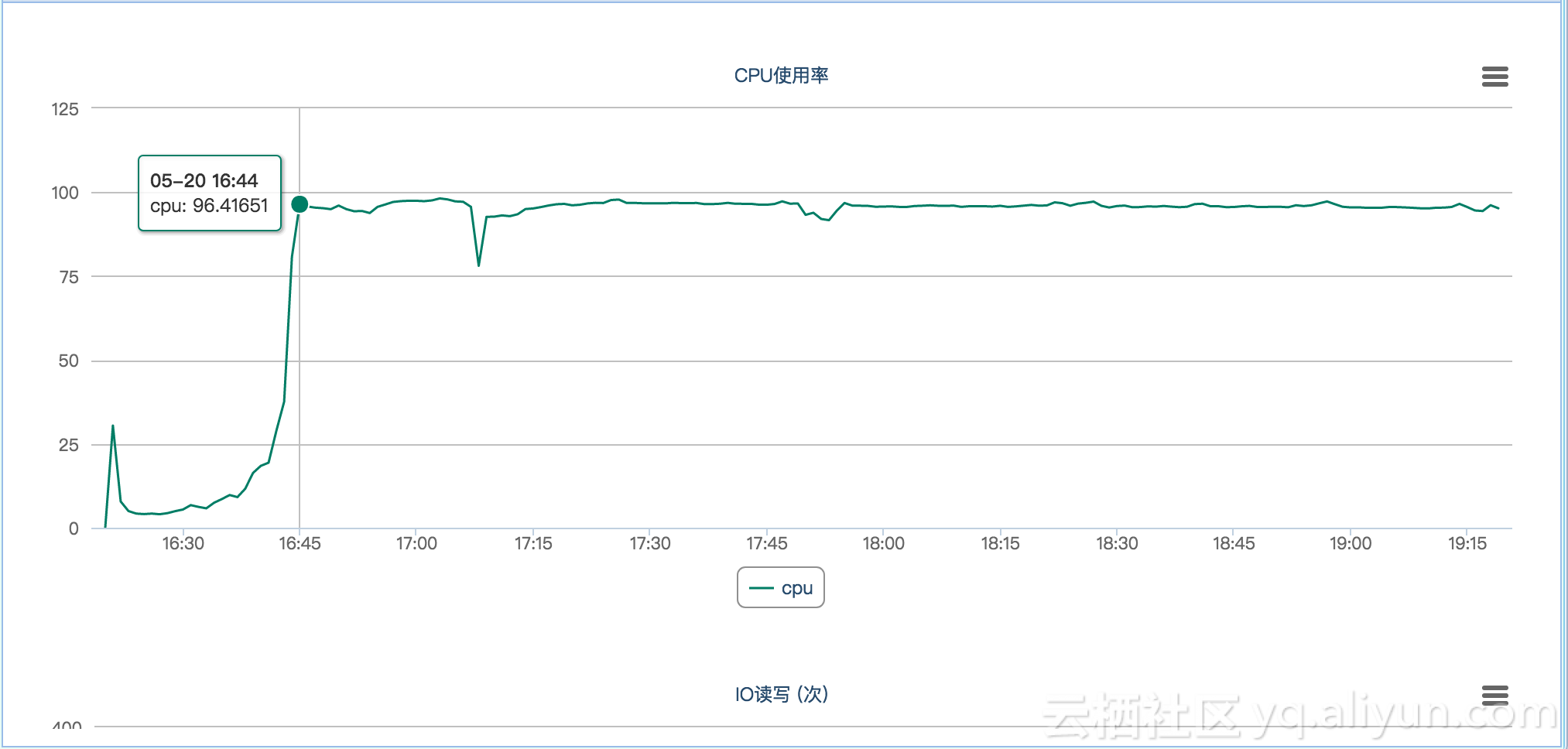
大批量ECS服务器遇到...CPU被打满的问题,主要消耗在cpu_sys上。
相应的CPU监控数据如下
初步分析
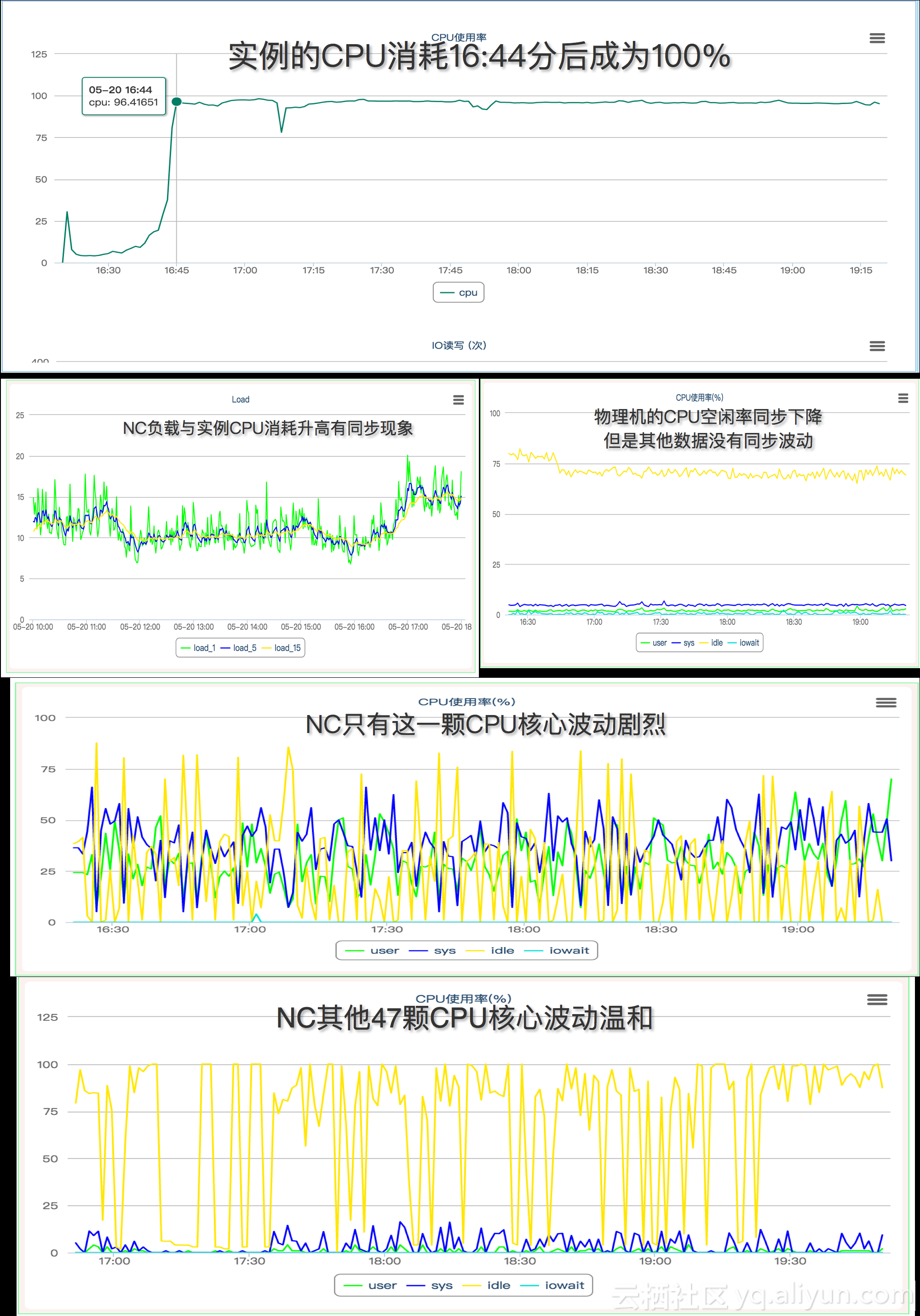
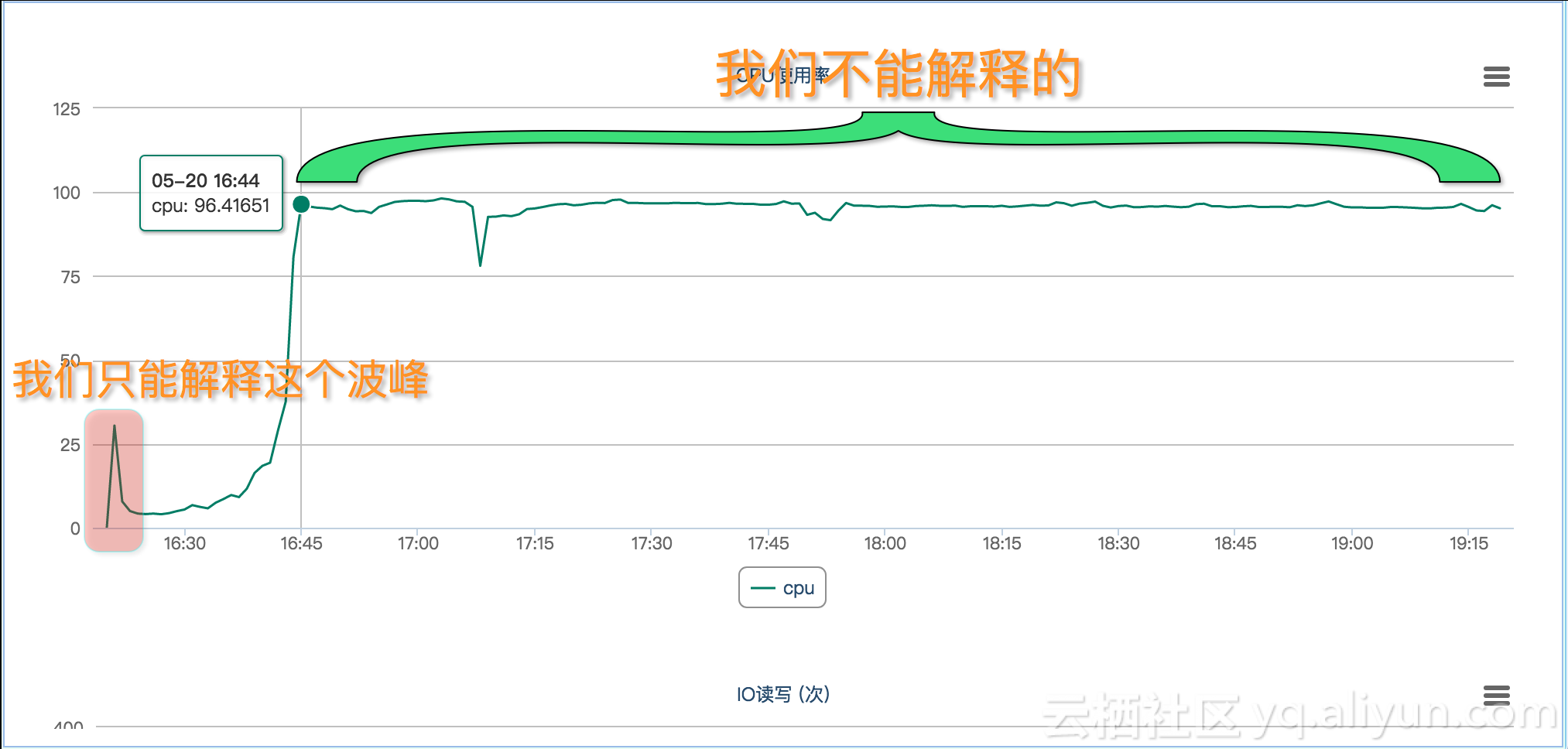
开始我们先排查是不是资源争抢问题。但根据云台的监控数据,我们很快排除了这种可能。物理机有48颗CPU,但是仅有一个CPU波动较大,而且其他47颗CPU的消耗都不高。尽管物理机的CPU的消耗与实例CPU消耗有同步现象,空闲率也同步有所下降,但波动非常轻微,物理机上的总的CPU消耗和负载变动不大。并且总的CPU资源非常宽松。单独CPU的监控数据也佐证了这一点。因此可以断定是客户的业务逻辑导致的其实例CPU消耗较高。因此排查继续。
物理机监控数据如下
第一个case:分析系统日志
因为CPU消耗升高的时间点已知,检查对应时点前后的messages日志,立刻有发现。rsyslog的omkafka插件报告报警信息
Failed to produce to topic 'mkApiNginx' partition 1: Local: Queue full
因此立刻校验rsyslog软件包,看看有哪些东西被变更。结果很快发现/etc/rsyslog.conf配置文件有变更
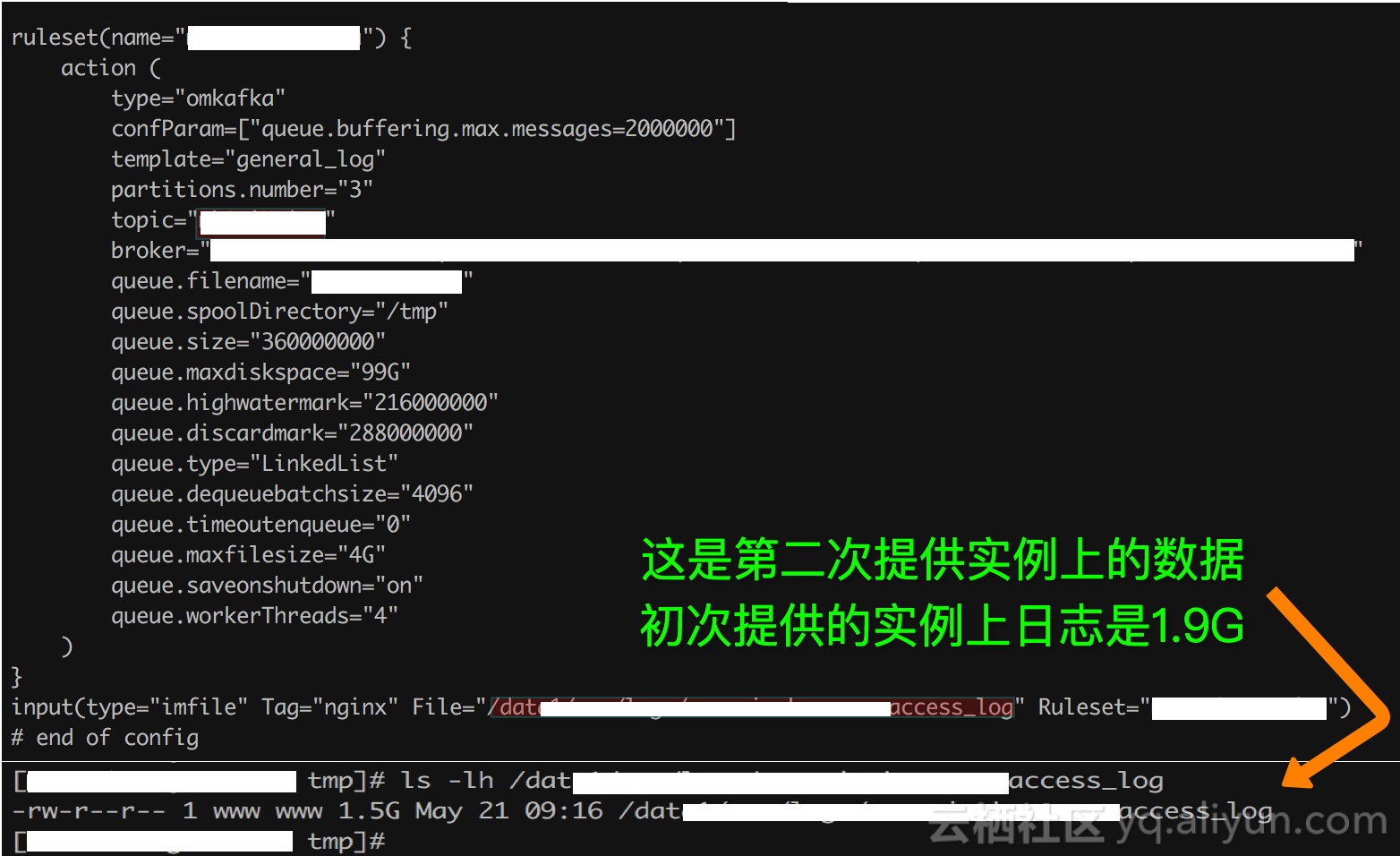
因此,客户的实例应该有一个把G级别日志传递出去的操作。IO/Network的监控数据佐证了这一点
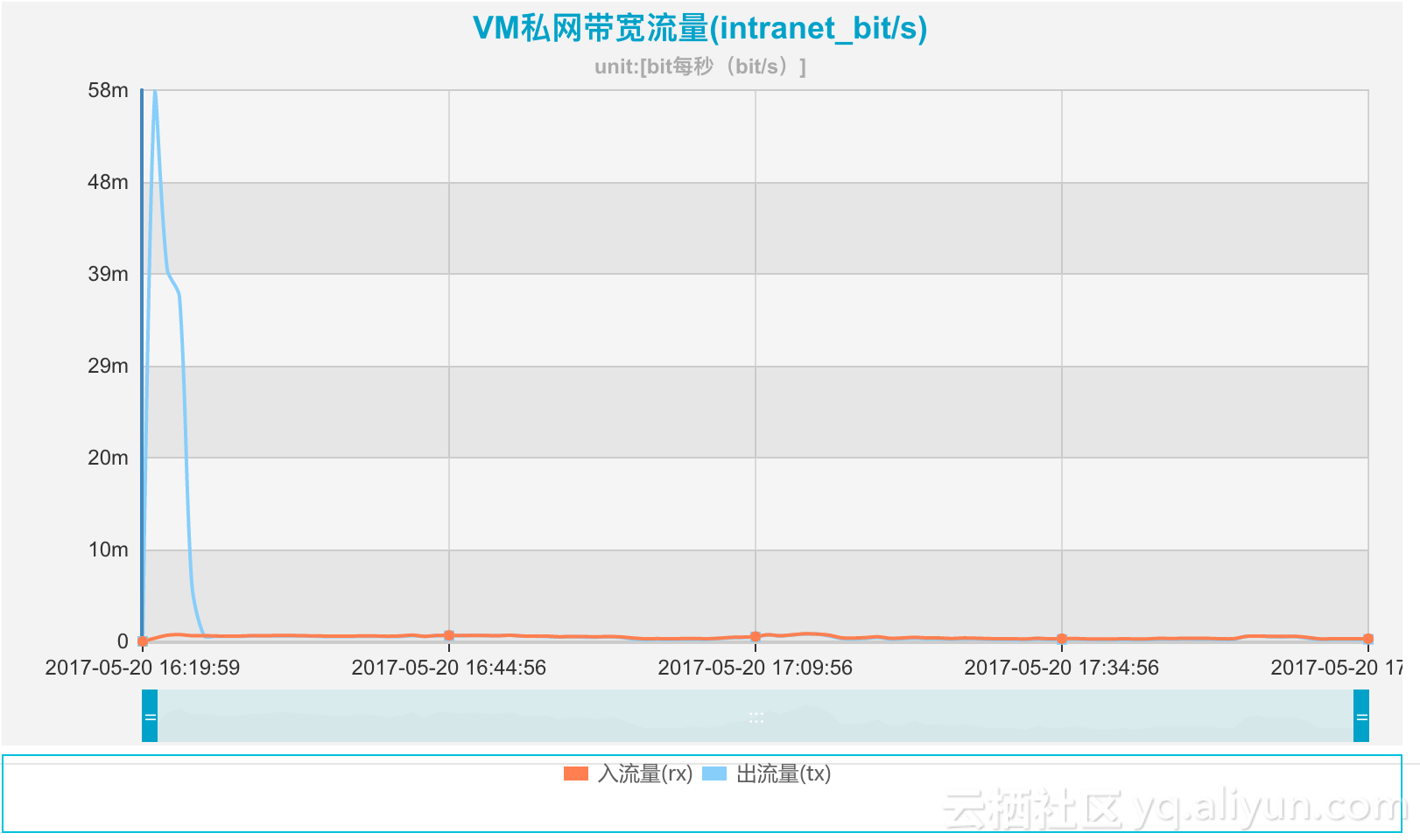
但是,根据时间戳,这个原因只能解释实例CPU很短时间内的一个波动。因此,排查继续。
第一个case:分析业务日志
客户实例上的系统日志没有更多的内容供分析了。所以,接下来我们转向客户的业务日志。因为我们知道CPU消耗高的时间段,因此,需要找出所有的日志逐一核实具体时间段的记录
find / ! \( -path "/dev/" -o -path "/proc/" -o -path "/sys/" -o -path "/var/" \) -name "*log" | less
这里我们给出第二台实例上CPU占用100%的监控数据
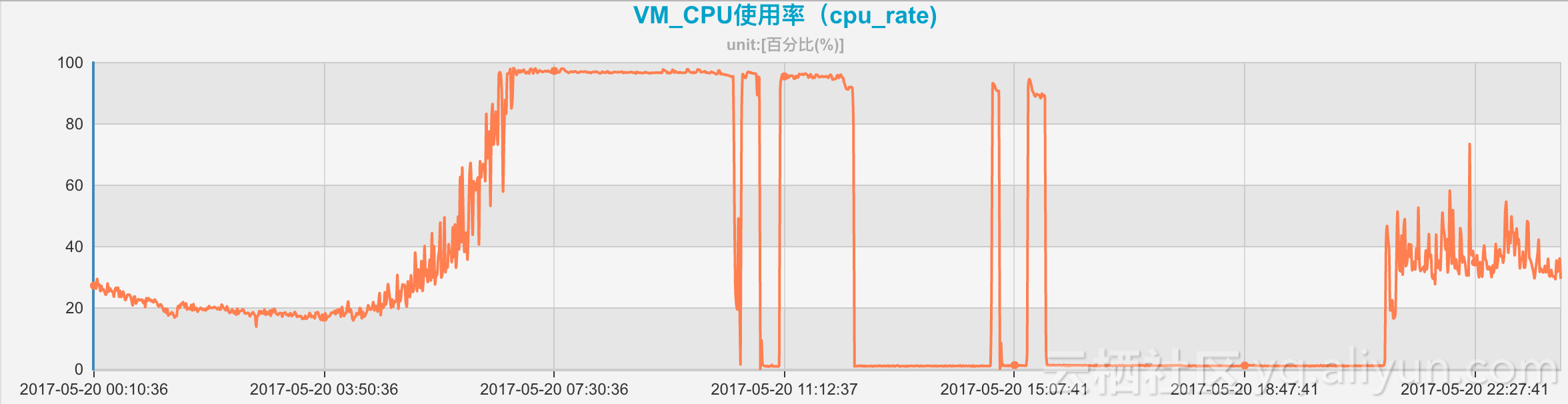
对于找到的文件,我们逐一手工检查其内容,重点是CPU消耗升高的时间点前后。 很快,一个日志里反复出现的超时循环操作引起了我们的注意
但问题是,这个循环从06:40到23:30之间频繁出现,但并不是整个时间段内CPU消耗都高。因此,如何确认超时循环操作和CPU消耗高之间的关系呢?仅凭观察肯定不行了。所以,我们引入R。
数据获取和数据清洗
我们先把日志下载到本地, 而后我们先清洗数据。
首先过滤出所有的超时循环
grep 'Yar_Concurrent_Client::loop():' warning.log > clean_data
接着,用filter.pl脚本把一分钟内每次连续执行的次数统计出来
#!/usr/bin/perl
use strict;
use warnings;
use feature qw(say);
my $curr = q[];
my $prev = q[];
my $count = 0;
while (<>) {
chomp;
next if (!m!Yar_Concurrent_Client::loop! || m!^$!);
m!\[2017-05-20 (\d\d:\d\d):\d\d\]!;
$curr = $1;
if ($prev eq q[]) {
$prev = $curr;
$count = 1;
}
if ($curr eq $prev) {
$count++;
} else {
say qq[$prev $count];
$prev = $curr;
$count = 1;
next;
}
}
# to print the last record
say qq[$curr $count];
脚本执行效果如下
但是,对于00:19这样的时间表示,R中处理起来不方便。我们进一步把时间转换成数字
perl ./filter.pl clean_data | perl -nE 'chomp;m!^(\d+):(\d+)\s+(\d+)!;my $date=$1*60+$2;say "$date $3"'
脚本执行效果如下

我们把获取的数据放到一个文件里,并且给数据列加上名称以便在R里操作
echo 'Date Freq' > data
perl ./filter.pl clean_data | perl -nE 'chomp;m!^(\d+):(\d+)\s+(\d+)!;my $date=$1*60+$2;say "$date $3"' >> data
这样我们就拿到了数据,可以继续操作了
数据探索
尽管为处理方便计,我们已经把时间转为数字,但是显示结果时最好还是看到HH:MM形式的时间,更为方便。因此,我们给R提供一个格式化
函数
timeHM_formatter <- function(x) {
h <- floor(x/60) %% 24
m <- floor(x %% 60)
lab <- sprintf("%02d:%02d", h, m)
return(lab)
}
另外,为方便R操作,我们还做一下当前目录和本地化设置。为美观计,我们直接使用ggplot2包。
setwd("./R/case1")
Sys.setlocale(locale="zh_CN.UTF-8")
library(ggplot2)
首先,加载数据
CPU_OCUPATION = read.table(file="./data", header=TRUE)
我们先粗略地看看数据分布的情况
summary(CPU_OCUPATION$Freq)
收获不多

再通过散点图看看
qplot(CPU_OCUPATION$Date, CPU_OCUPATION$Freq) +
geom_point(colour="red") +
scale_x_continuous(name="date", breaks=seq(0, 1500, by=80), labels=timeHM_formatter) +
scale_y_continuous(name="loop density", breaks=seq(0, 120, by=5))
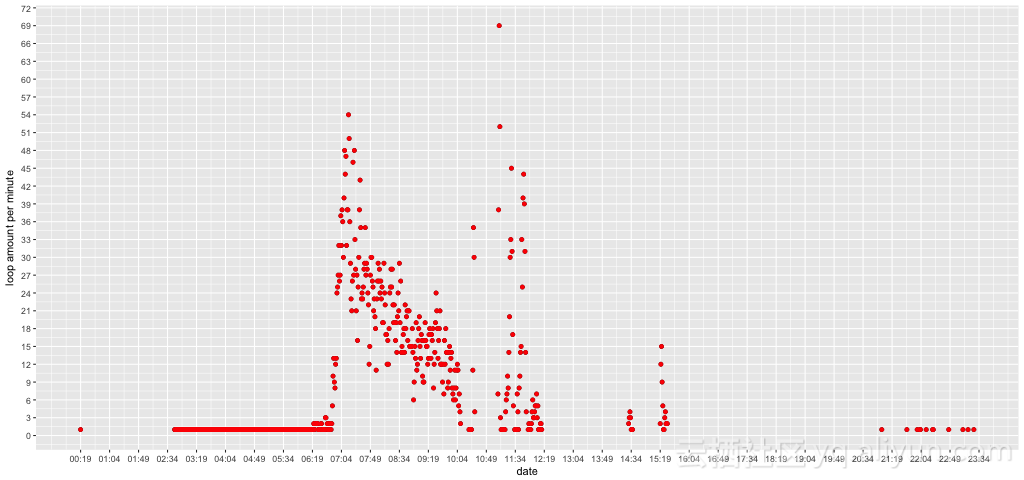
仔细和CPU消耗的监控数据比较,会发现CPU消耗高在时间段,也是散点图的热点区域
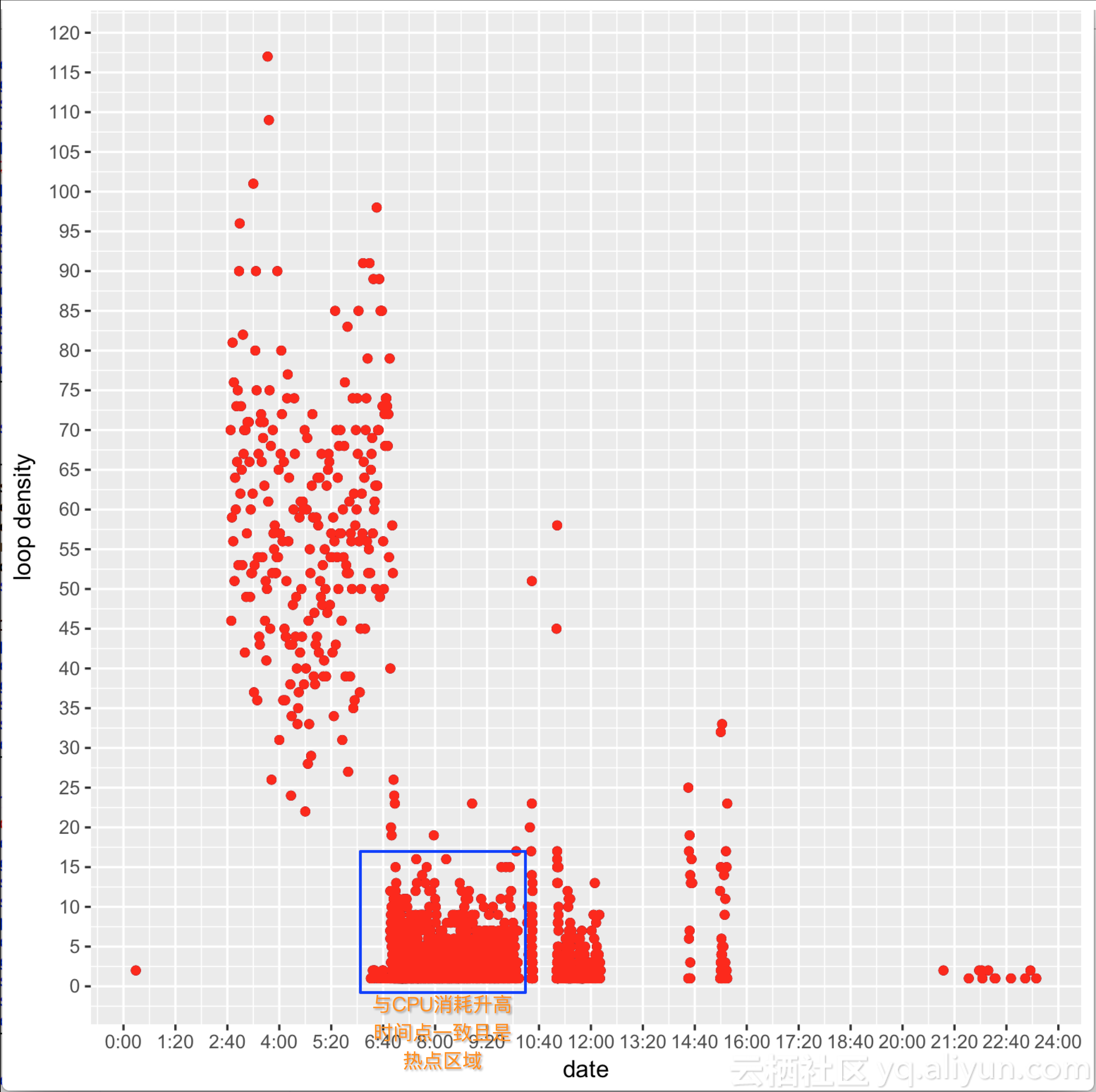
有了这个发现,根据时间段,我们能够确认CPU消耗高和散点图的热点是一一对应的
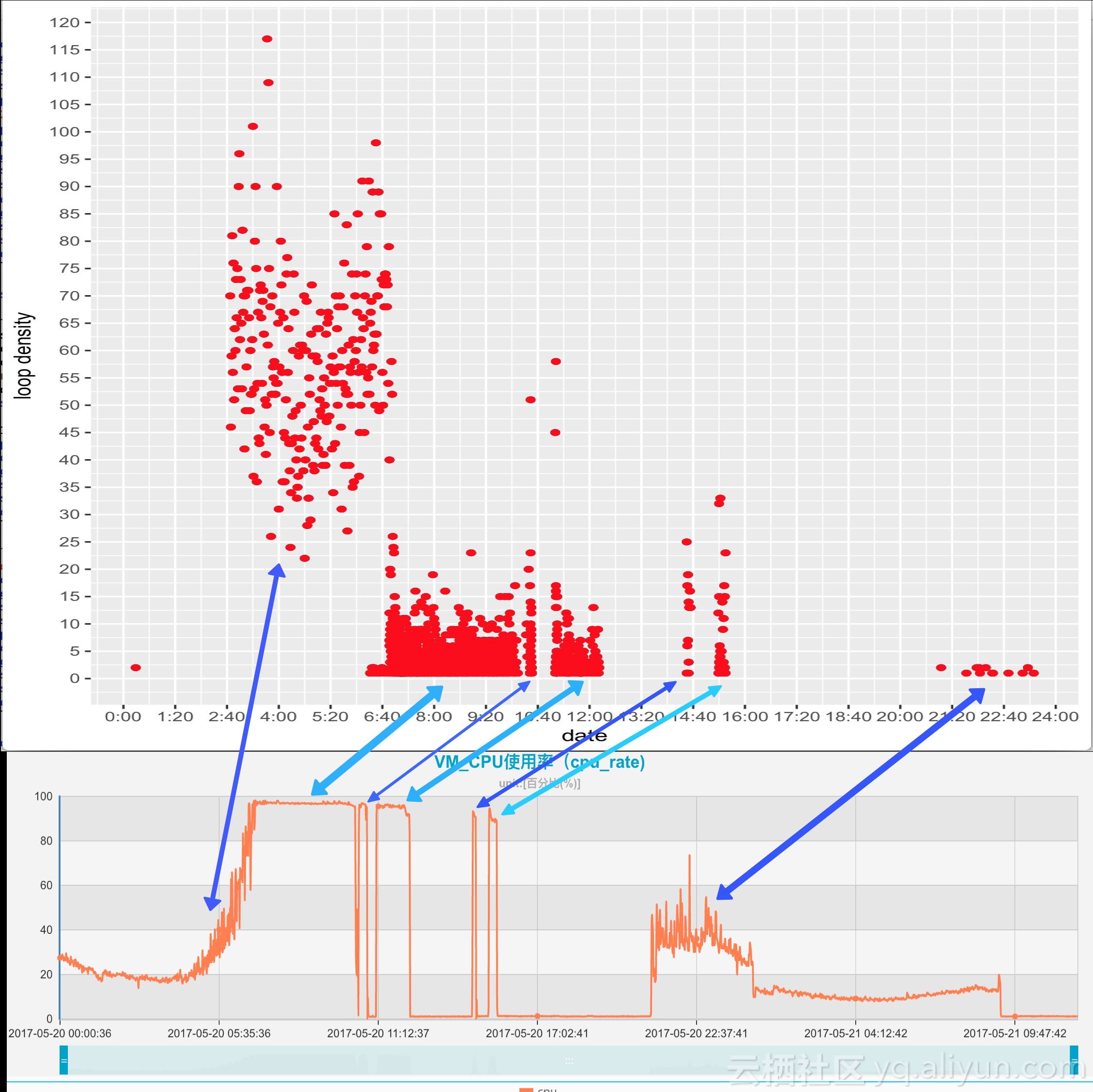
如果我们把散点图做适当的平移和反转操作,则对应就更明显
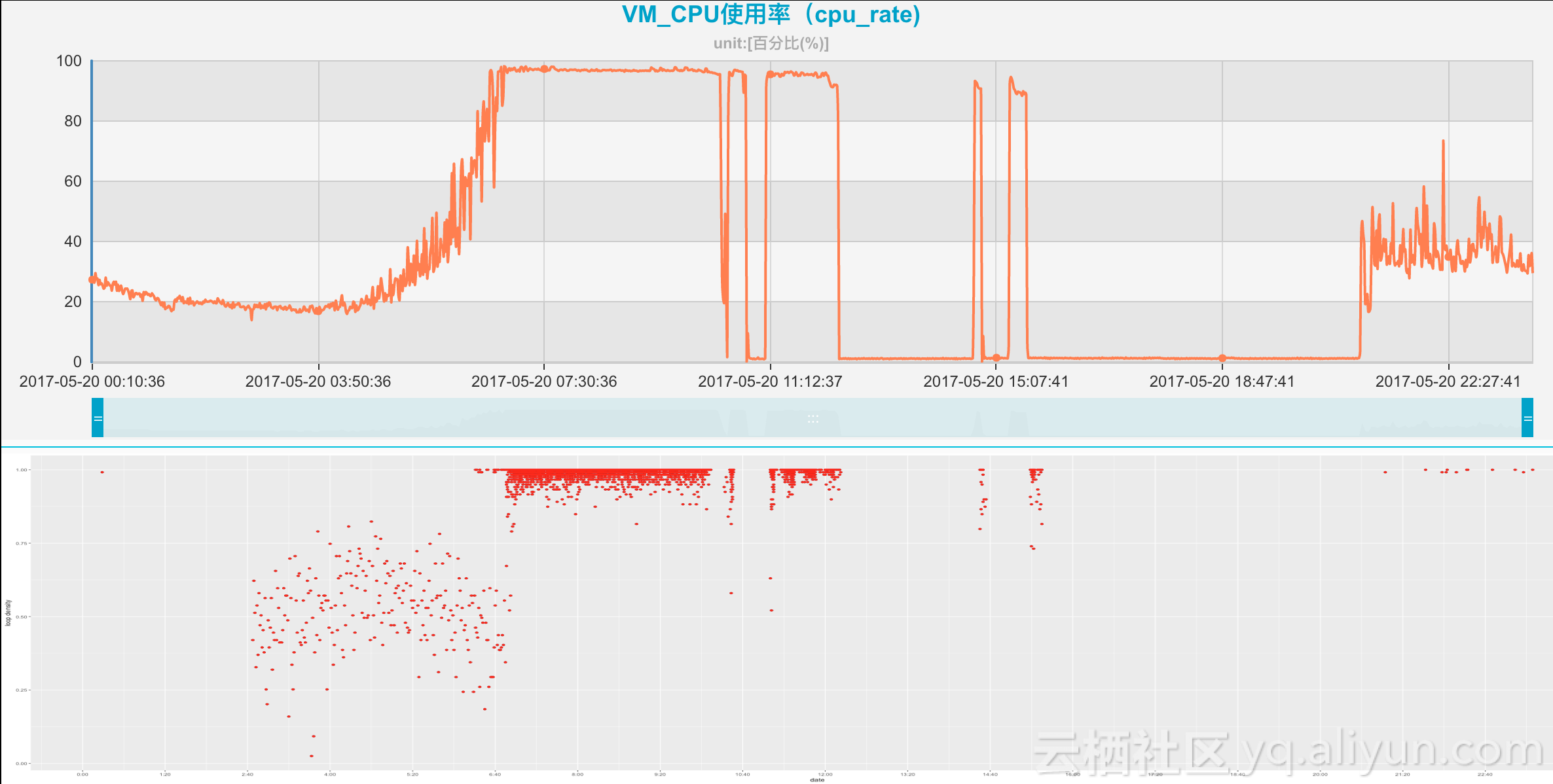
那么,我们的散点图及其热点区域表达的是什么意义呢?
数据建模
我们给出的散点图,粗略的说,x轴显示的是时间,y轴显示的是超时循环执行的次数。根据探索得出的结论,CPU飙高与超时循环有关,但是却与每分钟执行此循环总的次数关系不大。这方面探索的细节请参考“第一个case:探索数据细节”这一章。那么,我们在上面小结里给出的散点图里的点究竟表达了什么呢?
为了便于理解,我们分析清洗的中间结果
perl filter.pl clean_data > middle_data
有趣的发现如下
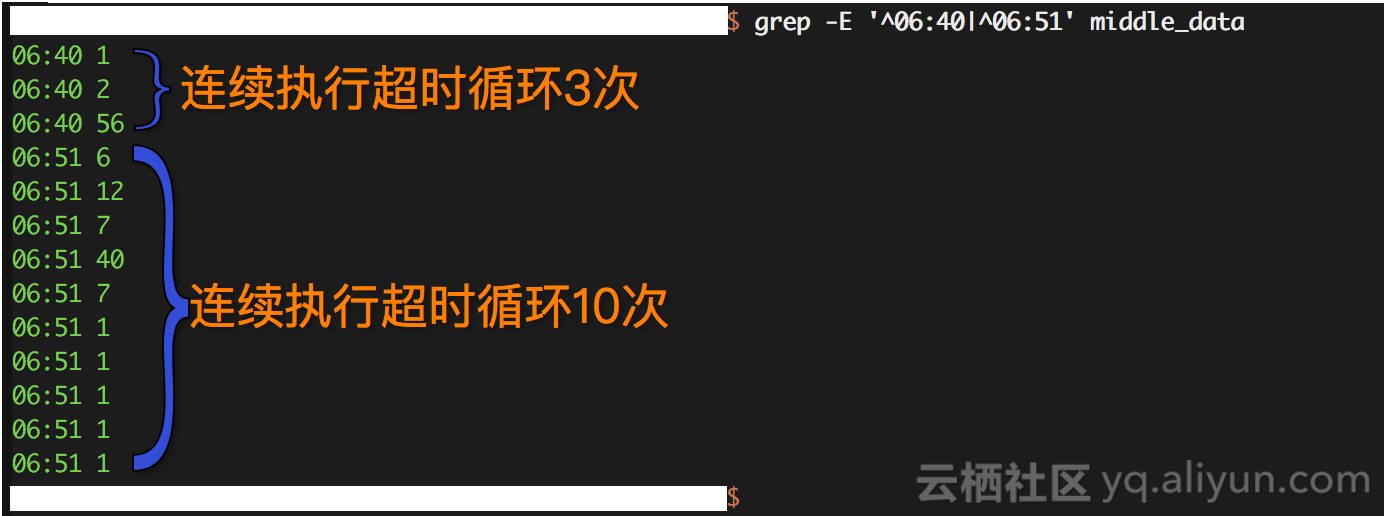
进一步比较监控数据和我们处理的数据
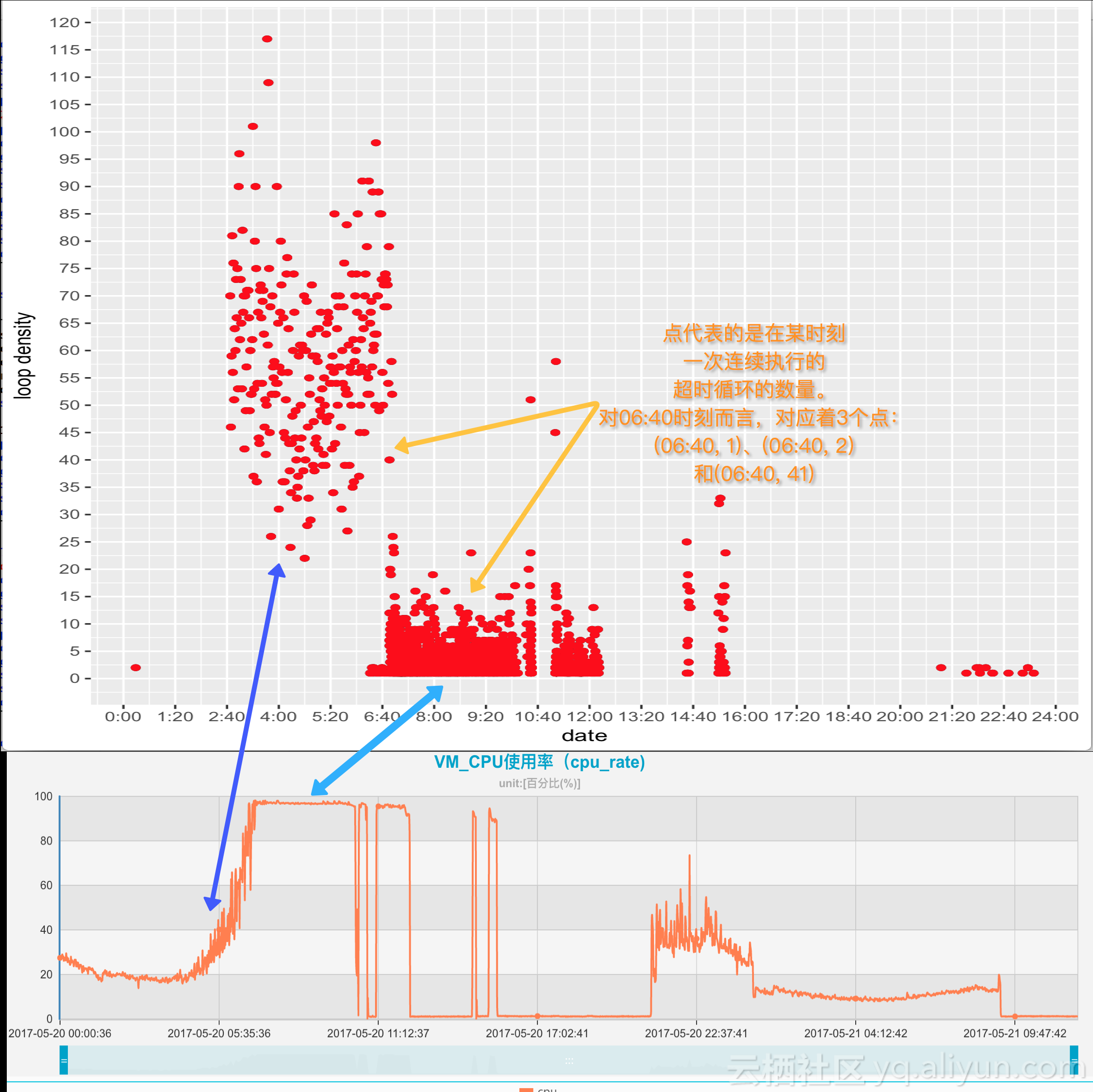
即在某一时刻,连续执行超时循环的次数越多,每次连续执行时执行的超时循环的数量分布的越连续、密集,则散点图上对应这个时刻的点就会连成一条线。如果这个时刻附近的时刻都有类似特性,就会生成色块,形成热点区域,此时CPU消耗会同步升高。
数据解释
因为客户看到散点图后即接受了我们的排查结论,并且立刻去调整其业务逻辑了,并没有进一步向我们解释业务方面的致因。因此,我们没有办法给出一个结合客户业务逻辑的解释。
第一个case:探索数据细节
探索每秒数据
一秒内可能不止一笔数据,因此我们过滤数据继之以排序
grep 'Yar_Concurrent_Client::loop():' warning.log | sort -n > clean_data_per_min
而后由如下的filter-per-min.pl脚本做第一次处理,抽取每秒的数据。坦白说,脚本名称应该为filter-per-sec.pl
#!/usr/bin/perl
use strict;
use warnings;
use feature qw(say);
my $curr = q[];
my $prev = q[];
my $count = 0;
while (<>) {
chomp;
next if (!m!Yar_Concurrent_Client::loop! || m!^$!);
m!\[2017-05-20 (\d\d:\d\d:\d\d)\]!;
$curr = $1;
if ($prev eq q[]) {
$prev = $curr;
$count = 1;
}
if ($curr eq $prev) {
$count++;
} else {
say qq[$prev $count];
$prev = $curr;
$count = 1;
next;
}
}
# to print the last record
say qq[$curr $count];
脚本执行效果如下
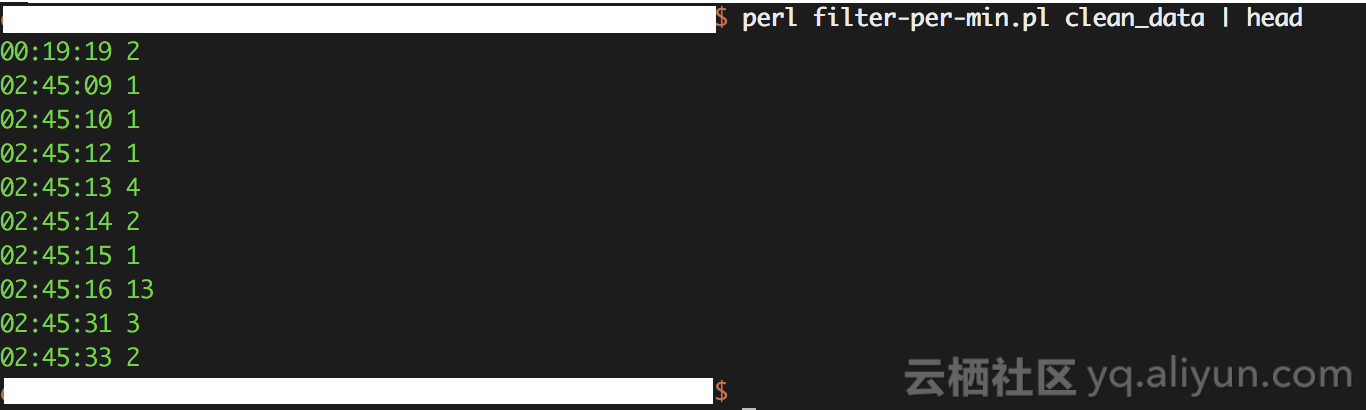
同样,把时间日期转换为数字
perl ./filter-per-min.pl clean_data_per_min | perl -nE 'chomp;m!^(\d+):(\d+):(\d+)\s+(\d+)!;my $date=($160+$2)60+$3;say "$date $4"'
脚本执行效果如下

步骤继续,我们把获取的数据放到一个文件里,并且给数据加上列名称
echo 'Date Freq' > data_per_min
perl ./filter-per-min.pl clean_data_per_min | perl -nE 'chomp;m!^(\d+):(\d+):(\d+)\s+(\d+)!;my $date=($160+$2)60+$3;say "$date $4"' >> data_per_min
这样我们就拿到了数据,可以探究一下每秒数据了
同样,我们提供如下格式化函数以便把时间显示为HH:MM:SS
timeHMS_formatter <- function(x) {
h <- floor(x/3600)
m <- floor((x/60) %% 60)
s <- floor(x %% 60)
lab <- sprintf("%02d:%02d:%02d", h, m, s)
return(lab)
}
我们加载数据,先看看数据分布的大致情况
CPU_OCUPATION = read.table(file="./data_per_min", header=TRUE)
summary(CPU_OCUPATION)
结果如下
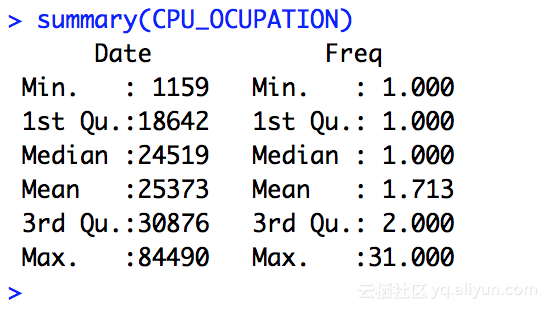
看看散点图
CPU_OCUPATION = read.table(file="./data_per_min", header=TRUE)
qplot(CPU_OCUPATION$Date, CPU_OCUPATION$Freq) +
geom_point(colour="red") +
scale_x_continuous(name="date", breaks=seq(0, 90000, by=7200), labels=timeHMS_formatter) +
scale_y_continuous(name="loop amonunt per second", breaks=seq(0, 36, by=4))
明显数据处理的粒度太小,看不出什么有意义的规律
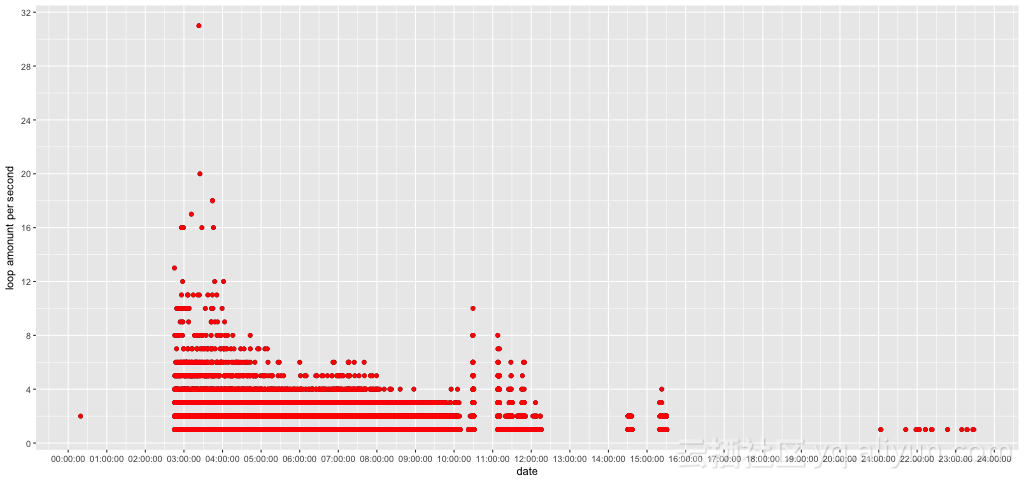
探索每分钟连续执行循环数量
我们以每分钟为单位计数一下超时循环执行的次数。
CPU_OCUPATION = read.table(file="./data", header=TRUE)
factors.continue_loop.per.min = factor(CPU_OCUPATION$Date)
continue_loop.amount.per.min = tapply(CPU_OCUPATION$Date, factors.continue_loop.per.min, length)
qplot(unique(CPU_OCUPATION$Date), continue_loop.amount.per.min) +
geom_point(colour="red") +
scale_x_continuous(name="date", breaks=seq(19, 1420, by=120), labels=timeHM_formatter) +
scale_y_continuous(name="loop amount per minute", breaks=seq(0, 74, by=3))
得到结果如下,没有发现和CPU消耗数据相关的特征。比如,考察06:51时刻,CPU消耗100%,但是对应的连续循环数量却不多。
第二个case:症状和初步排查
症状
客户:
SSD云盘 IO延时在30ms以上
初步排查
初步排查确定,在客户的使用方式下,SSD云盘延迟基本就在30ms左右,并不是突发的异常情况。
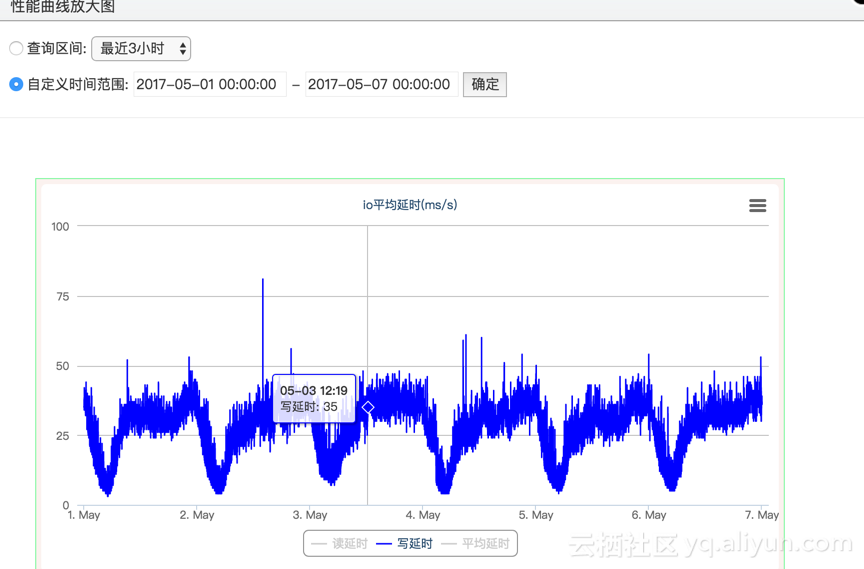
进一步沟通后得知,客户业务高峰时段网络访问延迟从原来的30ms左右增至50ms以上,甚至会出现秒级延迟。客户通过逐行源码插入print语句,自行排查结论是SSD云盘IO延迟30ms是致因。
客户是使用curl工具存取一指定URL来度量访问延迟的。抓包结果显示确实有秒级延迟情形出现。那么,如果在出现问题前在客户的使用方式下SSD云盘的延迟就是30ms左右,那么,SSD云盘的延迟就不会是致因。因此排查继续。
根据测试的时间点,检查系统日志,一条报警记录进入了我们的视野
May 27 21:47:40 iZ2zeepzcp7dzdd9e3pe8dZ kernel: TCP: time wait bucket table overflow
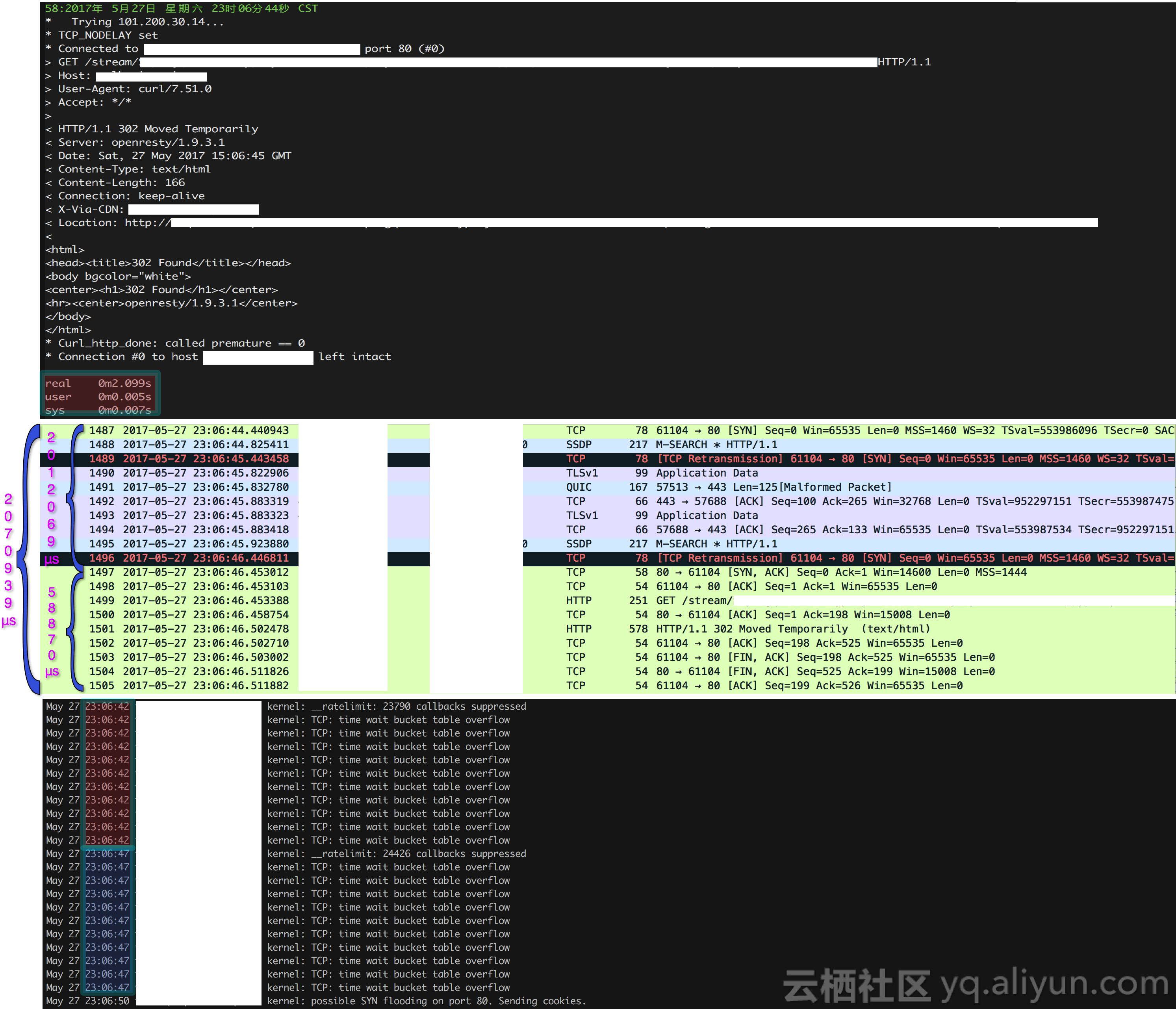
相关的测试结果、抓包记录和日志报警信息整理如下。但问题是,报警信息和网络访问延迟增大有关系吗?
第二个case:系统日志排查和结论
此处和处理第一个case的步骤一致,只是处理逻辑有微调
- 从系统日志而非业务日志获取数据。
- 因为问题连续多日出现,因此这里我们获取了整个五月份的数据(因为lograte的工作机制,其实是获取的4周内的数据)。但是我们并不是从05月01日开始制作散点图的。
- 因为第2项,R中的时间戳格式化函数也相应做了调整。
按照处理第一个case的步骤,我们可以的到散点图如下
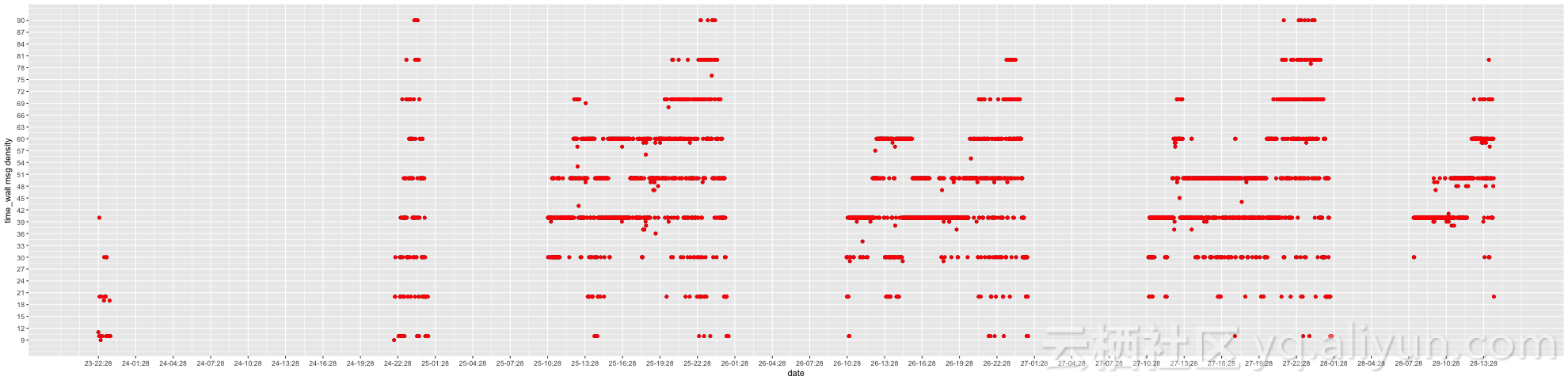
从散点图可以看到,从05月23日起,信号开始出现;自05月26日起,连续三日,每日10:30至次日凌晨01:28之间,信号出现。将图反馈给客户后,客户确认散点图热点区域出现的时段和延迟出现的时段同步。再结合抓包结果显示的时间消耗,客户接受了我们的排查结论。
问题是05月23日客户作了什么调整导致问题出现?结论出人意料,客户答复说05月23日暂时撤除了高防以便使用更稳定带宽的高防。
更进一步:R在工具化中的位置
由以上两个case可以看出,排查和诊断过程中,一如在其他数据处理过程中一样,引入R,使用得当,对于解决疑难杂症,颇见功效。而工具化是共享我们排查技能、流程和知识的合适媒介。因此有必要考察一下R在工具化中的位置。
正如先前已经提到的,排查和诊断过程就是数据处理过程。而R一直是诸如统计学家等数据处理从业者工具箱里最趁手的工具之一。而且就R支持的功能而言,前面我们流程中的每一步,均可由R实现。加之R成熟的社区、各种机器学习算法在R中也不乏高质量实现、不断改进与完善的API以及CRAN(一个R包共享与分发的站点)。因此,我们有理由相信,R或者类似R的组件在工具化中会扮演一个足够重要的角色。
同样,以我们前面给出的流程为例,设想我们要工具化之。比如,以从日志中搜集可能的致因信号为例。稍加考察你就会发现,我们肯定不是事先在头脑中记忆了各种可能的系统和业务致因信号后,再进行排查的。比如,第一个case中业务日志中的超时循环信号,对于不少同学应该都是初次见到。而且一直到解决掉客户的问题,我们也没有了解这个日志记录在业务逻辑中的意义。以工程师处理过程类比,很明显,工具化过程中,分类、聚类、预测,这些机器学习的基础功能模块,我们都需要。因此,工具化中必定有R或者类似R的组件。
所以,无论是手工排查和诊断,还是更进一步工具化,对于工程师而言,R都是上佳之选。
参考
- R官方站点
- 我需要学习R吗?
- 服务器诊所: 数据处理的利器 R
- R 和数据世界
- First-class citizen
- Google's R Style Guide
- R (programming language)