大数据
大数据是最近出现的另一个时髦概念,其背后隐藏了关于计算的丰富信息。大数据关注如何对互联网上的海量数据进行分析,从中发现有价值的统计规律和相关性等信息。这种分析可以广泛应用于各种领域,例如科学、工程、商业、人口普查、执法等。
计算机科学家对数据的存储、查询及处理已经进行了长时间的关注,而且很多关注的问题甚至比目前的技术进展还要超前。可惜的是,这些超前的想法由于各种因素的影响被埋没在历史的尘埃中,被大众所遗忘。“大数据”这一术语在很大程度上是新瓶装旧酒,虽然这一术语确实对很多领域产生了显著的影响。例如,在商业活动中,商业组织收集海量的客户相关数据,并利用这些数据去发现市场趋势、广告投放对象以及客户忠诚度等信息。受到公共资金资助的科研项目也被要求对外公开其数据,以方便公众和其他科研项目能够对这些数据进行多方面的利用和分析。警察系统则利用海量的通信信息和信用卡交易信息,从中发现犯罪分子。所有这些领域都开始主动寻求数据科学家、数据分析师以及数据系统设计师来帮助他们进行数据分析工作。
计算机科学家在其中的贡献主要体现在两个方面。一方面是关于更高效地数据分析方法,另一方面则是能够支持海量数据处理的系统或技术架构。例如,Richard Karp(1993)基于组合方法实现了对基因数据片段进行融合从而形成基因组图谱的高效算法。Tony Chan和Yousef Saad(1986)的研究工作表明,hypercube(一种早期出现的并行计算架构)对于多重网格算法(一类重要的数字计算方法)具有最优的效果,而多重网格算法能够对大规模数据空间的数学模型进行求解。Jeffrey Dean和Sanjay Ghemawat(2008)设计了MapReduce算法,能够支持数千个处理器通过并行的方式对海量数据进行处理。
在商业领域中,如何对大规模数据集进行处理和分析一直以来都是一个重要的问题。商业组织会收集关于客户、库存、产品制造、财务等方面的各种数据,这些数据对于一个大型的国际化商业组织的正常运转具有非常重要的作用。20世纪30年代,一个电子计算机还未出现的年代,IBM靠出售类似卡片分类器和检索器的简单设备从数据处理市场获得了巨大的财富。20世纪50年代,IBM开始向电子数据处理领域发展,转型成为一家计算机公司。1956年,IBM对外发布了第一个硬盘存储系统RAMAC 305,受到了广泛关注。IBM声称,任何商业组织都可以将其堆满仓库的文件资料转移到一个小小的硬盘中,进而能够对数据进行极为高效的处理。随着数据存储需求的不断增长,设计者开始关注如何对数据进行有效的组织从而实现对数据的快速访问和简易维护。当时,两个主流且存在竞争关系的方法分别是综合数据系统(Integrated Data System,IDS)(Bachman 1973)和关系数据库系统(Relational Database System,RDS)(Codd 1970,1990)。综合数据系统具有简单、快速、实用等特点,能够在管理大量数据文件的同时隐藏文件在硬盘上的物理结构和位置。关系数据库系统则基于数学化的集合理论,它具有一个非常清晰的概念模型,但在经过了多年的发展后才实现了与综合数据系统相当的处理效率。从20世纪70年代开始,研究领域形成了一个关于大规模数据库(very large databases)的研究团体,并每年召开一次学术会议(VLDB)对相关议题进行讨论。
从20世纪50年代开始,计算领域的研究者进入了文档管理领域:帮助文档管理员组织数据以实现更加快速的文档检索。图书馆是这些信息检索系统的第一代用户。研究者开发了模糊查询系统。例如,用户可以发出“请查找关于信息检索的文档”,而返回的文档中不一定包含“信息检索”这个字符串。今天,互联网就是一个巨大的无结构的存储系统。在互联网上进行关键词检索非常快速但却不够准确,因此,有效的互联网信息检索仍然是一个困难的问题(Dreyfus 2001)。
Gartner Group将现代的“大数据”定义为4V:数据体量巨大(Volume)、数据的产生速度快(Velocity)、数据的表现格式丰富(Variety)、数据对决策活动具有重要的支持作用(Veracity is important to decisions)。从2014年开始,数据科学的课程或关于数据科学的研究中心在大学和其他研究机构中如雨后春笋般出现。多个领域都涉及其中,例如,来自运筹学和统计学领域的分析师、来自计算机科学和信息系统领域的架构设计师以及来自建模和仿真领域的可视化工程师。这些实践和研究活动也确立了“数据科学”领域的主要研究问题:寻找对大规模数据集进行处理和分析的科学理论基础。
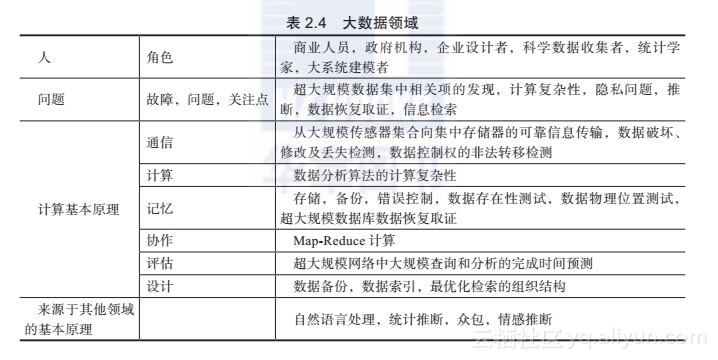
表2.4给出了大数据领域涉及的人、问题以及计算基本原理。