2.5 使用Excel
2.5.1 经典的DataTable
在图2.2所示的调查中,Excel作为排名第一的数据源是情理之中的。甚至可以说,应该找不出来没有使用过Excel表格进行数据处理的读者。Excel的易用性、强大的数据处理功能,也能让即使不会编程的使用者可以快速解决一些常用的数据统计、计算的问题。在早期的商业自动化测试工具中,数据驱动或者关键字驱动是作为一个卖点被广为宣传的亮点。接触过这些工具的读者估计都对DataTable之类的概念印象深刻。在那个假设“系统测试工程师不懂代码”的史前年代,将Excel与自动化测试工具相结合,将前者作为数据源提供者,强迫测试工程师如写“五言七律”或者“三句半”一般,通过填写一个不知道从何而来又将被如何处理的Excel表单来完成自动化用例的编写。这种方式的确为自动化测试的启蒙与推广起到了巨大的作用。问题在于这种方式剥夺了这些所谓的“具有多年自动化测试经验”的测试工程师编写代码的机会。他们与架构自动化测试框架的架构师之间是完全“解耦”的关系,两者之间存在着鸿沟。
在Selenium时代来临之后,也有类似表2.1中使用Excel进行自动化测试的尝试,通过将Selenium IDE中的脚本转移到Excel中,将Excel作为用例开发与存储的载体,实现所谓新型的关键字驱动。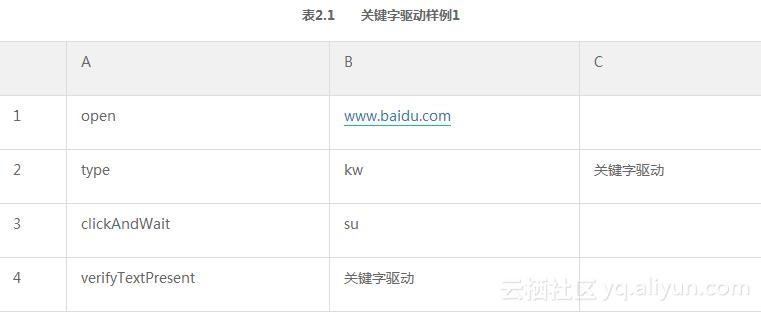
这种方式更应该被认为是一个美丽的误会,只会给自动化测试的赞助人(Sponsor)带来更多的成本投入,从而给该类框架的架构师带来一个更加“稳固”的职位。原因在于这种方式更多地糅合了两种方式的烦恼与挑战。自动化测试工程师依然是被束缚在一个个表单当中,填写单元格的人与框架的构造者之间,双方依旧是“各安其位,各司其职”,泾渭分明。但是另一方面,因为编写用例的所谓自动化测试工程师需要面对Webdriver API,DOM,XPath元素定位等UI自动化实现方面的问题,对于测试工具与Web前端技术的学习要求不可谓不高。可是又因为用例与框架间的割裂,在调试、排错用例的时候的无助感,会给当事人带来非常大的负面反馈,而整个自动化项目在后续的可维护性、可扩展性都存在着问题,框架的构架者必然会成为瓶颈。针对这种方式,提出以下两点建议。
(1)如有可能,使用与开发团队相同的语言、IDE(集成开发环境)来构建自动化测试框架,编写用例,甚至复用其代码评审工具与版本集成环境。
(2)如有可能,让编写自动化测试用例的工程师参与编码,甚至是参与部分框架搭建的机会,这会成为整个自动化项目成功的有力保障之一。
2.5.2 强关键字驱动的自动化用例
如果因为一些业务或者其他的原因,如甲乙方合同要求、外包发包方规定等,非要在自动化测试框架前面加上“基于Excel”(或者XML,HTML以及其他非编码方式),建议考虑类似下面的处理方式。
(1)拓展目标用户:将该套框架的目标使用者从传统的系统测试工程师往前推进到敏捷中的接收测试(Acceptance Test)或者用户验收测试(User Acceptance Testing)参与者之中。也就是让产品经理(Product Owner)或者用户代表等代表领域专家(Domain Expert)作为自动化测试的目标用户。
(2)提升关键字层级:用自动化技术的术语来说,就是关键字不再基于用例执行技术,描述被测应用如何被操纵,而是基于业务原子操作,讲述如何完成被测应用的一个个业务相关的事务。如在TestLink中,有如表2.2所示的一些业务对象,以及它们所对应的属性。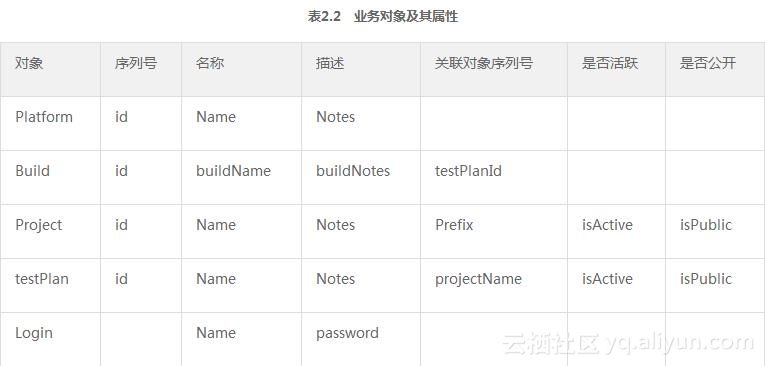
而一个典型的手工系统测试用例,可以是按照如下的方式进行描述的。
(1)以管理员Admin/admin登录。
(2)创建测试项目(序列号:tpj111,名称……略)。
(3)创建测试计划(序列号:tp111,名称……略)。
(4)修改测试计划,将前述创建的测试项目与之关联。
在这个用例中我们看不到输入框、按钮或者其他内容。如果按照前述的关键字驱动型的用例实现方式,在Excel(或者其他任何非代码的媒介)中进行实现,可能看起来可以按照表2.3的方式进行描述。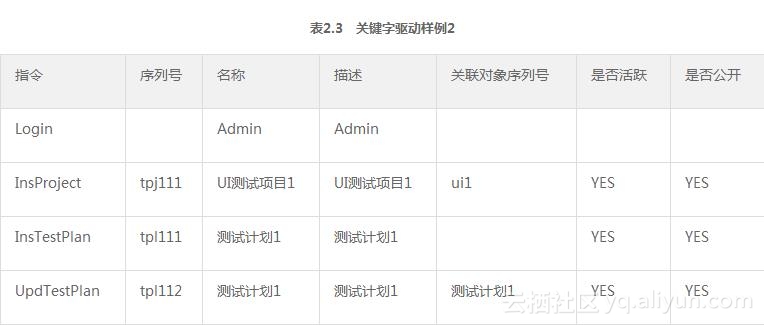
这个Excel的每一行都以一个指令开头,而这个指令是在描述一个业务操作。紧随其后的这一行的每一个单元格都具有预先设计的涵义,并通过事先的整理,具有类似意义的字段名称被尽可能地安置在同一个列中,方便了使用者的理解。接下来,只要按照提供的一个关键字列表以及业务数据的填写指南,即可完成测试用例的编写。自动化测试工程师则可以作为业务代表与测试框架搭建者之间的媒介与桥梁,识别出业务对象与其方法和属性,提出对指令与数据的自动化要求,供框架搭建者进行实现。因为用例正是在关注业务实现,而不是技术层面的用例驱动执行,从而提供了一个选择的可能性,让喜欢关注业务的测试工程师真正摆脱用例执行的实现技术细节,而喜欢技术的测试工程师则可以在底层驱动框架与Excel用例之间,通过关键字的实现过程,建立起一层足够厚度的中间层,让框架提供成长的空间给工作其中的工程师,也给自身的可扩展性与可维护性的提高带来保障。相较于表2.2中的实现方式,后者更贴近业务,从而保障了用例的稳定性,学习成本也要低很多。
2.5.3 Apache POI介绍
从本小节开始将介绍Excel文件的解析,并且将使Apache POI作为解析工具包。Apache POI是Apache软件基金会的开放源码库,POI提供API给Java程序对Microsoft Office格式文档读和写的功能。该项目的官方网址是http://poi.apache.org/。在编写本书时,其最新发布的版本是3.10,并且已经提供了3.11的beta版本。
Microsoft Office是一个产品族,涵盖了这种类型的文档格式,POI也提供了不同的API组件来进行相应的支持。
Excel (SS=HSSF+XSSF)
Word (HWPF+XWPF)
PowerPoint (HSLF+XSLF)
OpenXML4J (OOXML)
OLE2 Filesystem (POIFS)
OLE2 Document Props (HPSF)
Outlook (HSMF)
Visio (HDGF)
TNEF (HMEF)
Publisher (HPBF)
在本章中,我们将只涉及Excel文件的读取工作。感兴趣的读者可以通过POI官网提供的各种样例学习和了解更多有关POI的使用方法。
2.5.4 单个工作表的解析
Excel工作簿是由一个个工作表所组成的。很多情况下当讨论如何进行Excel解析的时候,其实是在讨论如何解析其中的一个工作表。
因此,首先来通过引入类SheetData来介绍下单工作表的解析。该类的简单实现如下:
package com.dataset.excel;
import java.util.ArrayList;
import java.util.List;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
public class SheetData {
private Sheet sheet;
private List< String[] > dataList = new ArrayList< String[] >();
public SheetData(Sheet sheet){
this.sheet=sheet;
setSheetDataSet();
}
protected String getCellText (Row row,int column) {
String cellText="";
Cell cell = row.getCell(column, Row.CREATE_NULL_AS_BLANK);
switch(cell.getCellType()){
case Cell.CELL_TYPE_STRING:
cellText = cell.getStringCellValue().trim();
break;
case Cell.CELL_TYPE_BLANK:
cellText = "";
break;
case Cell.CELL_TYPE_BOOLEAN:
cellText = Boolean.toString(cell.getBooleanCellValue());
break;
case Cell.CELL_TYPE_NUMERIC:
if(DateUtil.isCellDateFormatted(cell)){
cellText = String.valueOf(cell.getDateCellValue());
}else{
cell.setCellType(Cell.CELL_TYPE_STRING);
String value= cell.getStringCellValue();
if(value.indexOf(".") >-1){
cellText = String.valueOf(new Double(value)).trim();
}else{
cellText = value.trim();
}
}
break;
case Cell.CELL_TYPE_ERROR:
cellText = "";
break;
case Cell.CELL_TYPE_FORMULA:
cell.setCellType(Cell.CELL_TYPE_STRING);
cellText = cell.getStringCellValue();
if(cellText!=null){
cellText = cellText.replaceAll("#N/A","").trim();
}
break;
default:
cellText = "";
break;
}
return cellText;
}
private void setSheetDataSet(){
int columnNum = 0;
if(sheet.getRow(0)!=null){
columnNum = sheet.getRow(0).getLastCellNum()-sheet.getRow(0).
getFirstCellNum();
}
if(columnNum >0){
for(Row row:sheet){
String[] singleRow = new String[columnNum];
int n = 0;
for(int i=0;i< columnNum;i++){
singleRow[n]=this.getCellText(row, i);
n++;
}
if("".equals(singleRow[0])){continue;}
dataList.add(singleRow);
}
}
}
public List< String[] > getSheetDataSet(){
return dataList;
}
public int getRowCount(){
return sheet.getLastRowNum();
}
public int getColumnCount(){
Row row = sheet.getRow(0);
if(row!=null&&row.getLastCellNum() >0){
return row.getLastCellNum();
}
return 0;
}
public String[] getRowData(int rowIndex){
String[] dataArray = null;
if(rowIndex >this.getRowCount()){
return dataArray;
}else{
dataArray = new String[this.getColumnCount()];
return this.dataList.get(rowIndex);
}
}
public String[] getColumnData(int colIndex){
String[] dataArray = null;
if(colIndex >this.getColumnCount()){
return dataArray;
}else{
if(this.dataList!=null&&this.dataList.size() >0){
dataArray = new String[this.getRowCount()+1];
int index = 0;
for(String[] rowData:dataList){
if(rowData!=null){
dataArray[index] = rowData[colIndex];
index++;
}
}
}
}
return dataArray;
}
public String getText(int row, int column){
return getRowData(row)[column];
}
}
在SheetData类中,首先定义了如下两个变量:
private Sheet sheet;
private List< String[] > dataList = new ArrayList< String[] >();
其中,私有的sheet变量将用于保存在构造方法中获取的Sheet对象的实例。
public SheetData(Sheet sheet){
this.sheet=sheet;
setSheetDataSet();
}
Sheet类是POI包中有关工作表的对象模型。整个SheetData也可以说是在Sheet类之上又进行了一层封装,提供了一些更为适用于本次案例的工作表数据读取方法。
另一个私有变量dataList则被定义为一个数组列表,读者也可以猜测出来其用途是保存从sheet中读取的数据。从上述构造方法来看,这一过程是通过调用setSheetDataSet()方法来完成的。
这个方法的核心是,通过 for(Row row:sheet)这一循环,遍历整个工作表中的每一行。在这个循环之下,又通过遍历该行中的每一个单元格来读取每个单元格的值,将其保存在singleRow[]数组中:
singleRow[n]=this.getCellText(row, i);
并将其添加进dataList列表中。
dataList.add(singleRow);
另外一个需要指出的是,这个方法中也花了大量的篇幅通过一个switch/case来处理一些单元格中的特殊情况。
switch(cell.getCellType())
通过判断单元的不同特殊情况,如字符串、空白、数值等,来完成相应的处理。
在完成了这些基础的数据解析与读取工作之外,SheetData类中还提供了几个方法来方便后续的对于dataList数据的使用,例如:
public String[] getRowData(int rowIndex)
public String[] getColumnData(int colIndex)
这两个方法可以分别读取指定行或者列的数据。而public String getText(int row, int col)通过单元格行列数的方式来获取某一指定单元格的值。其实这个时候对于工作表的处理,与Web自动化测试中有关表(table)的处理方式是类似的,例如getRowCount以及getColumnCount方法等。感兴趣的读者可以参考第5章中有关TestLink表格的部分了解更多的情况。
2.5.5 整个工作簿的解析
单个工作表的解析只是为本小节中所需要完成的工作打了个前站。在本小节中,将完成Excel文件读取,并真正地完成解析,为后续的工作提供数据源,为此,这里引入了ExcelPaser类。该类的实现如下:
package com.dataset.excel;
import java.io.IOException;
import java.io.InputStream;
import java.util.HashMap;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
public class ExcelPaser {
private Workbook wb = null;
private HashMap< String,SheetData > sheetDataMap=new HashMap< String,SheetData >();
private int sheetNum=-1;
public ExcelPaser(InputStream in){
try {
wb = WorkbookFactory.create(in);
sheetNum= wb.getNumberOfSheets();
setSheetDataMap();
} catch (InvalidFormatException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
private void setSheetDataMap(){
for(int sheetIndex=0;sheetIndex< sheetNum;sheetIndex++){
String sheetName=wb.getSheetName(sheetIndex);
SheetData sheetData= new SheetData(wb.getSheetAt(sheetIndex));
sheetDataMap.put(sheetName, sheetData);
}
}
public SheetData getSheetDataByName(String sheetName){
return sheetDataMap.get(sheetName);
}
public int getSheetIndex(String sheetName){
int index=wb.getSheetIndex(sheetName);
// System.out.println("\nsheet["+index+"]="+sheetName);
return index ;
}
public String getText(String sheetName,int row, int column){
return getSheetDataByName(sheetName).getText(row, column);
}
}
整个类的结构与前述SheetData是类似的。在构造方法中完成了针对输入的Excel文件的读取与解析,以及数据的保存。
public ExcelPaser(InputStream in){
try {
wb = WorkbookFactory.create(in);
sheetNum= wb.getNumberOfSheets();
setSheetDataMap();
} //其余略
}
其中,通过使用InputStream这一抽象类的实例in作为入参,可以接受多种类型的输入,提高了便利性。而通过使用WorkbookFactory这个工厂类来接受入参,则使得程序可以接受xls或者xlst等不同类型的Excel文件,提高了通用性。在Webdriver中,也使用到了这一设计模式。读者可以参考本书最后一部分有关Webdriver基础介绍的部分。
另外,对于头一次使用POI工具包的读者,有一点需要注意,即WorkbookFactory这个类并没有包含在默认的poi.jar包中,如果需要使用,就在工程中添加poi-ooxml.jar以及poi-ooxml-schemas.jar这两个包。
与前一小节中的setSheetDataSet()方法相类似的,这次我们使用了setSheetDataMap()来保存整个工作簿,也就是通过sheetIndex遍历每个工作表:
SheetData sheetData= new SheetData(wb.getSheetAt(sheetIndex));
来依次获取了所有工作表中的数据,并存入一个Map之中。为了验证整个文件导入与数据读取的效率,这里也做了一个中等数据的测试,具体结果请见下一小节。
2.5.6 用例解析与执行
前面有关工作表与工作薄的解析具有一定的通用性。读者可以直接使用这些类与方法,稍加修改,运用于自身的测试框架。接下来将介绍如何使用之前的这些工作成果,完成基于Excel的测试用例解析与执行工作。
package com.dataset.excel;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.poi.ss.usermodel.Sheet;
import com.dataset.excel.MockAPI.MockAPI;
import com.dataset.excel.MockAPI.MockTestLinkAPI;
public class CaseLoader {
static {
loadExcel();
}
private static SheetData sheetData;
public static void loadExcel(){
String path="sample.xls";
String sheetName="用例111"; //实际项目中这两个可来自配置文件
ExcelPaser reader=null;
long now=System.currentTimeMillis();
try {
InputStream in = new FileInputStream(path);
reader=new ExcelPaser(in);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
if(reader !=null){
sheetData= reader.getSheetDataByName(sheetName);
long delta=System.currentTimeMillis()-now;
System._b>out__.println("\n Time used in ms::"+delta);
}
}
public static String[] getCallList(){
return sheetData.getColumnData(0);
}
public static String[] getParams(int rowIndex){
return sheetData.getRowData(rowIndex);
}
public static void main(String args[]){
Class< ? > clazz = MockAPI.class;
Method[] methods =clazz.getDeclaredMethods();
String [] callList=getCallList();
for(int i=1;i< callList.length;i++){
for(Method m:methods){
if( m.getName().equalsIgnoreCase(callList[i])){
try {
m.invoke(new MockAPI(),(Object)getParams(i));
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}
}
}
首先介绍一下CaseLoader的执行逻辑。通过静态块部分调用了loadExcel()方法。
static {
loadExcel();
}
该方法使用之前的工作成果,完成了给定Excel的读取与解析。
String path="sample.xls";
String sheetName="用例111";
并且将指定的工作表sheetName中的数据存储于内存之中,完成了测试用例及其数据的初步导入。
sheetData= reader.getSheetDataByName(sheetName);
紧接着,按照之前的设计,该工作表的第一列作为自动化用例所调用的指令。因此,在getCallList这个方法中,通过获取sheetData中第一列的数据就完成了所有需要运行的指令的获取。
而某一行中,除了第一列之外的其余数据,就是该指令的各种入参。这些参数通过getParams方法获取。
测试用例执行的工作是在main方法中完成的。整体的思路就是读取Excel中第一列的指令字符串,并通过反射与指令执行类的指令进行匹配和调用。
首先,通过遍历整个指令数组callList的方式,依次进行用例步骤的执行工作。
for(int i=1;i< callList.length;i++)
其中使用Java中的反射方式,通过以下代码获取到MockAPI类所有定义的方法并存入方法数组methods之中。
Class< ? > clazz = MockAPI.class;
Method[] methods =clazz.getDeclaredMethods();
并且依次和MockAPI类的方法名称进行匹配。
for(Method m:methods){
if( m.getName().equalsIgnoreCase(callList[i])){
try {
m.invoke(new MockAPI(),(Object)getParams(i));
} //略
}
如果匹配成功,则通过invoke的方式,调用该方法,并传入相应的入参。这样,就完成了以Excel编写测试自动化测试用例并自动运行的工作。
考虑到文件读取与解析需要耗费一定的时间,并且受文件中数据量大小的影响,这里简单地通过打桩的方式来获取文件读取与解析前后的时间,以测试不同数据量下的耗时。
long now=System.currentTimeMillis();
工作表“用例111”中包含了5行7列的数据,并且只有一个工作表,文件解析的用时及运行结果如下:
Done to parse sheet '用例111' in ms::731
**Matched Method::login
called login**
Params::{username=admin, password=admin}
**Matched Method::InsProject
called InsProject*
Params::{isActive=ui1, prefix=UI测试项目1, name=tpj111, isPublic=YES, notes=UI测试项目1}
如果将这一工作表的内容扩充为一个包含5000行10列数据的中型工作表,运行结果为:
Done to parse sheet '用例111' in ms::1350
大体上只增加了一倍时间。而如果将“用例111”复制3份,使得整个文件包含了约2万行10列数据的中型数据集,运行结果则更新为:
Done to parse sheet '用例111' in ms::2462
基本上又增加了一倍,但也是秒级的耗时。对于运行时间一般为若干分钟的API测试用例集到若干小时的UI测试用例集来说,这点耗时是可以接受的,甚至是可以忽略的。从这点上来说,通过Excel来作为开发测试用例的载体,运行时通过解析该文件来执行用例在性能效率上是可行的。
2.5.7 Mock API类
前面ClassLoader中所使用到的MockAPI只是一个适配器类,作用是在用例执行类以及MockAPI这个真正驱动被测对象、进行测试执行的类MockTestLinkAPI之间建立一个桥梁,完成指令和入参的转义和执行。当然本例中的只是一个Mock类,本身并不完成任何的用例步骤执行工作,只是在示例的两个方法中简单地申明了一下方法被调用并回显出来传入的参数列表。
package com.dataset.excel.MockAPI;
import java.util.Map;
public class MockTestLinkAPI {
public boolean login(Map < String,String > params){
System.out.println("called login**");
System.out.println("Params::"+params.toString());
System.out.println("");
return true;
}
public void InsProject(Map < String,String > params){
System.out.println("called InsProject*");
System.out.println("Params::"+params.toString());
System.out.println("");
}
}
限于篇幅,这里就只示例了login以及InsProject这两个方法。
2.5.8 Mock API适配器类
在介绍用例执行时曾经介绍过Mock API的作用是作为被测应用的执行API与测试用例之间的一个转换器。因为现实中很多情况下这些API可能是第三方提供,并非框架构建人员完成的。很少能遇到类似MockTestLinkAPI这样可以自行定义方法与入参形式的。因此,类似MockAPI这种适配器类就显得非常有必要了。
package com.dataset.excel.MockAPI;
import java.util.HashMap;
import java.util.Map;
public class MockAPI {
private MockTestLinkAPI api = new MockTestLinkAPI();
public static final String[] loginArray={"","","username","password","",""};
public static final String[] InsProjectArray={"id","name","notes","prefix",
"isActive","isPublic"};
public boolean login(String [] valuses){
Map< String,String > map =getParamMap(loginArray,valuses);
if (map!=null){
return api.login(map);
}
else return false;
}
public void InsProject(String [] valuses){
Map< String,String > map =getParamMap(InsProjectArray,valuses);
if (map!=null){
api.InsProject(map);
}
}
private Map< String,String >getParamMap(String[] params,String[] valuses ){
if (params.length >valuses.length){
System.out.println("value number is less than param number");
return null;
}
Map< String,String > map=new HashMap< String,String >();
for(int i=1;i< params.length;i++){
if(params[i]!=""){
map.put(params[i], valuses[i]);
}
}
return map;
}
}
这个类的主要作用就是将来自 MockTestLinkAPI 的方法转换成可供用例执行类CaseLoader调用的方法。另一个变化就是入参形式的变化。在用例执行类中,指令执行的入参是一个字符串数组,而在MockTestLinkAPI中,所有方法的入参都是Map类型的。因此在该类中也提供了一个数组向Map进行转换的方法以及loginArray等指令入参所需的各个参数的名称。
至此,我们通过一个小型但是较为实用的案例完成了对于Excel作为数据源的测试数据管理的介绍。其中使用了POI这一功能强大的Office系列文档的处理工具集的一小部分功能。同时也介绍了一种基于Excel的测试用例的编写与执行方法。在实现的过程中也简单介绍了反射的使用以及适配器类的使用。