结构化查询语言(SQL)是数据挖掘分析行业不可或缺的一项技能,总的来说,学习这个技能是比较容易的。对于SQL来说,编写查询语句只是第一步,确保查询语句高效并且适合于你的数据库操作工作,才是最重要的。这个教程将会提供给你一些步骤,来评估你的查询语句。
首先,应该了解学习SQL对于数据挖掘分析这个工作的重要性;
接下来,应该先学习SQL查询语句的处理和执行过程,以便可以更好的了解到,编写高质量的查询有多重要。具体说来就是,应该了解查询是如何被解析、重写、优化和最终评估的;
掌握了上面一点之后,你不仅需要重温初学者在编写查询语句时,所使用的查询反向模型,而且还需要了解有关可能发生错误的替代方案和解决方案。同时还应该了解更多查询工作中的基于集合的程序方法。
在性能方面也需要关注反向模型,除了手动提高SQL查询的方法外,还需要以更加结构化和深入的方式来分析你的查询,以便使用其它工具来完成整个查询工作。
在执行查询之前,还需要更加深入的了解执行查询计划的时间复杂度。
最后,应该了解如何进一步的调整你的查询语句。
为什么要学SQL?
寻找数据挖掘分析行业的工作,SQL是最需要的技能之一,不论是申请数据分析工作、数据引擎工作、数据挖掘分析或者其它工作。在O'Reilly发布的《2016数据科学从业者薪酬报告》中,有70%的受访者证实了这一点,表示他们需要在专业环境中使用SQL。此外,本次调查中,SQL远胜于R(57%)和Python(54%)等编程语言。所以在数据挖掘分析领域,SQL是必备技能。
我们分析一下SQL从1970s早期开发出,到现在还经久不衰的原因:
一、公司基本都将数据存储在关系数据库管理系统(RDBMS)或关系数据流管理系统(RDSMS)中,所以需要使用SQL来实现访问。SQL是通用的数据语言,可以使用SQL和几乎其它任何数据库进行交互,甚至可以在本地建立自己的数据库!
二、只有少量的SQL实现没有遵循标准,在供应商之间不兼容。因此,了解SQL标准是在数据挖掘分析行业立足的必要要求。
三、最重要的是SQL也被更新的技术所接受,例如Hive或者Spark SQL。Hive是一个用于查询和管理大型数据集的类似于SQL的查询语言界面;Spark SQL可用于执行SQL查询。
简而言之,以下就是为什么你应该学习这种查询语言:
即使对于新手来说,SQL也很容易学习。学习曲线很平缓,编写SQ查询几乎不花费时间。
SQL遵循“学习一次,随时随地可用”的原则,所以花费时间学习SQL很划算!
SQL是对编程语言的一种极好的补充;在某些情况下,编写查询甚至比编写代码更为优先!
...
SQL处理和查询执行
为了提高SQL查询的性能,首先需要知道,运行查询时,内部会发生什么。
查询执行的过程:
首先,将查询解析成“解析树”; 分析查询是否满足语法和语义要求。解析器将会创建一个输入查询的内部表示,然后将此输出传递给重写引擎。
然后,优化器的任务是为给定的查询,寻找最佳执行或查询计划。执行计划准确地定义了每个操作所使用的算法,以及如何协调操作的执行。
最后,为了找到最佳的执行计划,优化器会列举所有可能的执行计划,并确定每个计划的质量或成本,以便获取有关当前数据库状态的信息,最后选择最佳的执行计划。由于查询优化器可能不完善,因此数据库用户和管理员有时需要手动检查并调整优化器生成的计划,以便获得更好的性能。
现在你已经清楚了什么才是好的执行计划。
正如前面了解到的,计划的成本质量起着重要的作用。更具体地说,评估计划所需的磁盘I / O数量,计划的CPU花销以及数据库客户端的整体响应时间和总执行时间等因素至关重要。这就是时间复杂性的概念。后面还将继续了解。
接下来,执行所选择的查询计划,由系统的执行引擎进行评估,并返回查询结果。
编写SQL查询
需要进一步说明的是,垃圾回收原则(GIGO)原本就是表达在查询处理和执行之中:制定查询的人,同时也决定着SQL查询的性能。
这意味着在编写查询,有些事情可以同步去做。就像文章开始时介绍的,编写查询需要遵循两个标准:首先,编写的查询需要满足一定的标准,其次还应该应对查询中可以出现的性能问题。
总的来说,有四个分句和关键字,方便新手考虑性能问题:
WHERE 分句
INNER JOIN 和 LEFT JOIN 关键字
HAVING 分句
虽然这种做法简单而天真,但对于一个初学者来说,这些方法却是一个很好的指引。这些地方也是你刚开始编写时,容易发生错误的地方,这些错误也很难发现。
同时,要想提升性能,使其变得有意义,就不能脱离上下文:在考虑SQL性能时,不能武断的认为上面的分句和关键字不好。使用WHERE 或 HAVING的分句也可能是很好的查询语句。
通过下面的章节来来进一步了解编写查询时反向模型和代替方法,并将这些提示和技巧作为指导。如何重写查询和是否需要重写查询取决于数据量,以及数据库和执行查询所需的次数等。这完全取决于你的查询目标,事先掌握一些有关数据的知识是非常重要的!
1. 仅检索你需要的数据
在编写SQL查询时,并不是数据越多越好。因此在使用SELECT 语句、DISTINCT分句和LIKE操作符时,需要谨慎。
SELECT声明
在编写完查询语句之后,首先需要做的事情就是检查select语句是否简洁。你的目标应该是删除不必要的select列。以便只取到符合你查询目的的数据。
如果还有相关使用exists的子查询,那么就应该在select语句中使用常量,而不是选择实际列的值。当检查实体时,这是特别方便的。
请记住,相关子查询是使用外部查询中的值的子查询,并且在这种情况下,NULL是可以作为“常量”的,这点确实令人困惑!
通过以下示例,可以了解使用常量的含义:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT '1' FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
提示:我们很容易发现,使用相关子查询并不总是一个好主意,所以可以考虑通过以下方式避免使用相关子查询。
例如使用 INNER JOIN重写:
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines
ON fines.driverslicensenr = drivers.driverslicensenr;
DISTINCT分句
SELECT DISTINCT 语句用于返回不同的值。 DISTINCT 是一个分句,能不用尽量不用,因为如果将DISTINCT添加到查询语句中,会导致执行时间的增加 。
LIKE运算符
在查询中使用LIKE运算符时,如果模式是以% 或_开始,则不会使用索引。它将阻止数据库使用索引(如果存在的话)。当然,从另一个角度来看,你也可以认为,这种类型的查询可能会放宽条件,会检索到许多不一定满足查询目标的记录。
另外,你对存储在数据中数据的了解,可以帮助你制定一个模式,使用该模式可以对所有数据进行正确的过滤,以便查找到你最想要的数据。
2. 缩小查询结果
如果无法避免使用 SELECT语句时,可以考虑通过其它方式缩小查询结果。例如,使用LIMIT 分句和数据类型转换的方法。
TOP,LIMIT和ROWNUM分句
可以在查询中添加LIMIT或TOP分句,来设置查询结果的最大行数。
下面是一个示例:
SELECT TOP 3 *
FROM Drivers;
请注意,你可以进一步指定PERCENT。
例如,如果你想更改查询的第一行 SELECT TOP 50 PERCENT *。
SELECT driverslicensenr, name
FROM Drivers
LIMIT 2;
此外,你还可以添加ROWNUM 分句,相应于在查询中使用的LIMIT:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
数据类型转换
应该使用最小的数据类型,因为小的数据类型更加有效。
当查询中需要进行数据类型转化,会增加执行时间,所以尽可能的避免数据类型转换的发生;
如果不能避免的话,需要谨慎的定义数据类型的转换。
基于集合和程序的方法进行查询
反向模型中隐含的事实是,建立查询时基于集合和程序的方法之间存在着不同。
查询的程序方法是一种非常类似于编程的方法:你告诉系统需要做些什么以及如何做。例如上一篇文章中的示例,通过执行一个函数然后调用另一个函数来查询数据库,或者使用包含循环、条件和用户定义函数(UDF)的逻辑方式来获得最终查询结果。你会发现通过这种方式,一直在请求一层一层中数据的子集。这种方法也经常被称为逐步或逐行查询。
另一种是基于集合的方法,只需指定需要执行的操作。使用这种方法要做的事情就是,指定你想通过查询获得的结果的条件和要求。在检索数据过程中,你不需要关注实现查询的内部机制:数据库引擎会决定最佳的执行查询的算法和逻辑。
由于 SQL 是基于集合的,所以这种方法比起程序方法更加有效,这也解释了为什么在某些情况下,SQL 可以比代码工作地更快。
基于集合的查询方法也是数据挖掘分析行业要求你必须掌握的技能!因为你需要熟练的在这两种方法之间进行切换。如果你发现自己的查询中存在程序查询,则应该考虑是否需要重写这部分。
从查询到执行计划
反向模式不是静止不变的。在你成为 SQL 开发者的过程中,避免查询反向模型和重写查询可能会是一个很艰难的任务。所以时常需要使用工具以一种更加结构化的方法来优化你的查询。
对性能的思考不仅需要更结构化的方法,还需要更深入的方法。
然而,这种结构化和深入的方法主要是基于查询计划的。查询计划首先被解析为“解析树”并且准确定义了每个操作使用什么算法以及如何协调操作过程。
查询优化
在优化查询时,很可能需要手动检查优化器生成的计划。在这种情况下,将需要通过查看查询计划来再次分析你的查询。
要掌握这样的查询计划,你需要使用一些数据库管理系统提供给你的工具。
你可以使用以下的一些工具:
一些软件包功能工具可以生成查询计划的图形表示。
其它工具能够为你提供查询计划的文本描述。
请注意,如果你正在使用 PostgreSQL,则可以区分不同的 EXPLAIN,你只需获取描述,说明 planner 如何在不运行计划的情况下执行查询。同时 EXPLAIN ANALYZE 会执行查询,并返回给你一个评估查询计划与实际查询计划的分析报告。一般来说,实际执行计划会切实的执行这个计划,而评估执行计划可以在不执行查询的情况下,解决这个问题。在逻辑上,实际执行计划更为有用,因为它包含了执行查询时,实际发生的其它细节和统计信息。
接下来你将了解 XPLAIN 和 ANALYZE 的更多信息,以及如何使用这两个命令来进一步了解你的查询计划和查询性能。要做到这一点,你需要开始使用两个表: one_million 和 half_million 来做一些示例。
你可以借助 EXPLAIN 来检索 one_million 表的当前信息:确保已将其放在运行查询的首要位置,在运行完成之后,会返回到查询计划中:
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
___
Seq Scan on one_million
(cost=0.00..18584.82 rows=1025082 width=36)
(1 row)
在以上示例中,我们看到查询的 Cost 是0.00..18584.82 ,行数是1025082,列宽是36。
同时,也可以借助 ANALYZE 来更新统计信息。
ANALYZE one_million; EXPLAIN SELECT * FROM one_million; QUERY PLAN______________________________________ Seq Scan on one_million (cost=0.00..18334.00 rows=1000000 width=37) (1 row)
除了 EXPLAIN 和 ANALYZE,你也可以借助 EXPLAIN ANALYZE 来检索实际执行时间:
EXPLAIN ANALYZE
SELECT *
FROM one_million;
QUERY PLAN
_
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.015..1207.019 rows=1000000 loops=1)
Total runtime: 2320.146 ms
(2 rows)
使用 EXPLAIN ANALYZE 的缺点就是需要实际执行查询,这点值得注意!
到目前为止,我们看到的所有算法是顺序扫描或全表扫描:这是一种在数据库上进行扫描的方法,扫描的表的每一行都是以顺序(串行)的顺序进行读取,每一列都会检查是否符合条件。在性能方面,顺序扫描不是最佳的执行计划,因为需要扫描整个表。但是如果使用慢磁盘,顺序读取也会很快。
还有一些其它算法的示例:
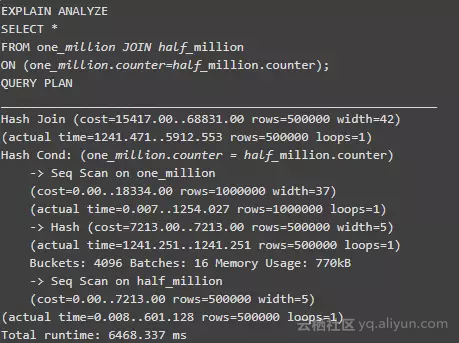
我们可以看到查询优化器选择了 Hash Join。请记住这个操作,因为我们需要使用这个来评估查询的时间复杂度。我们注意到了上面示例中没有 half_million.counter 索引,我们可以在下面示例中添加索引:
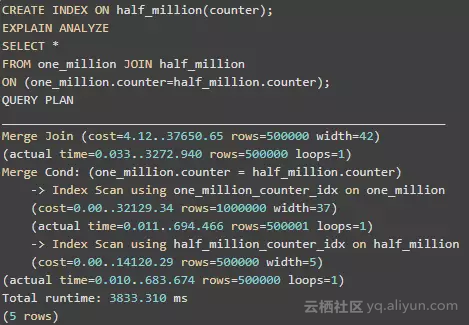
通过创建索引,查询优化器已经决定了索引扫描时,如何查找 Merge join。
请注意,索引扫描和全表扫描(顺序扫描)之间的区别:后者(也称为“表扫描”)是通过扫描所有数据或索引所有页面来查找到适合的结果,而前者只扫描表中的每一行。
原文发布时间为:2017-09-29
本文来自合作伙伴“数据和云”,了解相关信息可以关注“数据和云”微信公众号