6.7 实体链接任务及系统
给定一段文本(如“在旧金山的发布会上,苹果为开发者推出新编程语言 Swift”),一个实体链接系统需要通过如下多个子任务来实现实体消歧 [4] 。
1 . 识别文档中的实体提及 (mention)。这里的提及指的是我们想要链接的对象,如上面例子文本中的提及 {“旧金山”,“苹果”,“Swift”}。
2 . 针对每一个提及,识别该提及在知识图谱中可能指向的候选目标实体。例如,上述文本中的提及“苹果”可能指向的目标实体包括 { 苹果 ( 水果 ),苹果公司,苹果 ( 电影 ),苹果 ( 银行 ), …}。
3 . 基于提及的上下文等信息对目标实体进行排序。例如,系统需要根据“苹果”的上下文词语{发布会,编程语言,开发者,…}识别出该段文本中“苹果”指的是苹果公司,而不是苹果 ( 水果 ) 或者苹果 ( 电影 )。
4 . 空提及检测与聚类。人类知识具有海量规模,同时随时间快速更新,因此知识图谱不可能覆盖所有的真实世界实体。在这种情况下,需要识别出知识库尚未包含其目标实体的提及,并将这些提及按其指向的真实世界实体进行聚类。例如,由于现有知识库没有包含上文中提及“Swift”指向的目标实体 Swift(编程语言),实体链接系统需要将“Swift”的目标实体设置为空实体 NIL,表示该提及在知识库中没有链接对象。
针对上述子任务,近年来的相关研究、技术和资源介绍如下。
提及识别。提及识别的目标是识别文本中需要链接的提及。目前提及识别主要采用两种技术,一是使用通用命名实体识别技术(例如 StanfordNER * 工具)来识别文本中的人名、地名和机构名,并将这些实体名作为待链接的对象;二是使用词典匹配技术,首先构建实体名字的列表,并在文本中匹配这些实体名字的出现来识别待链接提及。上述两项技术各有优缺点。命名实体识别技术保证了识别出的提及是完整的实体名,但是通常只能覆盖有限的实体类别,无法识别用户可能感兴趣的其他实体类别(如电影名、音乐名、书名等)。词典匹配技术能够覆盖大部分待链接的实体类别,但是其性能依赖于特定资源(也就是实体名字列表)的质量;同时由于有些类别的实体名包含了很多常用词(例如,在维基百科中 IS、A 等都是实体名字),上述词典匹配方法会引入大量的噪音;最后,基于词典的匹配没有考虑提及在句子中的语法约束,无法保证匹配的提及符合语法边界。
为解决上述问题,目前实体链接系统通常采用混合策略来完成提及识别:首先使用命名实体识别方法和词典匹配方法识别所有可能的提及候选;然后过滤掉统计意义上非显著的或不符合语法边界的提及候选。
候选目标实体识别。候选目标实体识别的目标是找到每一个提及可能指向的所有目标实体集合,例如找到提及“苹果”可能指向的目标实体集合 { 苹果 ( 水果 ),苹果公司,苹果 ( 电影 ),苹果( 银行 ),…}。目前,实体链接系统主要通过查阅实体引用表(Reference Table)来完成上述任务。表 1 中展示了一个引用表的示例,表中记录了每个实体名可能指向的目标实体(如 AI 的目标实体包括 Artificial Intelligence、歌手 Ai 等)及一些相关的统计数据(例如 AI 在维基百科中被链接到实体Artificial Intelligence 的次数)。
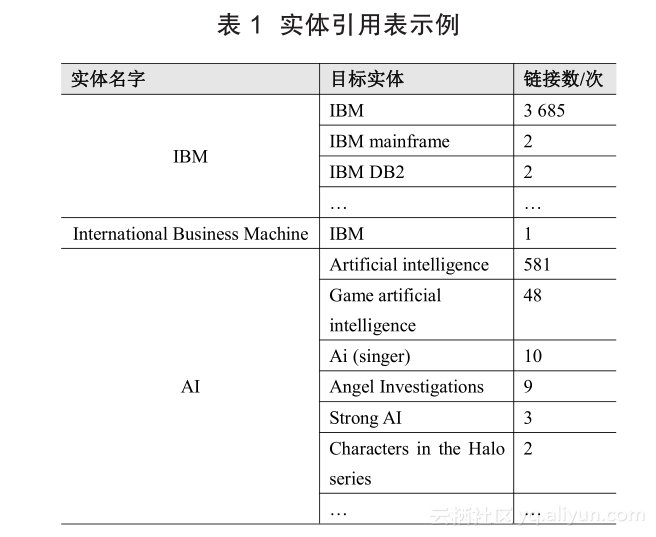
给定实体引用表,实体链接系统可以通过查阅实体名来找到其候选目标实体。显而易见,实体引用表的质量极大影响了实体链接系统的性能。目前,大部分的实体引用表通过挖掘维基百科锚文本(Wikipedia Anchor Text)的方式来构建[5] 。同时,为了进一步保证候选目标实体的覆盖度,名字扩展技术(如缩写名的扩展)[6]和错误拼写校正技术(如基于机器翻译的错误拼写校正)也被广泛使用。
实体排歧。实体排歧是实体链接的核心,也是实体链接的难点所在。给定一段文本、该段文本中的待链接提及集合及目标知识库,实体排歧的目标是确定每一个提及所指向的目标实体。下面展示了一个实体排歧任务的例子。

实体排歧的关键在于挖掘可用于识别提及目标实体的证据信息,将这些证据表示为供计算机处理的形式,并构建高性能的算法来综合不同证据进行链接决策。在当前研究中,实体排歧使用的主要证据信息可归纳为如下几类。
实体知名度。实体知名度指一个实体被人们了解的程度。通常情况下一个高知名度的实体更可能被一篇文章提到。例如,一篇新闻中提到“苹果”时,通常指的是水果苹果或者苹果公司,而不是电影苹果或者苹果银行,因为前两者在普通人中的知名度更高。一个实体 e 的知名度通常表示为该实体出现的先验概率 P(e)。
名字常用性。名字常用性指的是一个名字被用作特定实体名字的概率。例如虽然 IBM、Big Blue和 International Business Machine 都是 IBM 公司的名字,但是人们通常更倾向于使用名字 IBM,而只在特定情况下使用后面两个名字。名字常用性通常被表示为一个实体 e 使用一个名字 s 的条件概率P(s|e)。
上下文词语分布。上下文词语分布建模了特定实体周围词出现的规律性。图 2 展示了苹果公司和苹果银行的上下文词分布,可以看出上下文词
分布为特定实体的出现提供了显著证据:苹果公司周围主要出现的词是 { 乔布斯,iPhone,公司,Mac,…},苹果银行周围主要出现的词是 { 银行,存款,纽约,…},两者之间具有明显差异。
实体之间的关联度。一篇文章中出现的实体并非毫无关系,而是通常具有一定程度的语义关联。因此,一个提及的目标实体应当与文章中其他提及的目标实体之间存在语义关联。例如,出现了实体“乔布斯”和“提姆库克”的文章中往往更有可能出现苹果公司;而出现了范冰冰的文章中则更有可能出现电影苹果。
文章主题。实体的出现往往与文章主题密切相关,因此文章的主题会为实体的出现提供重要证据。例如,在通用新闻中水果苹果的出现概率最高;在IT 新闻中苹果公司的出现概率会高于水果苹果;在娱乐新闻中则出现电影苹果的概率会高于水果苹果和苹果公司。
基于上述实体排歧证据,实体排歧算法的主要工作是如何综合多个证据为每个(提及,候选实体)对进行打分。然后对每个提及 m,选择具有最高打分的(m,候选实体)的候选实体作为m的目标实体。目前,实体排歧算法可以分为两类,分别是局部推理算法和全局推理算法。
● 局部推理算法。局部推理算法认为提及之间相互独立,因此不考虑提及之间的相互关系,而只针对每个提及进行单独推断。例如,局部推理算法将例子 1 中三个提及 {m 1 = 旧金山 , m 2 = 苹果 ,m 3 = Swift} 的排歧看成三个相互独立的任务。目前,局部推理算法可以分为基于分类的算法[5-7]和基于生成模型的算法[8] 。基于分类的算法将每一个(提及,候选实体)表示为一个特征向量;然后通过分类器来综合所有特征信息,并使用分类器的打分来判断(提及,候选实体)是否是一个正确的链接决策。与基于分类的方法不同,基于生成模型的算法通过建模文档或实体提及的生成过程,并基于该生成过程计算特定上下文 c 中提及 m 指向实体 e 的后验概率 P(e|c,m) 来进行实体链接决策。
● 全局推理算法。与局部推理算法不同,全局推理算法不仅仅考虑提及和其候选目标实体之间的打分,也考虑不同实体排歧决策之间存在的依赖关系(例如,同一篇文章中提及的目标实体必须语义相关)。目前,全局推理算法通常可以分为基于特定全局目标函数优化的方法[9] 、基于图的协同推理算法[10]和基于 Topic Model 的算法[11-12] 。
空实体检测与聚类。空实体检测与聚类仍然是实体链接的一个难点问题,同时也极大地影响实体链接系统性能。如在 KBP 2009 的实体链接数据集中,67.5%提及的目标实体在知识库中没有覆盖。目前大部分实体链接系统采用两种方法解决空实体检测问题,一是构建一个专门的空实体检测分类器;二是在知识库中加入一个伪实体 NIL,并通过对比(提及,NIL)的打分和提及与其他目标实体之间的打分检测该提及是否需要链接到 NIL 实体。