【故障处理】队列等待之TX - allocate ITL entry案例
1 BLOG文档结构图

2 前言部分
2.1 导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~:
① enq: TX - allocate ITL entry等待事件的解决
② 一般等待事件的解决办法
③ 队列等待的基本知识
Tips:
① 本文在ITpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和微信公众号(xiaomaimiaolhr)有同步更新
② 文章中用到的所有代码,相关软件,相关资料请前往小麦苗的云盘下载(http://blog.itpub.net/26736162/viewspace-1624453/)
③ 若文章代码格式有错乱,推荐使用搜狗、360或QQ浏览器,也可以下载pdf格式的文档来查看,pdf文档下载地址:http://blog.itpub.net/26736162/viewspace-1624453/,另外itpub格式显示有问题,可以去博客园地址阅读
④ 本篇BLOG中命令的输出部分需要特别关注的地方我都用灰色背景和粉红色字体来表示,比如下边的例子中,thread 1的最大归档日志号为33,thread 2的最大归档日志号为43是需要特别关注的地方;而命令一般使用黄色背景和红色字体标注;对代码或代码输出部分的注释一般采用蓝色字体表示。
List of Archived Logs in backup set 11
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- ------------------- ---------- ---------
1 32 1621589 2015-05-29 11:09:52 1625242 2015-05-29 11:15:48
1 33 1625242 2015-05-29 11:15:48 1625293 2015-05-29 11:15:58
2 42 1613951 2015-05-29 10:41:18 1625245 2015-05-29 11:15:49
2 43 1625245 2015-05-29 11:15:49 1625253 2015-05-29 11:15:53
[ZHLHRDB1:root]:/>lsvg -o
T_XDESK_APP1_vg
rootvg
[ZHLHRDB1:root]:/>
00:27:22 SQL> alter tablespace idxtbs read write;
====》2097152*512/1024/1024/1024=1G
本文如有错误或不完善的地方请大家多多指正,ITPUB留言或QQ皆可,您的批评指正是我写作的最大动力。
3 故障分析及解决过程
3.1 故障环境介绍
|
项目 |
Source db |
|
db 类型 |
RAC |
|
db version |
11.2.0.3.0 |
|
db 存储 |
ASM |
|
OS版本及kernel版本 |
AIX 64位 7.1.0.0 |
3.2 故障发生现象及报错信息
最近事情比较多,不过还好,碰到的都是等待事件相关的,同事发了个AWR报告,说是系统响应很慢,我简单看了下,简单分析下吧:
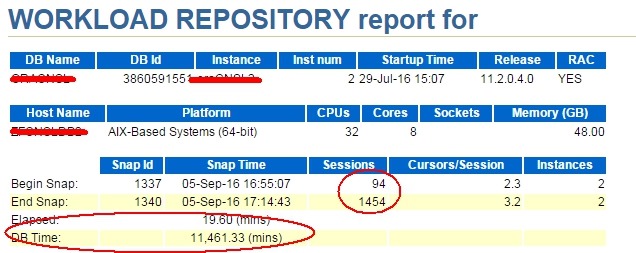
20分钟时间而DB Time为11461分钟,DB Time太高了,负载很大,很可能有异常的等待事件,系统配置还是比较牛逼的。
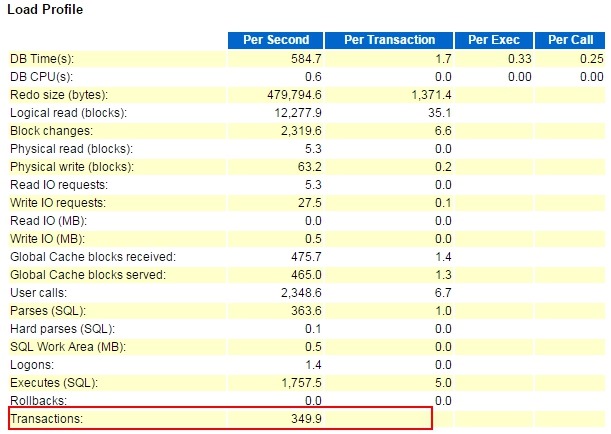
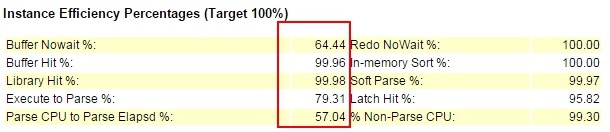
事务量很大,其它个别参数有点问题,不一一解说了。Instance Efficiency Percentages也有点问题:
等待事件很明显了:

AWR的其它部分就不分析了,首先这个等待事件:enq: TX - allocate ITL entry比较少见,查了一下MOS,有点收获:Troubleshooting waits for 'enq: TX - allocate ITL entry' (文档 ID 1472175.1)
Observe high waits for event enq: TX - allocate ITL entry
Top 5 Timed Foreground Events
Event Waits Time(s) Avg wait (ms) % DB time Wait Class
enq: TX - allocate ITL entry 1,200 3,129 2607 85.22 Configuration
DB CPU 323 8.79
gc buffer busy acquire 17,261 50 3 1.37 Cluster
gc cr block 2-way 143,108 48 0 1.32 Cluster
gc current block busy 10,631 46 4 1.24 Cluster
CAUSE
By default INITRANS value for table is 1 and for index is 2. This defines an internal block structure called the Interested Transaction List (ITL). In order to modify data in a block, a process needs to use an empty ITL slot to record that the transaction is interested in modifying some of the data in the block. If there are insufficient free ITL slots then new ones will be taken in the free space reserved in the block. If this runs out and too many concurrent DML transactions are competing for the same data block we observe contention against the following wait event - "enq: TX - allocate ITL entry".
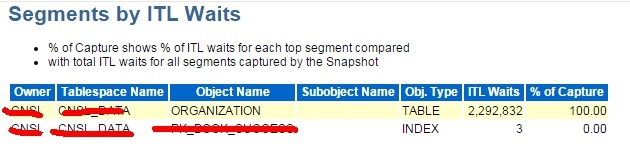
You can see candidates for re-organisation due to ITL problems in the "Segments by ITL Waits" section of an Automatic Workload Repository (AWR) report:
Segments by ITL Waits
* % of Capture shows % of ITL waits for each top segment compared
* with total ITL waits for all segments captured by the Snapshot
Owner Tablespace Name Object Name Subobject Name Obj. Type ITL Waits % of Capture
PIN BRM_TABLES SERVICE_T TABLE 188 84.30
PIN BRM_TABLES BILLINFO_T P_R_06202012 TABLE PARTITION 35 15.70
SOLUTION
The main solution to this issue is to increase the ITL capability of the table or index by re-creating it and altering the INITRANS or PCTFREE parameter to be able to handle more concurrent transactions. This in turn will help to reduce "enq: TX - allocate ITL entry" wait events.
To reduce enq: TX - allocate ITL entry" wait events, We need to follow the steps below:
1) Set INITRANS to 50 and pct_free to 40
alter table <table_name> PCTFREE 40 INITRANS 50;
2) Re-organize the table using move (alter table <table_name> move;)
3) Then rebuild all the indexes of the table as below
alter index <index_name> rebuild PCTFREE 40 INITRANS 50;
总结一下:
原因:表和索引的默认INITRANS值不合适,引起的事务槽分配等待。当一个事务需要修改一个数据块时,需要在数据块头部获取一个可用的ITL槽,用于记录事务的id,使用undo数据块地址,scn等信息。如果事务申请不到新的可用ITL槽时,就会产生enq: TX - allocate ITL entry等待。 发生这个等待时,要么是块上的已分配ITL个数(通过ini_trans参数控制)达到了上限255(10g以后没有了max_trans限制参数,无法指定小于255的值),要么是这个块中没有更多的空闲空间来容纳一个ITL了(每个ITL占用24bytes)。 默认情况下创建的表ITL槽数最小为1+1,pctfree为10,那么如果是这样一种情况,如果表中经常执行update语句,然后块中剩余的10%空间所剩无几,而且业务的并发量还很大,此时就很容易遇到enq: TX - allocate ITL entry等待。
解决:解决方式就是调整表和索引的INITRANS,有必要还需要调整pcfree值。
1) Set INITRANS to 50 and pct_free to 40
alter table <table_name> PCTFREE 40 INITRANS 50;
2) Re-organize the table using move (alter table <table_name> move;)
3) Then rebuild all the indexes of the table as below
alter index <index_name> rebuild PCTFREE 40 INITRANS 50;
3.3 故障分析及解决
有了以上的知识,我们知道,目前首先需要找到产生等待事件的表,然后修改INITRANS和PCTFREE来重构表就可以了。
我们查看AWR中的Segments by ITL Waits部分:


SELECT D.SQL_ID,
CHR(BITAND(P1, -16777216) / 16777215) ||
CHR(BITAND(P1, 16711680) / 65535) "Lock",
BITAND(P1, 65535) "Mode",
D.CURRENT_OBJ#,
COUNT(1),
COUNT(DISTINCT D.SESSION_ID)
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN
TO_DATE('2016-09-05 16:55:00', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2016-09-05 17:15:00', 'YYYY-MM-DD HH24:MI:SS')
AND D.EVENT = 'enq: TX - allocate ITL entry'
GROUP BY D.SQL_ID,
(CHR(BITAND(P1, -16777216) / 16777215) ||
CHR(BITAND(P1, 16711680) / 65535)),
(BITAND(P1, 65535)),
D.CURRENT_OBJ#;

SELECT * FROM v$sql a WHERE a.SQL_ID='1cmnjddakrqbv';

SELECT * FROM Dba_Objects d WHERE d.object_id=87620;

好吧,知道了表名,我们查看一下表的属性:
SELECT * FROM Dba_Tables d WHERE d.table_name='ORGANIZATION';

pct_free为10,ini_trans为1,我们根据MOS应该修改这2个值,SQL如下:
ALTER TABLE ORGANIZATION PCTFREE 20 INITRANS 16;
ALTER TABLE ORGANIZATION MOVE;
ALTER INDEX PK_ORGANIZATION REBUILD PCTFREE 20 INITRANS 16 NOLOGGING;
这里需要注意:该表大约2000条记录,很小,所以MOVE的时候可以不用并行,也不用NOLOGGING,若是表很大的时候可以考虑并行+NOLOGGING属性,另外,还需要REBUILD索引才可以。
修改完成后,开发人员经过测试后终于可以了,给我简单回复了一下。

About Me
..........................................................................................................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新,推荐pdf文件阅读
● QQ群:230161599 微信群:私聊
● 本文itpub地址:http://blog.itpub.net/26736162/viewspace-2124735/ 博客园地址:http://www.cnblogs.com/lhrbest/articles/5854407.html
● 本文pdf版:http://yunpan.cn/cdEQedhCs2kFz (提取码:ed9b)
● 小麦苗分享的其它资料:http://blog.itpub.net/26736162/viewspace-1624453/
● 联系我请加QQ好友(642808185),注明添加缘由
● 于 2016-09-06 09:00~2016-09-06 19:00 在中行完成
● 【版权所有,文章允许转载,但须以链接方式注明源地址,否则追究法律责任】
..........................................................................................................................................................................................................
长按识别二维码或微信客户端扫描下边的二维码来关注小麦苗的微信公众号:xiaomaimiaolhr,学习最实用的数据库技术。
