注:MaxCompute原名ODPS,是阿里云自研的大数据计算平台,文中出现的MaxCompute与ODPS都指代同一平台,不做区分
什么是Hive
Hive是一款经典的hadoop技术栈的数仓软件,可以让用户采用SQL来完成大数据量的计算分析。如果你对Hive还不熟悉,请移步Apache Hive官网获取进一步了解。MaxCompute在很多功能上与Hive相近,所以大部分MaxCompute的用户曾经也是Hive的用户。
什么是HiveServer2
既然提到HiveServer2,那得先介绍一下HiveServer1,我们通常也直接称之为HiveServer。HiveServer是基于Apache Thrift构建的一套服务,它支持远程客户端通过Thrift API向Hive提交请求。由于HiveServer1无法处理超过一个以上客户端的并发请求,所以社区对HiveServer1进行了重写,从而解决了HiveServer1中存在的诸多问题,该重写后的新版本我们称之HiveServer2。
由于HiveServer2本质上是一个Thrift Server,所以天然拥有跨语言的支持,而大量的Hive生态的工具也是基于HiveServer2的Thrift API实现的,比如最常见的Hive ODBC和Hive JDBC,以及基于这两套实现之上的其他工具。
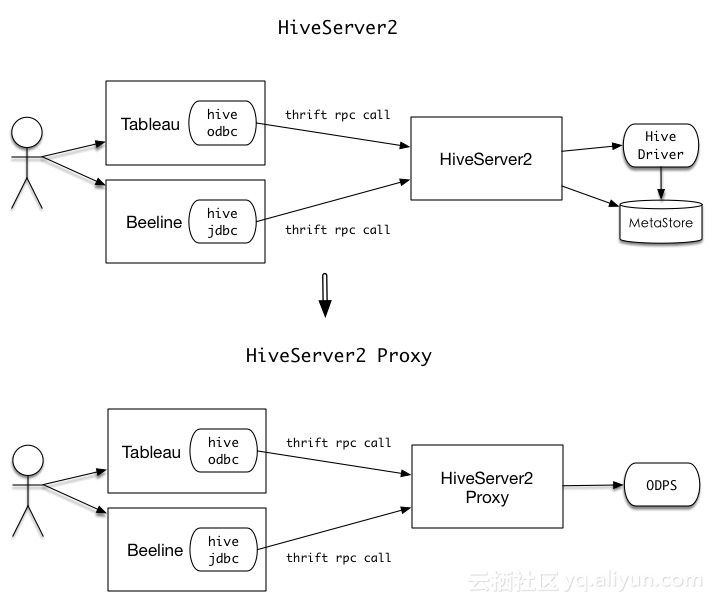
什么是HiveServer2 Proxy
顾名思义,HiveServer2 Proxy是一个代理,它是在原有HiveServer2的基础之上定制开发后得到的。它完成的工作就是接受客户端提交的的Thrift请求,将其反序列化并转换成MaxCompute能够识别的请求,然后提交给MaxCompute处理,并在MaxCompute处理完后将响应再次转换成客户端能够识别的符合Hive接口规范的Thrift响应,从而实现Hive生态工具到MaxCompute的互通。简而言之,它的功能就是在用户无需修改Hive生态工具的情况下,为这些工具与MaxCompute的交互提供了一条通路,从而使我们能在复用已有的Hive工具的同时,也能使用上MaxCompute强大的计算引擎。
HiveServer2 Proxy的原理图如下所示:
下面我们将通过两个实例来演示HiveServer2 Proxy的功效。
部署HiveServer2 Proxy
首先,部署HiveServer2 Proxy的前置条件是安装好Java1.7和hadoop2.x(如果你不想安装hadoop也可以跳过这一步),此处不做赘述,请参考这两者的官方文档。笔者在以下内容中将以MacBook PRO的OS X来作为演示系统。其他操作系统的用户在配置上大同小异。
确保前置条件满足后,请下载HiveServer2 Proxy的测试版。
将下载到的压缩包解压,得到名为apache-hive-2.1.0-odps-proxy的文件夹。设置好HIVE_HOME环境变量,如笔者的配置:
emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy
% export HIVE_HOME=$(pwd)
emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy
% echo $HIVE_HOME
/Users/emerson/apache-hive-2.1.0-odps-proxy
如果你安装了hadoop请配置环境变量HADOOP_HOME,如果跳过没有安装的,可以使用proxy自带的hadoop依赖,即根目录下的hadoop目录。可以在根目录下执行如下命令:
emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy
% export HADOOP_HOME=$(pwd)/hadoop
完成环境变量的配置之后进入根目录下的conf文件夹,修改hive-site.xml中的相关配置项,样例如下所示,其中每一项的说明已在description标签中有所描述:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.execution.engine</name>
<value>odps</value>
<description>hive执行引擎,此处默认是odps,不需要修改</description>
</property>
<property>
<name>hive.session.impl.classname</name>
<value>org.apache.hive.service.cli.session.HiveSessionOdpsImpl</value>
<description>HiveSession的的odps plugin实现,不需要修改</description>
</property>
<property>
<name>odps.accessid</name>
<value>abcdefg</value>
<description>请修改成你的accessid</description>
</property>
<property>
<name>odps.accesskey</name>
<value>123456789=</value>
<description>请修改成你的accesskey</description>
</property>
<property>
<name>odps.project</name>
<value>odpsdemo</value>
<description>请修改成你的默认project</description>
</property>
<property>
<name>odps.projects</name>
<value>odpsdemo</value>
<description>请修改成你的project列表,如果有多个,请以半角逗号分隔,该配置会在show schemas时生效</description>
</property>
<property>
<name>odps.endpoint</name>
<value>https://service.odps.aliyun.com/api</value>
<description>默认odps endpoint,不需要修改</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>20000</value>
<description>HiveServer2 Thrift Server以binary方式启动时服务端口,可以酌情修改,以免端口冲突</description>
</property>
</configuration>
对于大部分用户来说,只需要修改odps.accessid、odps.accesskey、odps.project及odps.projects四项即可,其余项可以保留默认配置。如果20000端口已被占用,可以通过hive.server2.thrift.port更换端口配置。
完成相关配置之后,请回到根目录,执行bin/hiveserver2启动proxy。
emerson@192.168.31.104 /Users/emerson/apache-hive-2.1.0-odps-proxy
% bin/hiveserver2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/emerson/apache-hive-2.1.0-odps-proxy/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/Cellar/hadoop/2.7.1/libexec/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
4a5f92fce28a [INFO] ODPS JDBC driver, Version 1.9
4a5f92fce28a [INFO] endpoint=https://service.odps.aliyun.com/api, project=odpsdemo
可以通过查看日志来确定服务是否启动成功,如下所示:
emerson@192.168.31.104 /Users/emerson
% tail -f /tmp/$USER/hive.log
2016-10-04T17:50:42,048 INFO [main] service.AbstractService: Service:HiveServer2 is started.
2016-10-04T17:50:42,057 INFO [main] server.Server: jetty-7.6.0.v20120127
2016-10-04T17:50:42,108 INFO [Thread-5] thrift.ThriftCLIService: Starting ThriftBinaryCLIService on port 20000 with 5...500 worker threads
2016-10-04T17:50:42,110 INFO [main] webapp.WebInfConfiguration: Extract jar:file:/Users/emerson/apache-hive-2.1.0-odps-proxy/lib/hive-service-2.1.0.jar!/hive-webapps/hiveserver2/ to /private/var/folders/nl/l2z8dnvd51d12nvtwhzzsxjr0000gn/T/jetty-0.0.0.0-10002-hiveserver2-_-any-/webapp
2016-10-04T17:50:42,276 INFO [main] handler.ContextHandler: started o.e.j.w.WebAppContext{/,file:/private/var/folders/nl/l2z8dnvd51d12nvtwhzzsxjr0000gn/T/jetty-0.0.0.0-10002-hiveserver2-_-any-/webapp/},jar:file:/Users/emerson/apache-hive-2.1.0-odps-proxy/lib/hive-service-2.1.0.jar!/hive-webapps/hiveserver2
2016-10-04T17:50:42,311 INFO [main] handler.ContextHandler: started o.e.j.s.ServletContextHandler{/static,jar:file:/Users/emerson/apache-hive-2.1.0-odps-proxy/lib/hive-service-2.1.0.jar!/hive-webapps/static}
2016-10-04T17:50:42,311 INFO [main] handler.ContextHandler: started o.e.j.s.ServletContextHandler{/logs,file:/private/tmp/emerson/}
2016-10-04T17:50:42,336 INFO [main] server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:10002
2016-10-04T17:50:42,338 INFO [main] server.HiveServer2: Web UI has started on port 10002
2016-10-04T17:50:42,338 INFO [main] http.HttpServer: Started HttpServer[hiveserver2] on port 10002
如果所有服务正常启动,没有报任何异常,则表明proxy已经部署成功。
示例1:复用Hive ODBC实现Tableau到MaxCompute的连通
Tableau简介
Tableau是一款商用的BI分析软件,它支持添加各种类型的数据源以供数据分析之用,包括Oracle、MySQL以及Hive等。同时它也提供了丰富酷炫的可视化功能。我们将选择Tableau Desktop来演示其通过HiveServer2是如何与MaxCompute互通的,本次演示的Tableau演示系统是Windows 7。
环境准备
从官网下载Tableau Desktop试用版并进行安装。
打开Tableau后首先需要新建数据源,由于我们需要连接的是HiveServer2,所以需要新建一个连接到Hive的数据源。在Tableau 9.3中,支持三种Hive数据源,分别对接的是来自Cloudera、Hortonworks及MapR的Hive发行版。
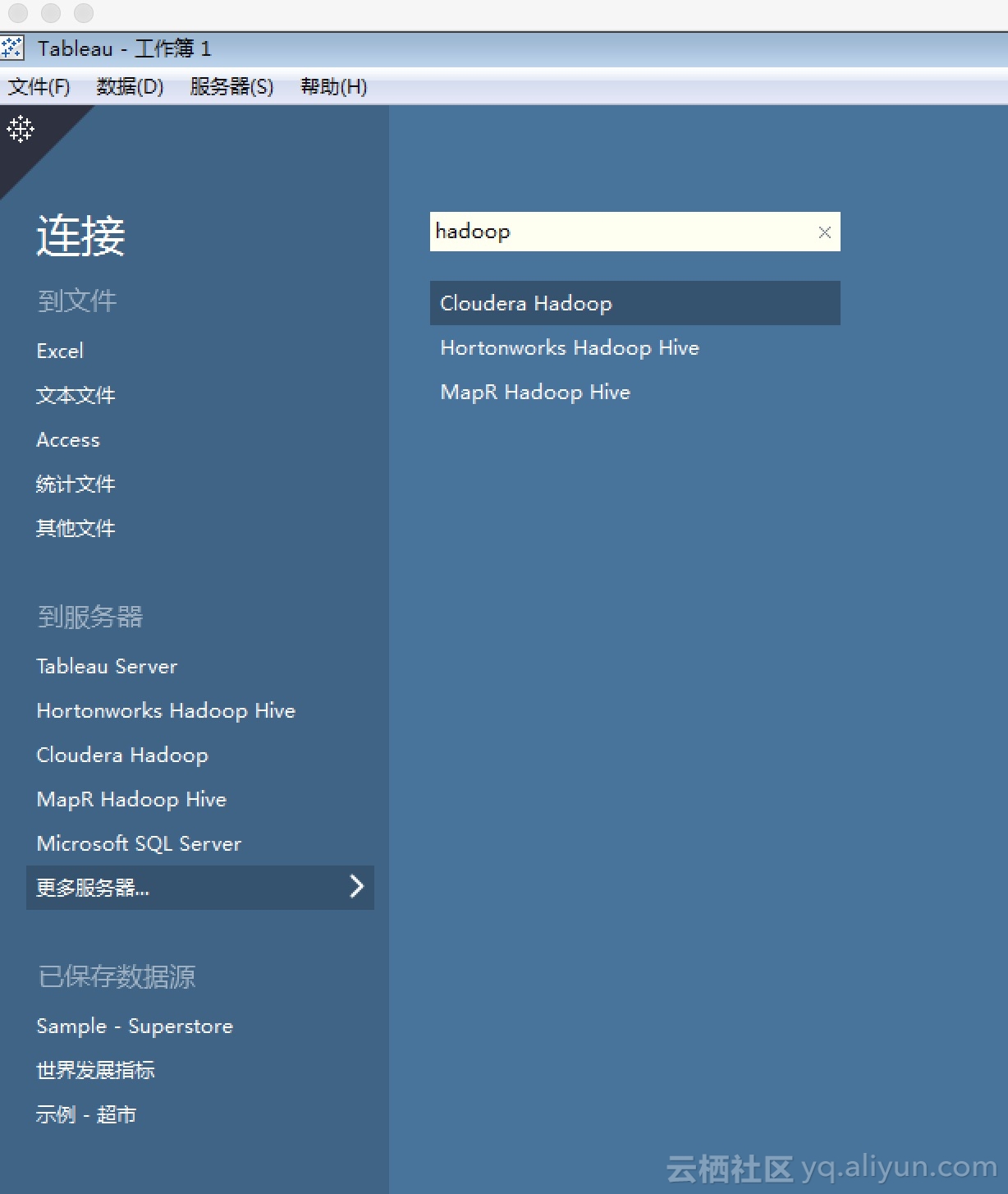
用户可以配置任意一家的Hive数据源来进行尝试,但是请事先安装对应厂商的Hive ODBC驱动。相应的驱动请在Tableau官方的驱动页面查找。下载并安装完Hive ODBC驱动后请重启Tableau,接着我们以Hortonworks Hadoop Hive为例来进行后续的演示。
演示
根据HiveServer2 Proxy所在的IP及配置的端口来完成Hive数据源的配置,如下如图: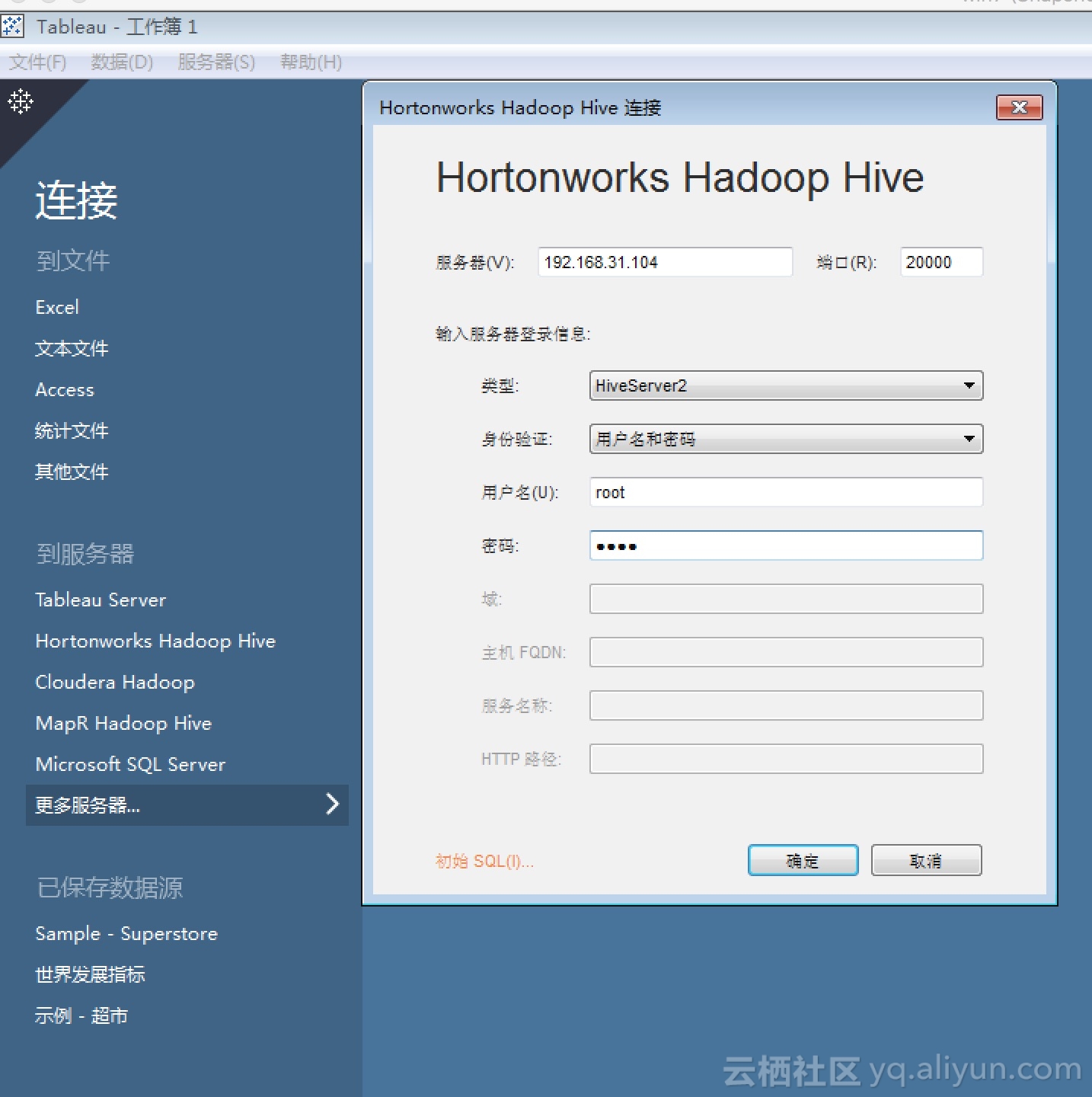
其中“类型“选择HiveServer2,“身份验证”选择用户名密码,“用户名”和“密码”随便填,但是必须要有值,而真正的身份验证走的accessId和accessKey。完成配置后按“确定”按钮。
正常情况下,我们将顺利连接上HiveServer2 Proxy,并进入Tableau的工作簿页面。然后在“架构“处选择我们的project,并点击“放大镜”图标罗列出所有table。如图所示:
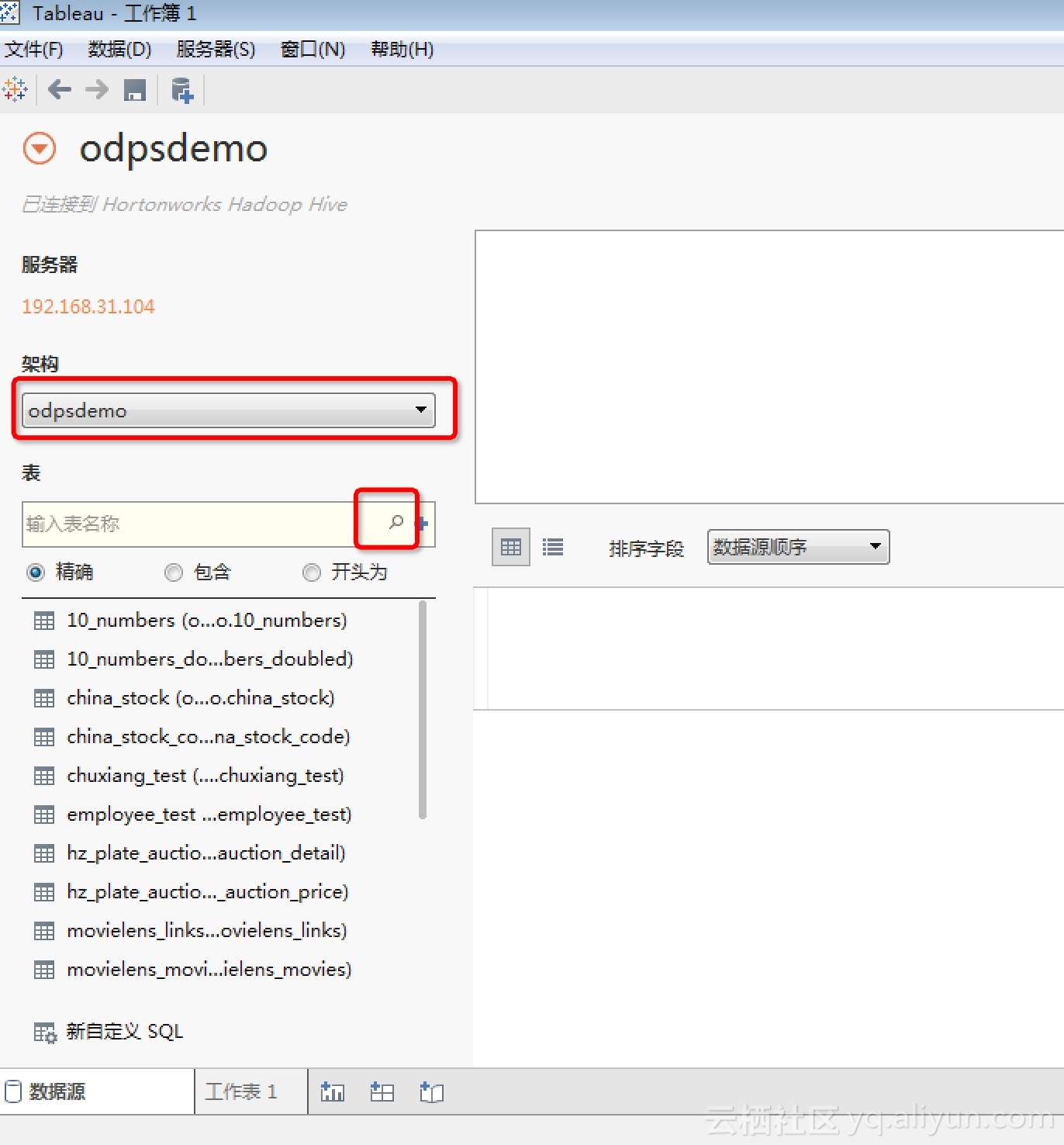
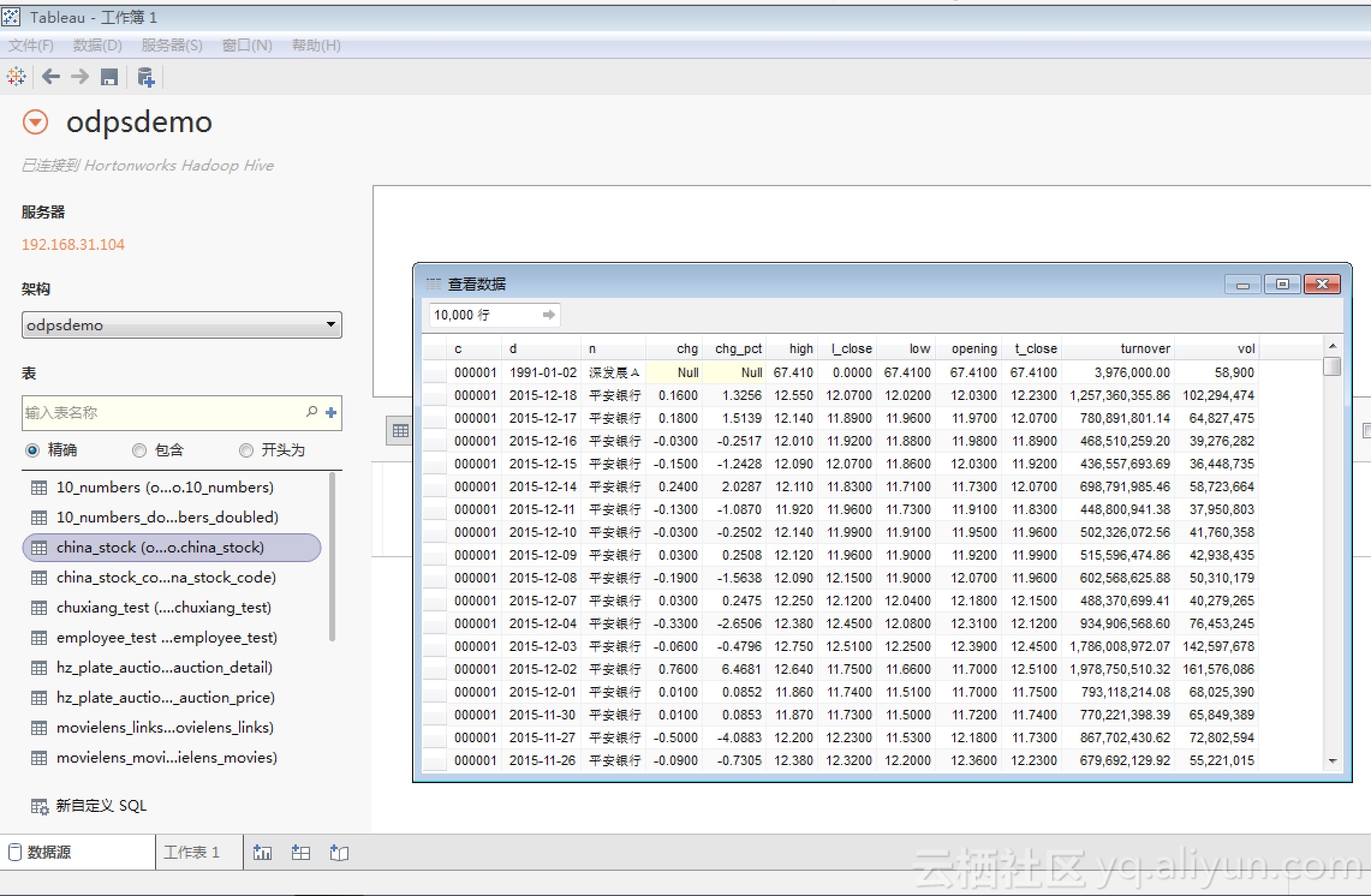
可以选择一张表,并点击表名后的“查看数据”按钮,Tableau就会开始查询数据了:
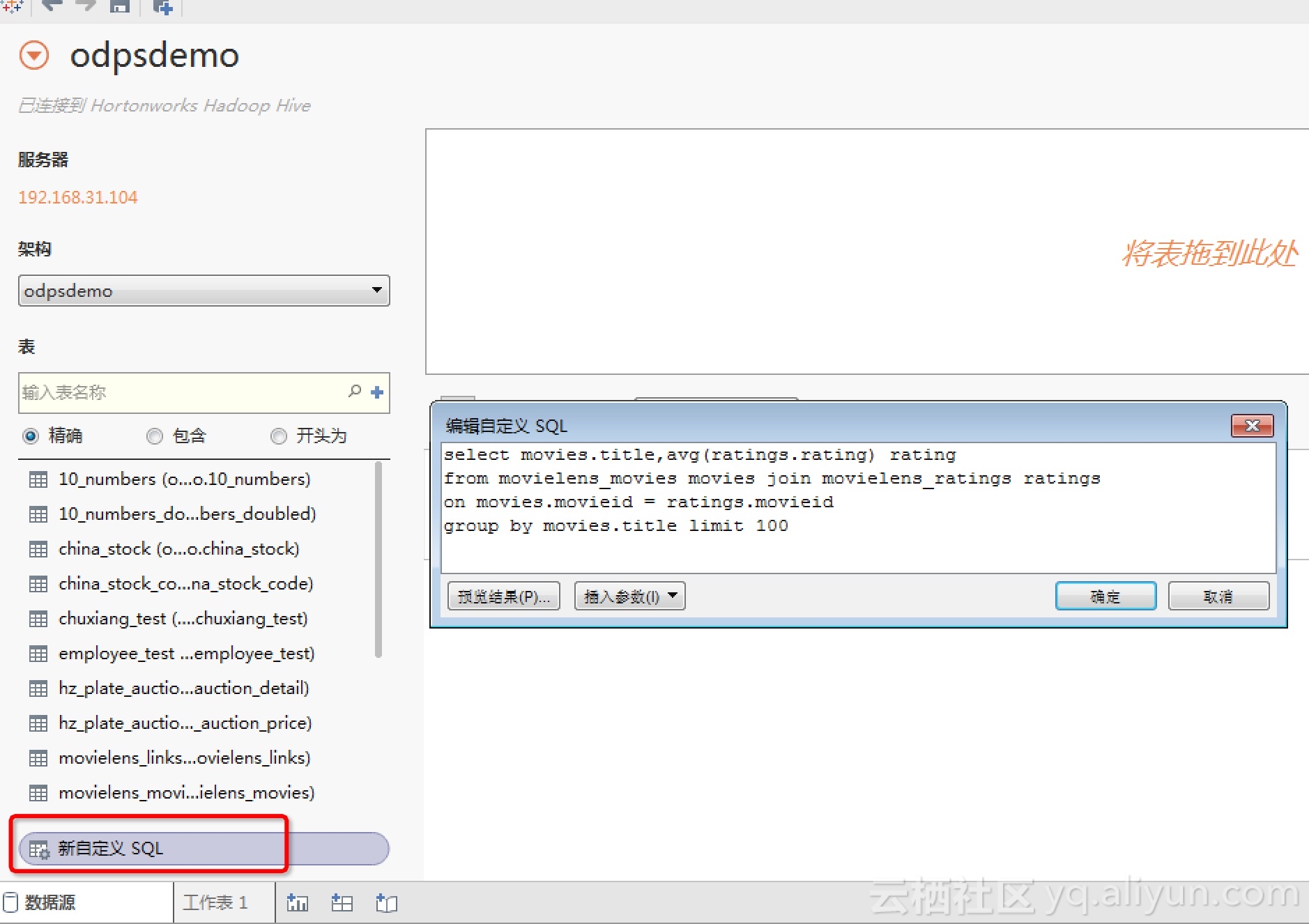
也可以选择“新自定义SQL”,并输入自定义的MaxCompute SQL查询语句,并进而在工作表页面通过“智能显示”来完成数据的可视化处理,如下图所示:
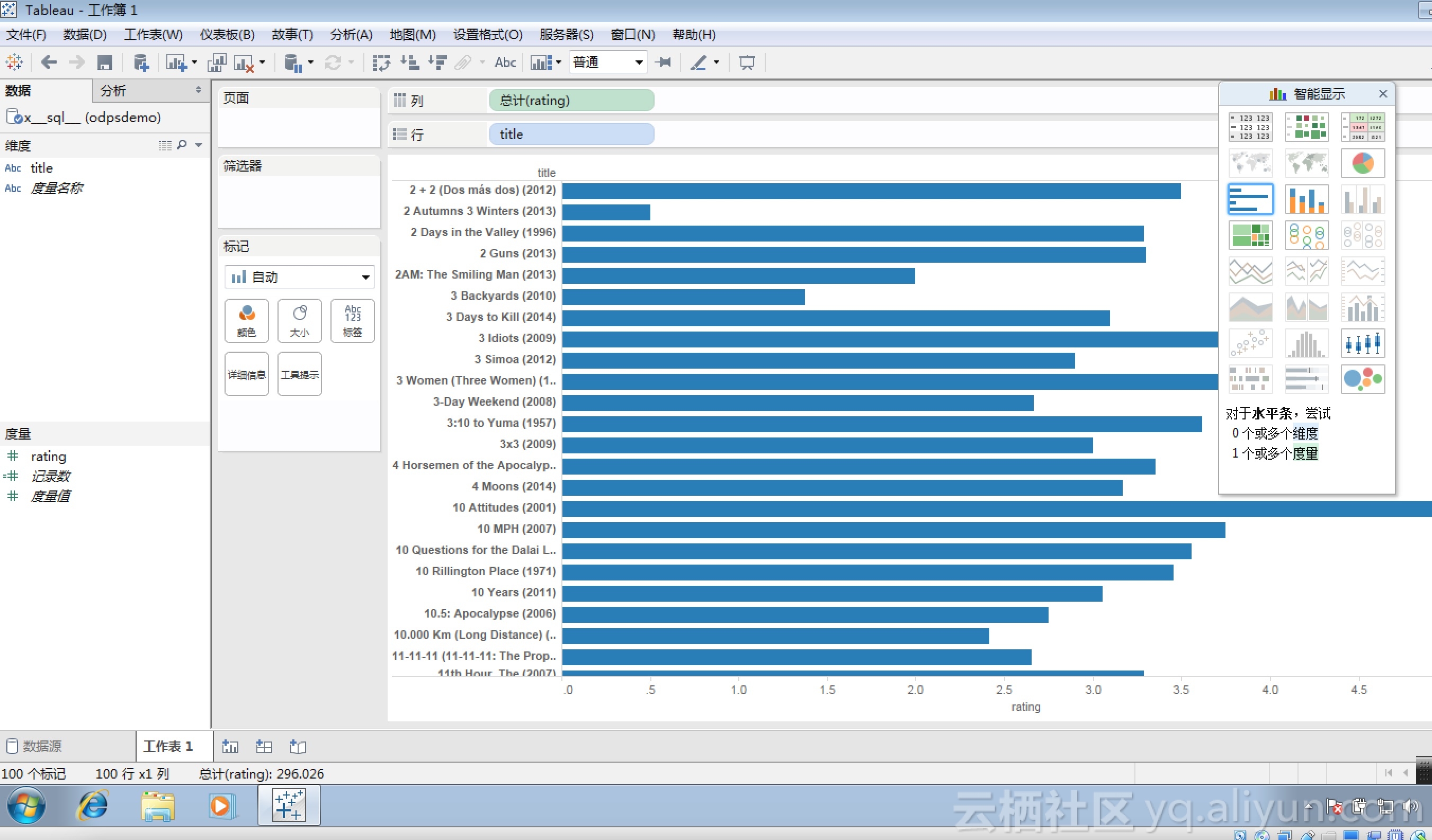
通过以上演示,已经向你展示了通过HiveServer2 Proxy,Tableau可以以Hive数据源的方式通过Hive的ODBC直接连接到MaxCompute,并完成对MaxCompute数据的查询和分析,更多Tableau的功能请访问其官网获取进一步了解。
示例2:复用Hive JDBC实现Beeline到MaxCompute的连通
Beeline简介
Beeline是用以替换Hive CLI的专门针对HiveServer2推出的Hive命令行工具,而其本质上也是一个Hive的JDBC客户端。通过Beeline我们可以完成对Hive的一些基本操作及SQL查询。
环境准备
Hive Beeline是随Hive一起发布的,所以可以使用Hive 2.x以上的发行版来进行尝试。而HiveServer2 Proxy的压缩包里就包含了beeline,我们可以直接使用它来进行演示。
演示
进入Hive的根目录,必要情况下配置HIVE_HOME和HADOOP_HOME环境变量,然后执行如下命令连接HiveServer2 Proxy,请读者自行替换JDBC URL中的相关参数,比如IP、端口以及project名:
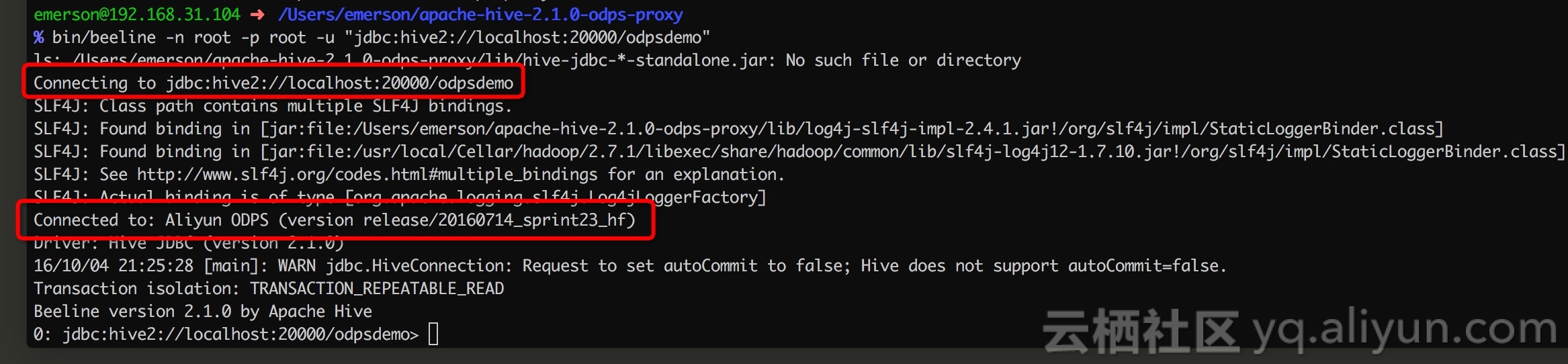
上图显示,我们已经成功连接到MaxCompute的HiveServer2 Proxy。同时,默认project所对应的控制集群的MaxCompute版本也在连接成功的相关信息里打印出来了。
接着,我们便可以指定SQL来进行查询了:
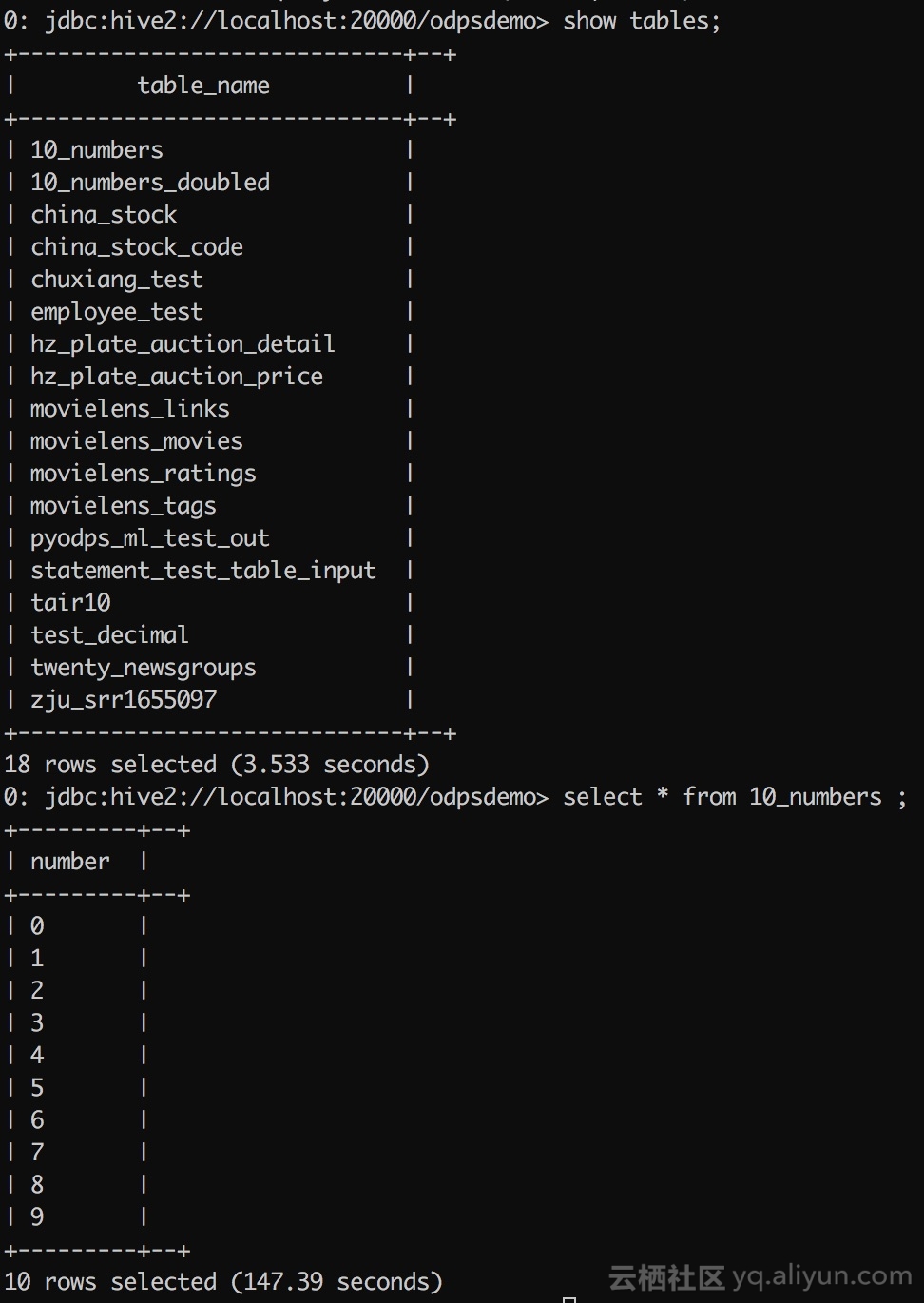
也可以通过set命令来完成对相应flag的设置
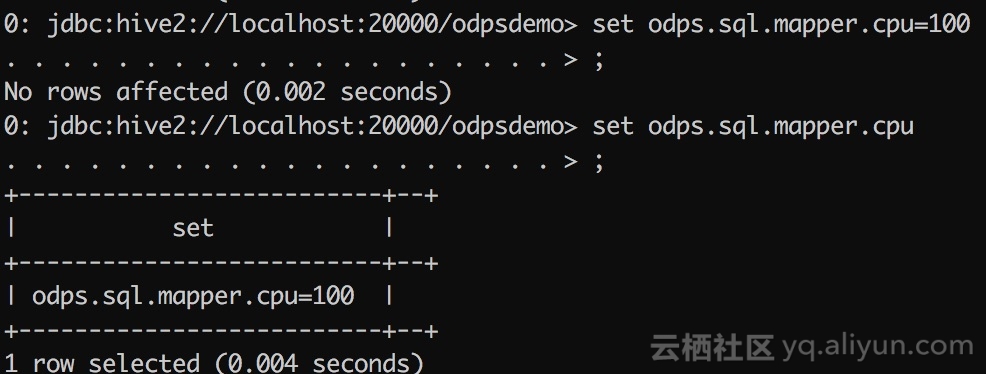
由于Beeline还有部分与资源相关的功能需要分布式文件系统支持,目前这些功能尚未完全实现。
总结
借助于HiveServer2 Proxy,我们可以完成Hive生态的工具与MaxCompute的互通,更多可以玩的可能性等待你去发现。由于目前HiveServer2 Proxy还处于测试阶段,希望大家将发现的问题与期望的需求反馈给我们,以帮助我们更好地完善产品来服务好更多的MaxCompute用户。
欢迎加入MaxCompute钉钉群讨论
![]()