前言
目前Aliyun E-MapReduce支持了Appache Zeppelin和Hue,在Aliyun E-MapReduce集群上可以很方便的使用zeppelin和hue。
Apache Zeppelin是一个提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
准备工作
创建集群
创建集群的时候选择E-MapReduce支持zeppelin和hue主版本。目前E-MapReduce支持Zeppelin和Hue的主版本为1.3.0。创建集群的时候记得设置打开公网ip。
打通ssh无密登录并建立一个SSH隧道
集群创建完成之后,需要建立一个ssh隧道来访问集群的8888和8080端口。详细步骤参考:https://help.aliyun.com/document_detail/28187.html
这里以mac环境为例,使用chrome浏览器实现端口转发(假设集群master节点公网ip为xx.xx.xx.xx):
- a). 登录到master节点
ssh root@xx.xx.xx.xx
输入密码
- b). 查看本机的id_rsa.pub内容(注意在本机执行,不要在远程的master节点上执行)
cat ~/.ssh/id_rsa.pub
- c). 将本机的id_rsa.pub内容写入到远程master节点的~/.ssh/authorized_keys中(在远端master节点上执行)
mkdir ~/.ssh/
vim ~/.ssh/authorized_keys
然后将步骤b)中看到的内容粘贴进来
现在应该可以直接使用ssh root@xx.xx.xx.xx免密登录master节点了。
- d). 在本机执行以下命令进行端口转发
ssh -i ~/.ssh/id_rsa -ND 8157 root@xx.xx.xx.xx
- e). 启动chrome(在本机新开terminal执行)
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --proxy-server="socks5://localhost:8157" --host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" --user-data-dir=/tmp
- f). 在新打开的chrome中访问Zeppelin和Hue
zeppelin: xx.xx.xx.xx:8080
hue: xx.xx.xx.xx:8888
操作步骤和示例
Zepplein
在chrome中访问xx.xx.xx.xx:8080,首先创建一个新的noteboook
一个简单的zeppelin示例
- 支持markdown语法
%md
## Welcome to Aliyun E-MapReduce. This is a Zeppelin sample.
##### This is a live tutorial, you can run the code yourself. (Shift-Enter to Run)

- 原生支持scala。使用scala进行load数据
import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
// Zeppelin creates and injects sc (SparkContext) and sqlContext (HiveContext or SqlContext)
// So you don't need create them manually
// load bank data
val bankText = sc.parallelize(
IOUtils.toString(
new URL("http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/bank.csv"),
Charset.forName("utf8")).split("\n"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")

- 使用spark sql查询和展示结果
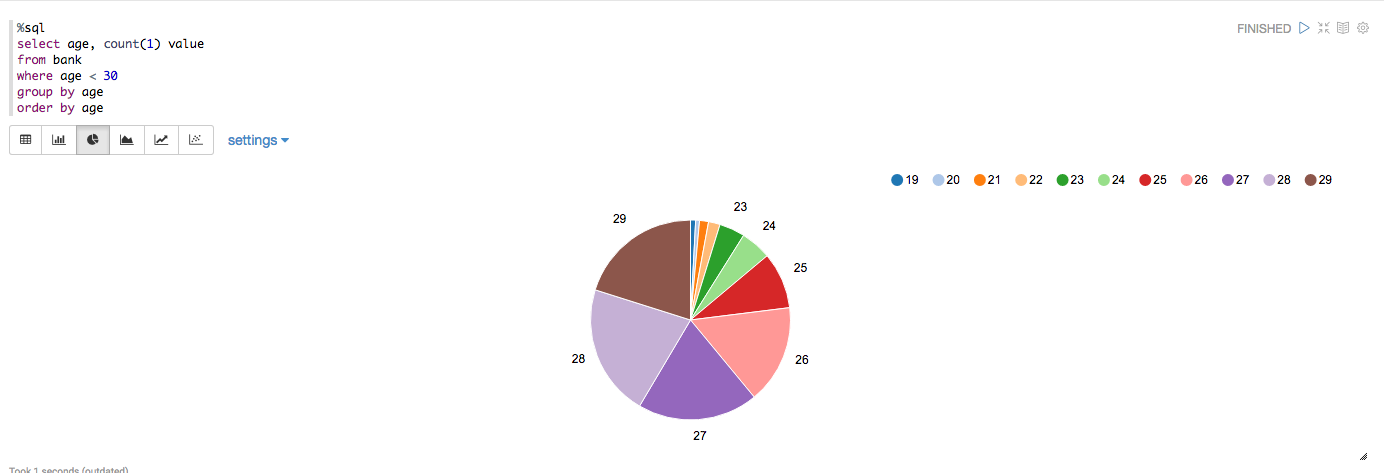
%sql
select age, count(1) value
from bank
where age < 30
group by age
order by age
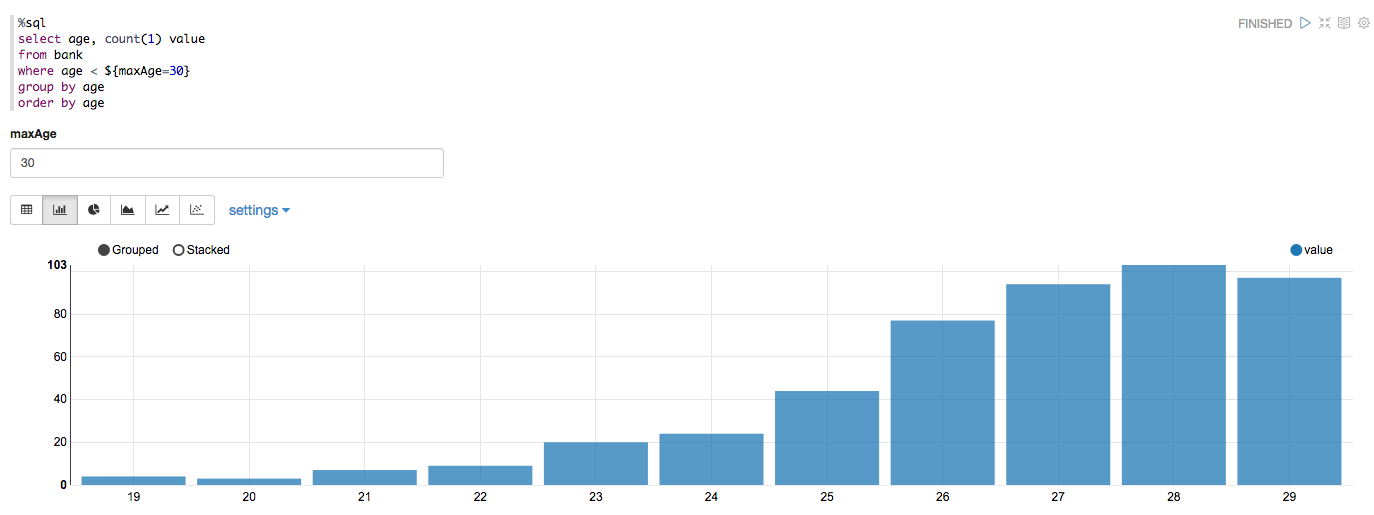
%sql
select age, count(1) value
from bank
where age < ${maxAge=30}
group by age
order by age
%sql
select age, count(1) value
from bank
where marital="${marital=single,single|divorced|married}"
group by age
order by age

zeppelin 运行shell示例
%sh
cd /tmp
wget http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/bank.csv
ls -la
rm bank.csv
ls -la
su -l hadoop -c "hadoop dfs -ls /"
zeppelin上运行hive sql示例
- Download Spending Dataset into HDFS
%sh
#remove existing copies of dataset from HDFS
su -l hadoop -c "hadoop fs -rm /tmp/expenses.csv"
#fetch the dataset
wget http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/healthexpenditurebyareaandsource.csv -O /tmp/expenses.csv
#remove header
sed -i '1d' /tmp/expenses.csv
#remove empty fields
sed -i "s/,,,,,//g" /tmp/expenses.csv
sed -i '/^\s*$/d' /tmp/expenses.csv
#put data into HDFS
su -l hadoop -c "hadoop fs -put /tmp/expenses.csv /tmp"
su -l hadoop -c "hadoop fs -ls -h /tmp/expenses.csv"
rm /tmp/expenses.csv
%hive
drop table if exists `health_table`
- Create Hive table
%hive
CREATE TABLE `health_table` (
`year` string ,
`state` string ,
`category` string ,
`funding_src1` string,
`funding_src2` string,
`spending` int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TextFile
- Load dataset into Hive table
%hive
load data
inpath '/tmp/expenses.csv'
into table health_table
- Grant permissions
%hive
select count(*) from health_table
- Spending (In Billions) By State
%hive
select state, sum(spending)/1000 SpendinginBillions
from health_table
group by state
order by SpendinginBillions desc
- Spending (In Billions) By Year
%hive
select year,sum(spending)/1000 SpendinginBillions
from health_table
group by year
order by SpendinginBillions
- Spending (In Billions) By Category
%hive
select category, sum(spending)/1000 SpendinginBillions from health_table
group by category
order by SpendinginBillions desc
zeppelin notebook json配置
zeppelin的每个notebook都是可以保存、导入和导出的。上面的三个示例,可以通过下载json配置直接导入。
zeppelin插图
zeppelin中的插图,都可以进行复制和保存: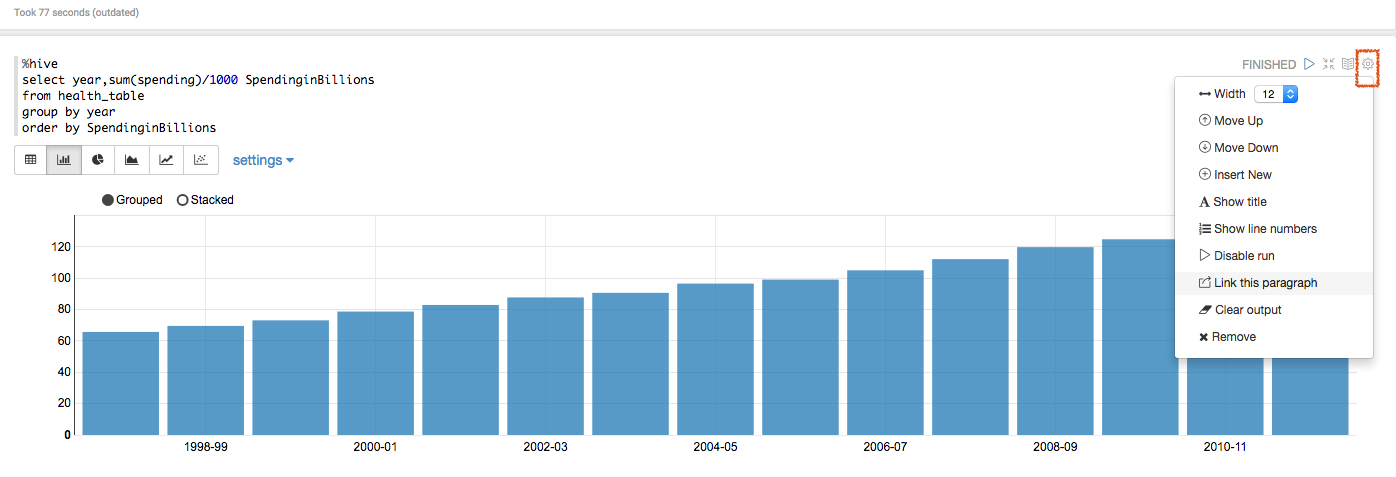
Hue
通过xx.xx.xx.xx:8888访问Hue。第一次登陆hue的时候,需要设置一个管理员账户和密码。请慎重设置和保管你的Hue管理员账户和密码信息。
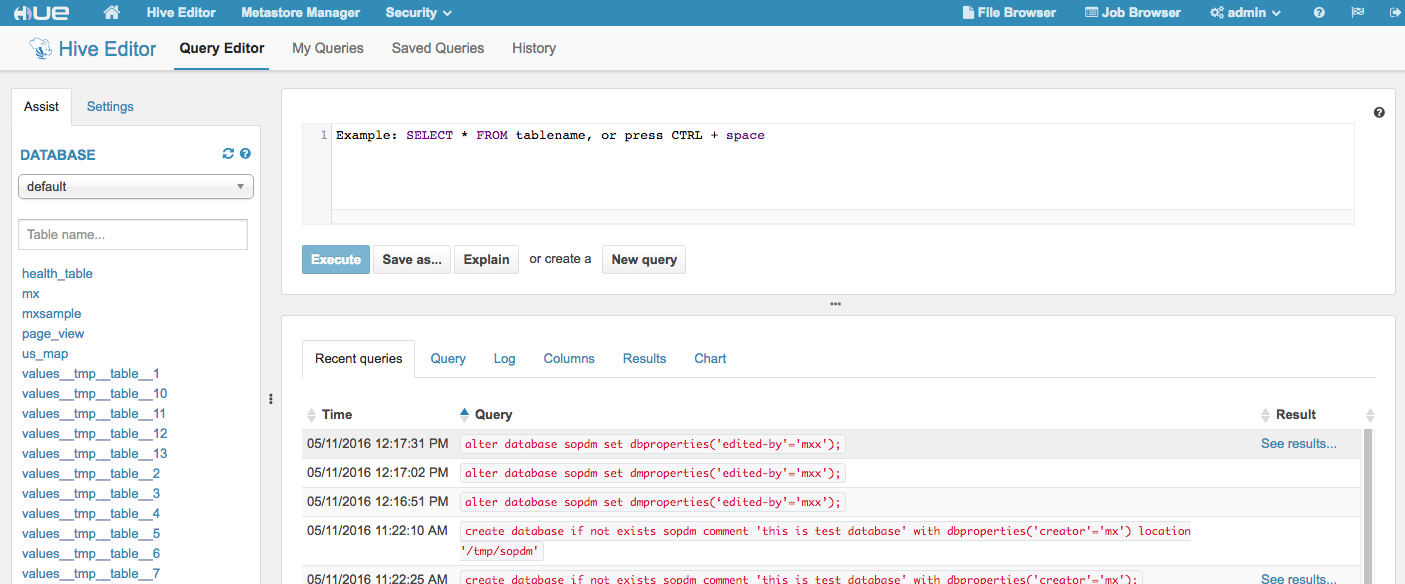
Hive Editor
通过Hive Editor可以进行hive sql的编写和交互式运行。在左边栏DATABASE中会展示当前的数据库和表信息。
Metastore Manager
通过Metastore Manager可以查看和管理hive表,可以可视化创建表。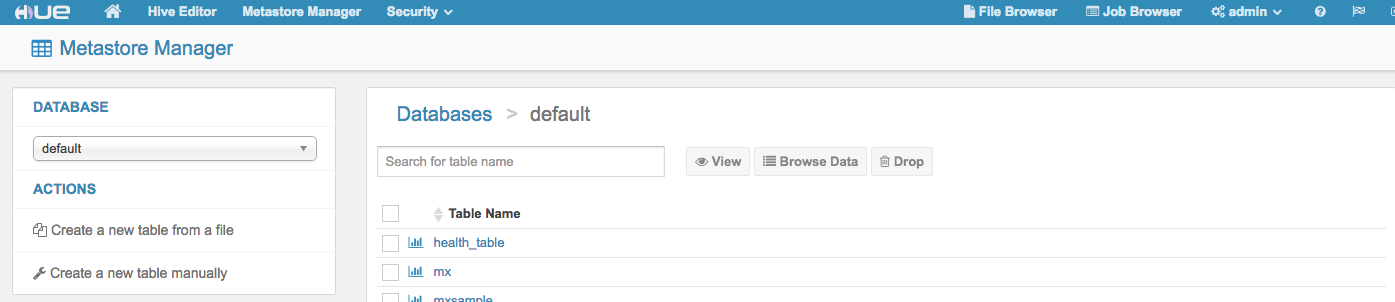
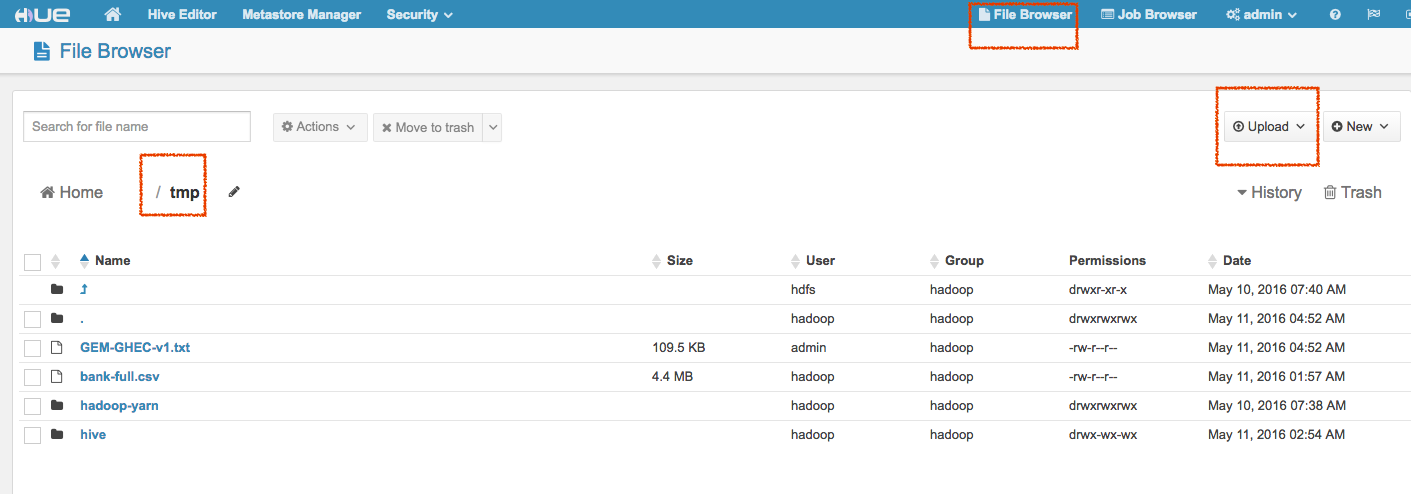
File Browser
通过File Browser可以查看和管理到hdfs上的文件。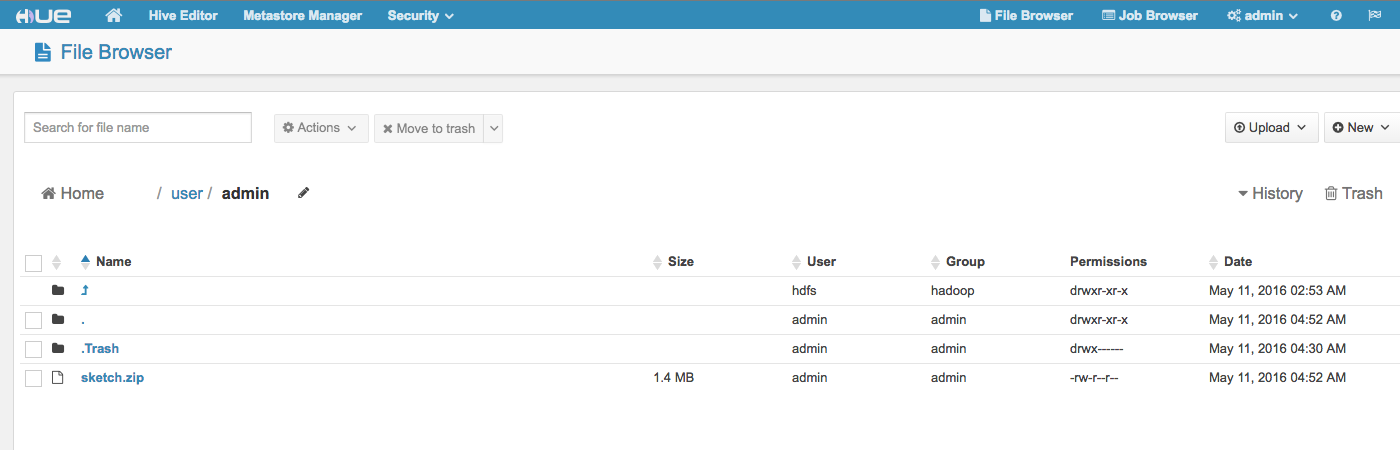
示例代码
这里展示一个通过hue metastore界面从文件建表的过程,并通过Hive Editor对表中的数据做查询和展示的例子。
首先,下载数据文件到master节点,并且将该文件放入hdfs的/tmp目录下。可以ssh到master节点上操作,也可以直接使用zepplein的shell notebook。
有三种方式可以实现将数据文件放在hdfs的/tmp目录下:
- 1) 直接ssh登录到master节点上:
ssh root@xx.xx.xx.xx
cd /tmp
wget http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/us_map.csv
su -l hadoop -c "hadoop fs -put /tmp/us_map.csv /tmp/us_map.csv"
su -l hadoop -c "hadoop fs -ls -h /tmp/us_map.csv"
- 2) 这直接使用zeppelin的shell notebook操作:
%sh
cd /tmp
wget http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/us_map.csv

%sh
su -l hadoop -c "hadoop fs -put /tmp/us_map.csv /tmp/us_map.csv"

%sh
su -l hadoop -c "hadoop fs -ls -h /tmp/us_map.csv"

- 3) 通过Hue的file browser上传
通过hue的Metastore manager创建表。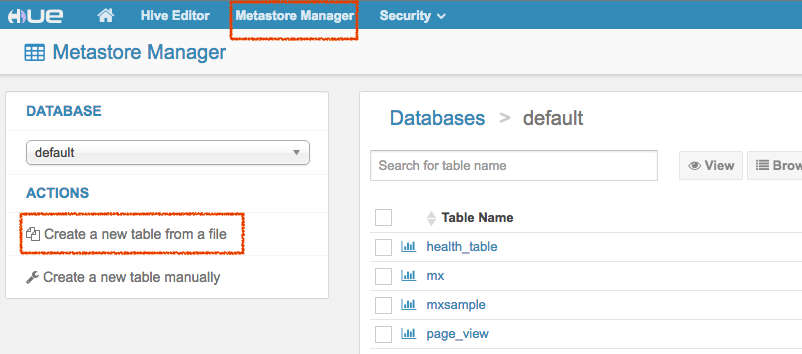
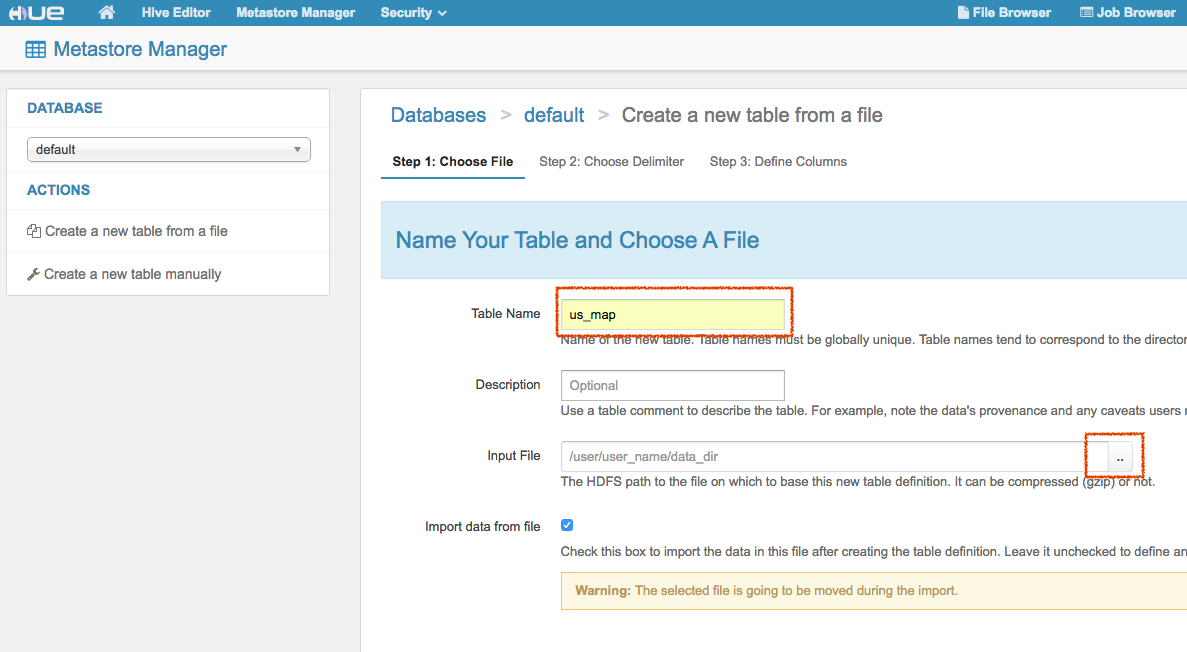
然后一路next直到最后create table完成建表。刷新Query Editor界面在左侧的DATABASE导航栏可以看到新建的表。
在Hive Editor中执行
select * from us_map
